부분관측 환경에서의 오프‑정책 평가: 새로운 이론과 실험
본 논문은 부분관측 마코프 결정 과정(POMDP)에서 배치 오프‑정책 평가(OPE)의 이론적 한계를 규명하고, 관측 변수와 비관측 변수를 분리한 “Decoupled POMDP” 모델을 제안한다. 기존 Importance Sampling이 초래할 수 있는 무한대 편향을 보완하기 위해, 과거·미래 관측을 활용한 가중치 행렬의 가역성 조건 하에 편향 없는 평가식을 도출한다. 합성 의료 데이터 실험을 통해 제안 방법의 실효성을 입증한다.
저자: Guy Tennenholtz, Shie Mannor, Uri Shalit
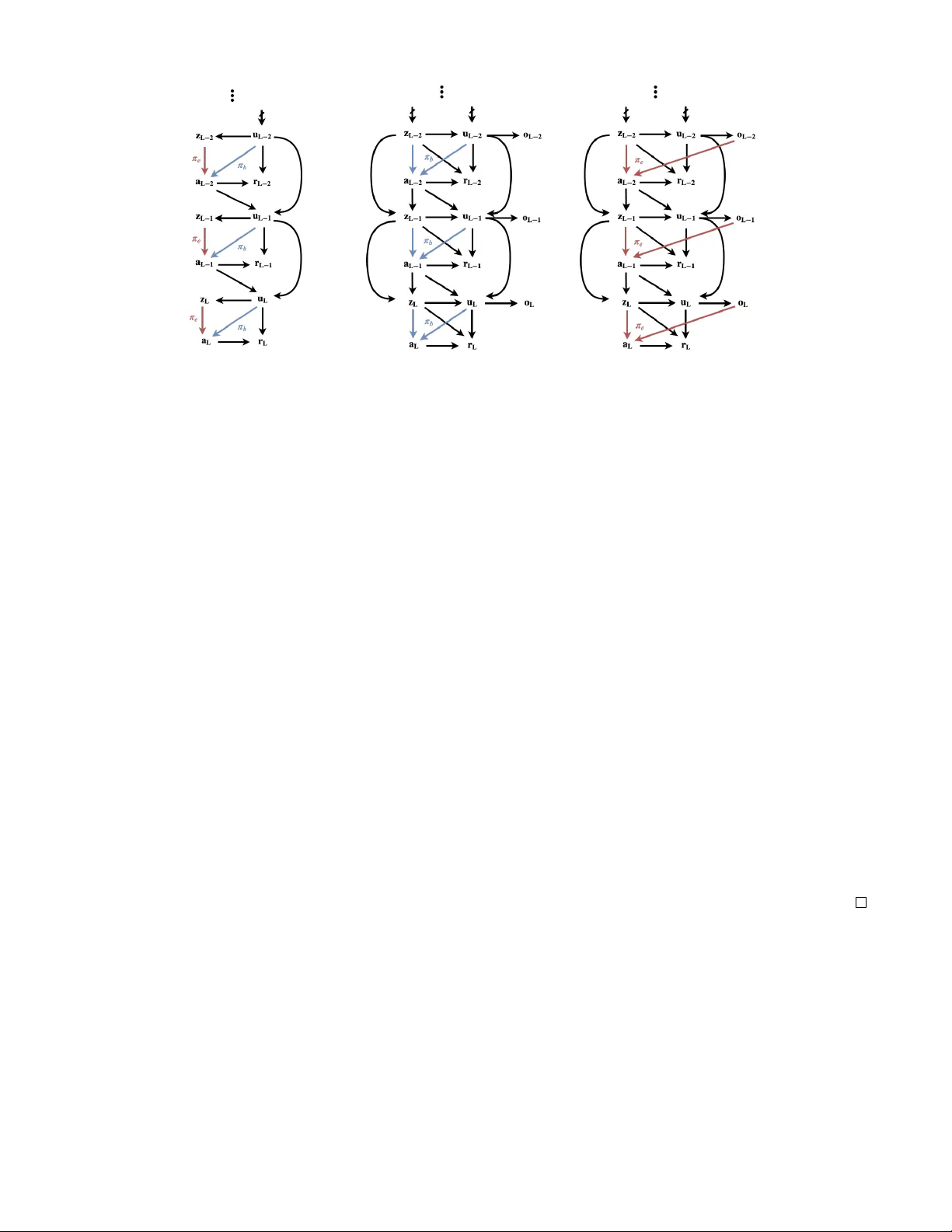
본 논문은 부분관측 마코프 결정 과정(POMDP)에서 배치 오프‑정책 평가(OPE)의 근본적인 어려움을 규명하고, 이를 해결하기 위한 새로운 이론적 프레임워크와 모델을 제시한다.
1. **문제 정의 및 동기**
- 기존 OPE 연구는 완전관측 MDP를 전제로 하며, 행동 정책과 평가 정책 모두가 완전한 상태 정보를 이용한다. 그러나 실제 의료, 자율주행 등에서는 에이전트가 내부 상태(예: 환자의 사회경제적 배경, 운전자의 피로도)를 활용하지만, 학습자는 오직 관측 히스토리만을 볼 수 있다. 이러한 숨은 상태는 행동과 보상 모두에 영향을 미치는 ‘confounder’ 역할을 하여, 전통적인 Importance Sampling 등 OPE 방법이 큰 편향을 발생시킨다.
2. **POMDP에 대한 OPE 이론 (정리 1)**
- 저자들은 POMDP를 (U, A, Z, P, O, r, γ) 로 정의하고, 행동 정책 π_b는 숨은 상태 U에 의존, 평가 정책 π_e는 관측 히스토리 h_o에 의존하도록 설정한다.
- 핵심 아이디어는 과거 관측 Z_{i‑1}와 미래 관측 Z_i를 각각 숨은 상태 U_i의 두 독립적인 ‘뷰’로 활용하는 것이다. 각 시점 i에 대해 조건부 확률 행렬 P_b(Z_i|a_i, Z_{i‑1})가 가역이면, 가중치 행렬 W_i = P_b(Z_i|a_i, Z_{i‑1})^{-1}·P_b(Z_i, Z_{i‑1}|a_{i‑1}, Z_{i‑2}) 를 정의할 수 있다.
- 정의된 Π_e(τ_o)=∏_{i=0}^t π_e(a_i|h_{o,i}) 와 Ω(τ_o)=∏_{i=0}^t W_{t‑i}(τ_o) 를 이용해, 행동 정책의 관측 분포 P_b만으로 평가 정책의 기대 보상 P_e(r_t) = Σ_{τ_o} Π_e(τ_o)·P_b(r_t, z_t|a_t, Z_{t‑1})·Ω(τ_o) 를 정확히 계산한다.
- 이 결과는 |Z|≥|U|와 모든 행동에 대해 위 행렬이 가역이라는 비특이성 가정 하에 성립한다. 즉, 관측이 충분히 풍부하면 숨은 상태를 직접 관측하지 않아도 편향 없는 정책 평가가 가능함을 보인다.
3. **Decoupled POMDP 모델**
- 일반 POMDP에서는 관측 Z가 숨은 상태 U에 직접 종속되어 있어, 큰 차원의 행렬을 추정해야 하는 실용적 어려움이 있다. 이를 해결하기 위해 ‘Decoupled POMDP’를 정의한다.
- 상태를 (Z, U) 로 명시적으로 분리하고, 각각 독립적인 전이 커널 P(z',u'|z,u,a) 를 갖는다. 또한 U는 별도의 관측 O를 생성하는 독립 관측 함수 P_O(o|u) 를 가진다. 이렇게 하면 관측 Z와 O가 각각 U에 대한 프록시 역할을 하며, 두 프록시 간의 조건부 확률 행렬이 가역이면 OPE가 가능해진다.
- 정리 2에서는 |O|·|Z|가 |U|보다 충분히 크고, P(O|U)·P(Z|U) 가 가역이면, 행동 정책의 관측 분포만으로 평가 정책의 기대 보상을 정확히 추정할 수 있음을 증명한다. 이때 필요한 행렬은 U의 차원에 비례하므로, 일반 POMDP 대비 샘플 복잡도가 크게 감소한다.
4. **전통 OPE 방법의 실패와 Importance Sampling 변형**
- 저자들은 Importance Sampling(IS) 을 POMDP에 직접 적용하면, 숨은 상태가 행동과 보상에 동시에 영향을 주기 때문에 가중치가 무한히 커지는 경우가 발생한다. 이는 “무한대 편향”이라 부른다.
- 이를 완화하기 위해 보상 구조에 대한 추가 가정(예: 보상이 관측 Z에만 의존) 하에 IS 가중치를 재정의하는 변형을 제시했지만, 실험 결과 여전히 큰 편향을 보였다.
5. **실험**
- 합성 의료 데이터 시나리오를 구축하였다. 행동 정책은 환자의 관측 기록(Z)과 숨은 사회경제적 요인(U)를 이용해 약물 선택을 하고, 보상은 치료 성공 여부이다. 평가 정책은 전자 의료 기록만을 이용한다.
- 전통 IS 기반 OPE는 실제 보상보다 크게 과대평가하거나 과소평가하는 편향을 보였으며, 분산도 크게 나타났다. 반면, Decoupled POMDP 기반 방법은 거의 편향이 없고, 추정 분산도 낮았다.
6. **의의 및 향후 연구**
- 이 논문은 POMDP에서 OPE가 왜 어려운지를 인과 추론 관점에서 명확히 설명하고, 관측·비관측 변수를 구조적으로 분리한 모델을 통해 실용적인 해결책을 제공한다.
- 제안된 프레임워크는 의료, 자율주행, 로봇 등 숨은 변수가 존재하지만 직접 관측이 불가능한 도메인에서 안전한 정책 평가와 정책 개선에 직접 활용될 수 있다.
- 향후 연구는 실제 대규모 데이터에 대한 확장, 연속 상태·행동 공간에 대한 일반화, 그리고 비정형 관측(예: 이미지)과의 결합을 탐색할 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기