관계형 데이터 초고속 k평균 클러스터링 Rkmeans
Rk‑means는 관계형 데이터베이스에서 피처 추출 쿼리를 실행하지 않고도 k‑means 클러스터링을 수행하도록 설계된 알고리즘이다. 데이터 행렬을 물리적으로 만들 필요 없이 각 테이블을 별도로 클러스터링하고, 그 결과를 교차곱 형태의 그리드 코어셋으로 결합해 최종 k개의 중심을 얻는다. 이 과정은 상수 비율의 근사 보장을 제공하며, 전통적인 “FEQ → k‑means” 파이프라인에 비해 실행 시간과 메모리 사용량에서 수십 배 이상의 개선을 보…
저자: Ryan Curtin, Ben Moseley, Hung Q. Ngo
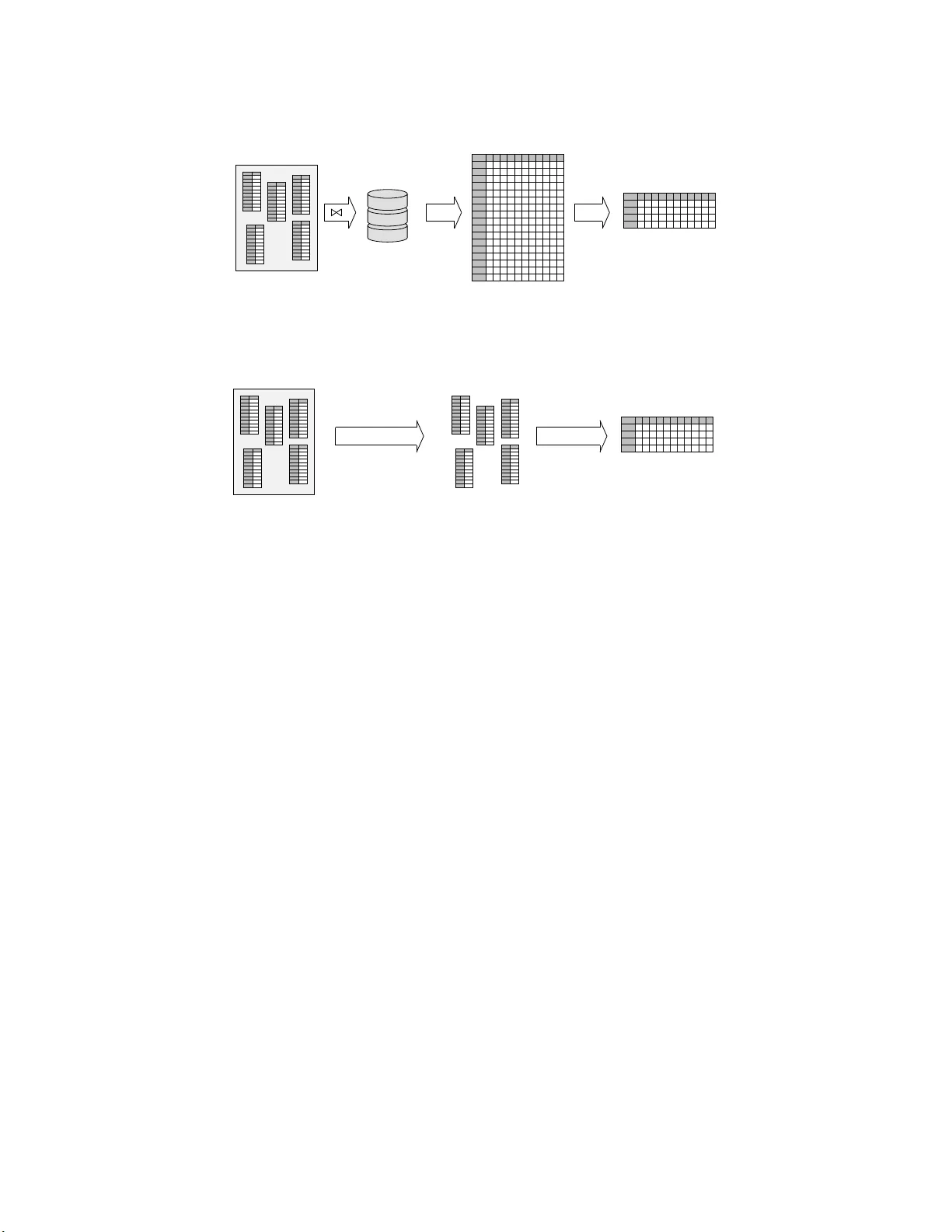
본 논문은 관계형 데이터베이스에 저장된 다중 테이블을 대상으로, 전통적인 피처 추출 쿼리(FEQ)를 수행해 전체 데이터 행렬을 만든 뒤 k‑means 클러스터링을 적용하는 방식의 비효율성을 극복하고자 한다. 데이터베이스에서 직접 데이터를 추출하면 조인 연산과 집계가 복잡해져 결과 행렬이 원본 테이블 크기보다 수십 배 커질 수 있으며, 이는 메모리와 시간 모두에서 병목이 된다. 이러한 문제를 해결하기 위해 저자들은 Rk‑means라는 새로운 알고리즘을 제안한다.
Rk‑means는 크게 네 단계로 구성된다. 첫 번째 단계에서는 입력 쿼리 Q 의 차원 집합
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기