기록 연결의 확률적 방법 재검토
본 논문은 기존 확률적 기록 연결 방법이 조건부 독립 가정이나 식별 불가능한 로그선형 모델 때문에 실무에서 기대에 못 미치는 문제를 지적한다. 이를 해결하기 위해 각 레코드의 이웃 수(유사 레코드 수)를 모델링하는 새로운 유한 혼합 모델을 제안한다. 각 혼합 성분은 베르누이 변수와 독립 포아송 변수의 합으로 구성되며, 식별성(property)을 보장한다. 이 모델은 블로킹 기준 평가, 오류율 추정, 비확률적 연결 방법의 성능 측정 등을 사전 검…
저자: Abel Dasylva, Arthur Goussanou, David Ajavon
본 논문은 50년 전 Fellegi‑Sunter가 제시한 확률적 기록 연결 이론을 재조명하고, 현대 대규모 행정 데이터 환경에서 발생하는 실질적 문제들을 해결하기 위한 새로운 통계 모델을 제안한다.
1. **배경 및 문제점**
- 확률적 기록 연결은 두 레코드가 동일 인물인지 여부를 판단하기 위해 비교 변수들의 가중합을 이용한다. 이때 매치와 비매치를 구분하는 임계값을 설정함으로써 Type I(오탐)와 Type II(누락) 오류를 동시에 최소화하고, 두 오류율을 자동으로 추정할 수 있다는 장점이 있다.
- 기존 구현은 주로 조건부 독립 가정(CIA) 하에 로그선형 혼합 모델을 사용한다. 실제 사회 데이터에서는 변수 간 상관관계가 강해 CIA가 위배되고, 이로 인해 매치 확률 추정이 편향된다.
- 상호작용을 포함한 로그선형 모델을 도입하면 상관을 반영할 수 있으나, 파라미터 수가 급증해 식별성(property)이 보장되지 않는다. 즉, 관측된 데이터만으로는 모델 파라미터를 고유하게 추정할 수 없으며, 오류율 추정이 불안정해진다.
- 블로킹(blocking)은 대규모 파일을 효율적으로 연결하기 위한 전처리 단계이지만, 블로킹으로 인해 발생하는 False Negative(매치 누락) 비율을 정확히 측정하기 어렵다. 기존의 캡처‑리캡처 방법은 두 개 이상의 독립적인 블로킹 키가 필요하지만, 실제 데이터에서는 이러한 조건을 만족하기 힘들다.
2. **새로운 개념: 이웃수와 적절한 연결 문제**
- 저자는 각 레코드 v_i에 대해 이웃 집합 B_N(v_i)를 정의한다. 이 집합은 블로킹 기준, 비교 결과, 혹은 비확률적 매핑 L에 의해 결정된다.
- 이웃 수 n_i는 매치 이웃 n_i|M(베르누이 변수)과 비매치 이웃 n_i|U(포아송 변수)의 합으로 표현된다.
- ‘적절한 연결 문제(proper linkage problem)’는 다음 두 조건을 만족하는 경우이다: (i) 모든 레코드에 대해 매치 이웃 존재 확률 p_N(v) ≥ δ > 0, (ii) 비매치 이웃 기대값 (N‑1)λ_N(v) ≤ Λ (상수). 이 조건은 인구 규모 N이 커져도 매치 레코드가 일정 확률 이상으로 식별 가능함을 보장한다.
3. **모델 설계**
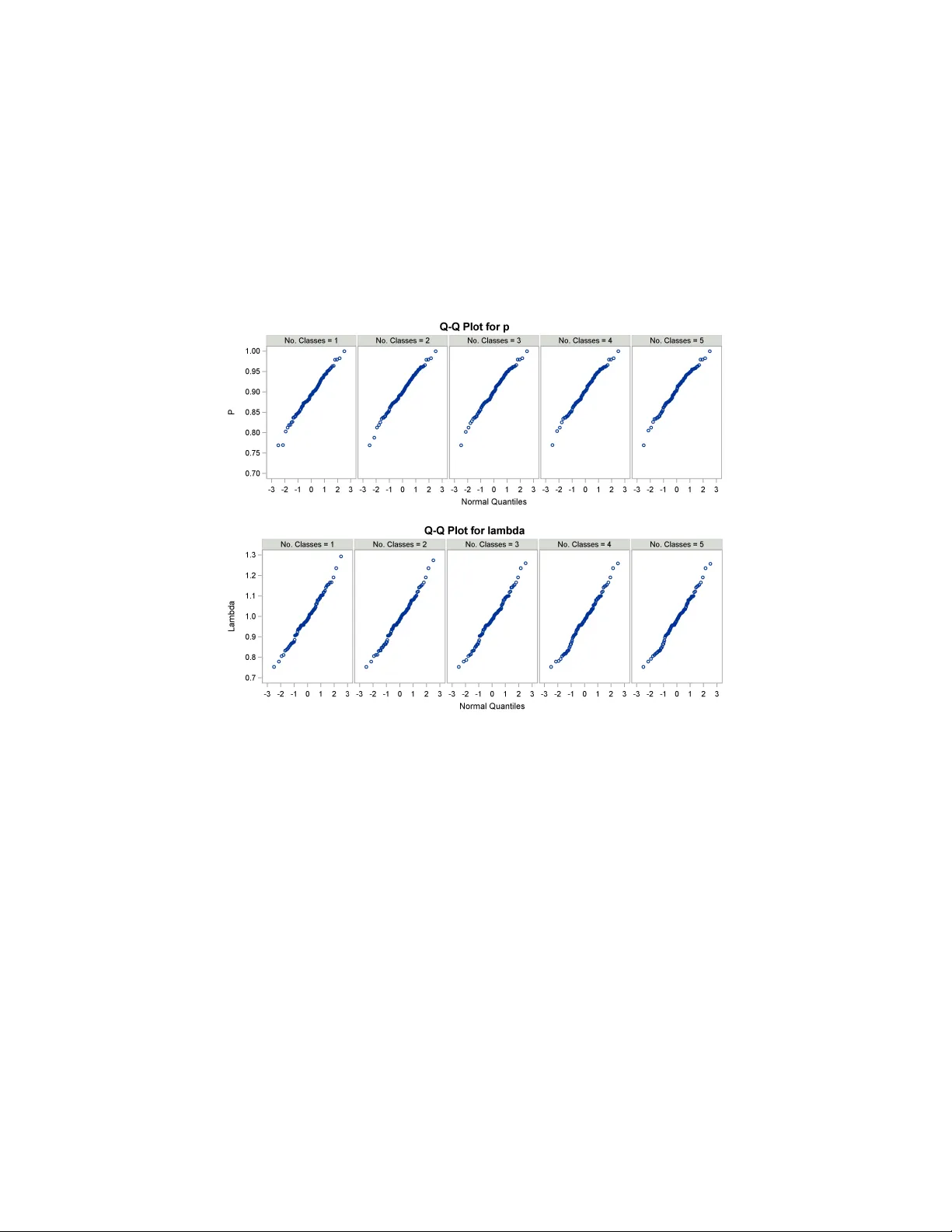
- (p, λ)라는 두 확률 변수의 결합분포 F(p,λ)를 도입한다. p는 매치 이웃이 존재할 확률(m‑probability), λ는 비매치 이웃이 존재할 확률(u‑probability)이다.
- 각 레코드의 이웃 수 n_i는 다음 혼합 모델을 따른다: n_i = Bernoulli(p) + Poisson(λ). 이는 유한 혼합 모델이며, 각 성분이 독립적이므로 식별성이 보장된다.
- EM 알고리즘을 사용해 관측된 이웃 수 분포로부터 (p, λ)의 모멘트 추정치를 얻는다. 구체적으로 E‑step에서는 현재 파라미터 하에 각 관측 n_i가 매치 이웃에 기인했는지의 기대값을 계산하고, M‑step에서는 이를 이용해 p와 λ를 업데이트한다.
4. **오류율 및 가중치 계산**
- 추정된 E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기