단일 채널 스피커 수 추정: 분류와 회귀의 최적 설계
본 논문은 단일 마이크 입력에서 동시에 말하는 화자 수(k)를 추정하기 위해, 출력 형태를 분류, 가우시안 회귀, 포아송 회귀 세 가지로 설정하고 BLSTM 기반 딥러닝 모델을 비교한다. 다양한 시간‑주파수 입력(MEL, MFCC, STFT, 로그‑STFT) 중 STFT가 가장 낮은 평균 절대 오차(MAE)를 보였으며, 특히 분류 방식이 가장 정확했다. 합성 데이터와 실제 음성 데이터로 검증한 결과, 5초 길이의 혼합 음성에서 최대 10명까지의…
저자: Fabian-Robert St"oter, Soumitro Chakrabarty, Bernd Edler
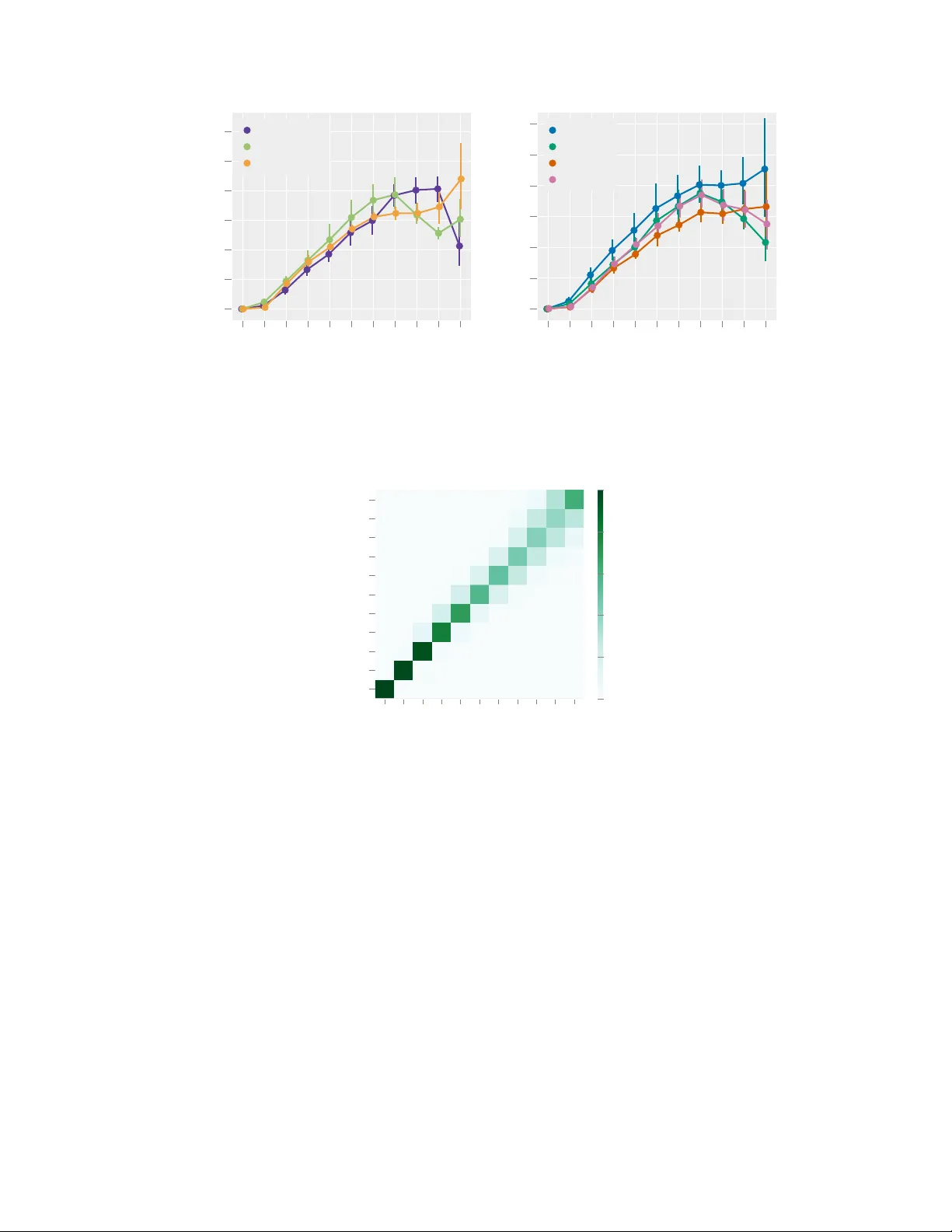
본 논문은 단일 마이크 입력에서 동시에 말하고 있는 화자 수(k)를 자동으로 추정하는 방법을 제안하고, 이를 구현하기 위한 딥러닝 모델 설계와 실험적 검증을 전반적으로 다룬다. 연구 배경으로는 “칵테일 파티” 상황에서 화자 수가 사전 정보로 주어지지 않을 경우, 후속 처리(소스 분리, 화자 다이어리제이션 등)의 성능이 크게 저하된다는 점을 들었다. 기존 연구는 화자 검출 후 카운팅하거나, 다중 채널에서 DoA(방향) 기반 클러스터링을 이용하는 방식이 주를 이루었으며, 단일 채널에서 완전 겹침된 음성을 대상으로 한 직접 카운팅 방법은 거의 없었다.
문제 정의는 입력 신호 x(시간 도메인) 혹은 그에 대응하는 비음수 시간‑주파수 매트릭스 X∈ℝ^{D×F}를 받아, 최대 동시 화자 수 k∈ℕ₀를 예측하는 함수 f_θ를 학습하는 것으로 설정한다. 여기서 k는 각 프레임 n에 대한 화자 활성화 변수 v_{nl}∈{0,1}의 합의 최대값으로 정의된다(k = max_n Σ_l v_{nl}).
출력 설계는 세 가지 접근법으로 나뉜다. ① **분류(Classification)** – k = 0 ~ k_max까지의 (k_max + 1) 클래스를 소프트맥스 출력으로 예측하고, MAP(가장 높은 확률)로 최종 추정한다. 장점은 확률적 해석이 직관적이며 구현이 간단하지만, 클래스 간 순서(예: 5와 6 사이의 관계)가 반영되지 않는다. ② **가우시안 회귀(Gaussian Regression)** – 네트워크는 실수값을 출력하고, 손실은 MSE이며, 추정값은 반올림(
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기