제어 가능한 주의 메커니즘을 통한 구조화된 레이어 비디오 분해
본 논문은 비디오를 자연스러운 레이어(반사, 투명, 움직이는 객체 등)로 분리하고, 외부 신호(주로 오디오)를 이용해 원하는 레이어에 선택적으로 주의를 집중할 수 있는 새로운 신경망 구조인 C³(Controllable Compositional Centrifuge)를 제안한다. 레이어 마스크를 명시적으로 모델에 포함하고, 합성 계수를 통해 레이어를 재구성함으로써 기존 방법보다 분리 품질과 제어 가능성을 동시에 향상시킨다.
저자: Jean-Baptiste Alayrac, Jo~ao Carreira, Relja Ar
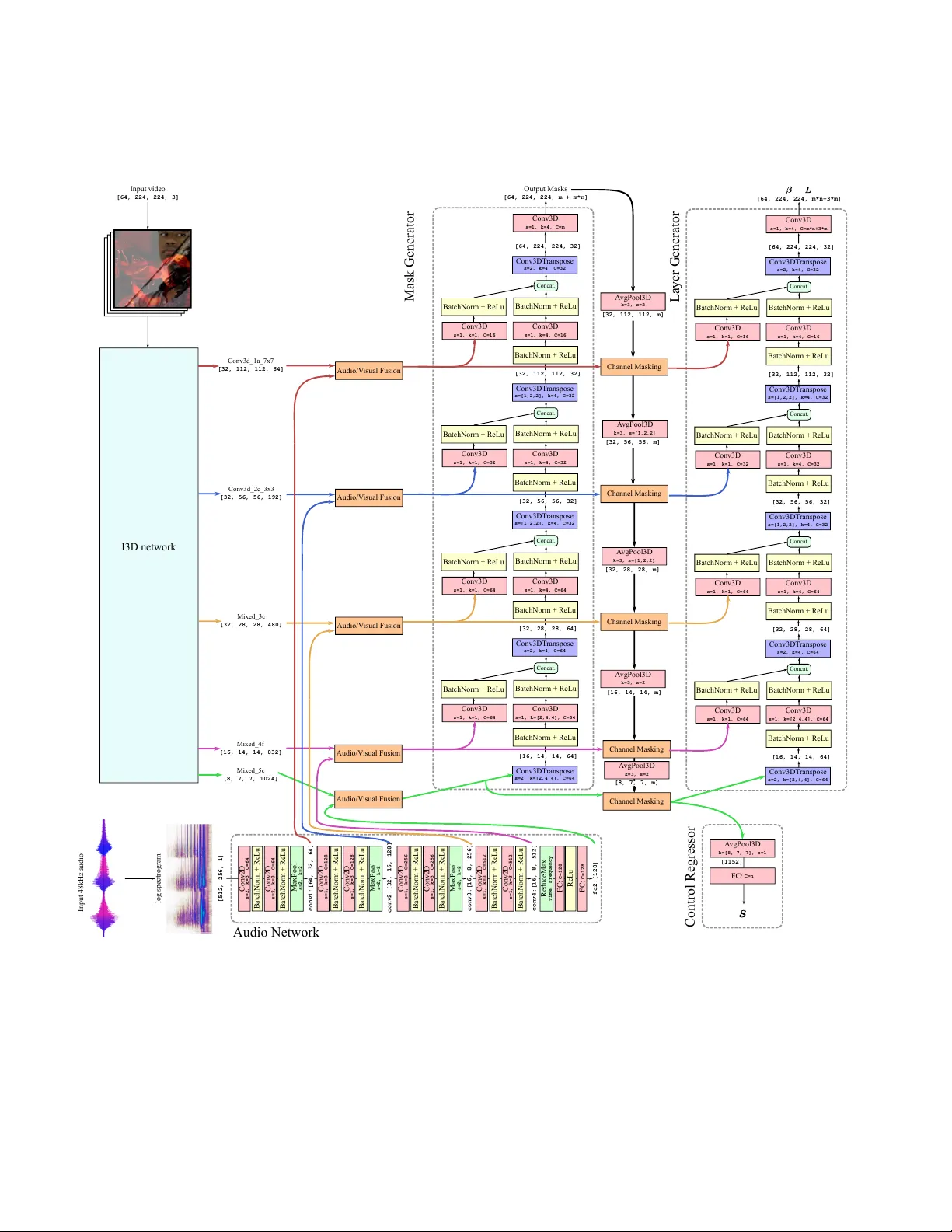
본 논문은 “비디오를 자연스러운 레이어로 분리하고, 원하는 레이어에 선택적으로 주의를 집중할 수 있는 메커니즘”을 제안한다. 연구 배경으로는 인간이 일상에서 거울, 유리, 반사 등 복합적인 시각 정보를 처리할 때, 특정 레이어에 초점을 맞추는 것이 필요하다는 점을 들었다. 기존의 레이어 분해 연구는 주로 이미지 수준이거나, 비디오에서도 출력 슬롯이 임의로 매핑되는 등 제어가 어려운 구조를 가지고 있었다. 이를 해결하기 위해 두 가지 핵심 아이디어를 도입한다.
첫 번째는 **구조화된 신경망 아키텍처**인 Compositional Centrifuge(C²)이다. 이 모델은 기존 Visual Centrifuge의 U‑Net 형태를 기반으로 하지만, 인코더 단계에서 I3D 백본이 생성한 피처를 m개의 스페이셜‑템포럴 마스크와 결합한다. 마스크 M∈
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기