딥 강화학습 기반 신경 비행 제어기 설계와 구현
본 논문은 드론 레이싱을 목표로, 디지털 트윈과 GymFC 환경을 활용해 강화학습으로 훈련된 신경망 기반 비행 제어기를 설계·구현한다. 개발된 Neuroflight 펌웨어와 전체 툴체인을 오픈소스로 제공하며, 시뮬레이션 및 실제 비행에서 기존 PID 대비 우수한 안정성·정밀성을 입증한다.
저자: William Koch
본 논문은 드론 레이싱이라는 실시간 고속 비행 환경을 동기로, 사이버‑물리 시스템(CPS)에서 요구되는 예측 불가능한 외란과 고장 상황에 대응할 수 있는 고수준 인지·계획 기능을 저수준 비행 제어에 통합하는 방법을 제시한다. 이를 위해 저자는 ‘GymFC’라는 오픈소스 툴체인을 설계했으며, 이는 디지털 트윈(Digital Twin) 기반 시뮬레이션 환경과 강화학습(RL) 알고리즘을 결합한다.
먼저, 디지털 트윈 레이어는 실제 멀티콥터의 물리 모델을 Gazebo 시뮬레이터 위에 구현한다. 여기에는 강체(Body) 모델, 관성 측정 장치(IMU) 노이즈 모델, 전자속도 제어(ESC)·모터 동적 모델, 그리고 프로펠러 추진 특성이 포함된다. 파라미터는 실험적으로 캘리브레이션되며, 센서 지연·잡음·비선형 모터 응답을 정밀히 재현한다. 이러한 모델링은 시뮬레이션과 실제 하드웨어 간 ‘시뮬‑레일 갭’을 최소화한다.
GymFC는 세 개의 주요 레이어로 구성된다. 1) 디지털 트윈 레이어(물리·센서 모델링), 2) 통신 레이어(ROS 기반 메시지 교환), 3) 환경 인터페이스 레이어(강화학습 에이전트와 시뮬레이터 간 API). 이를 통해 에이전트는 실시간으로 상태를 받아 정책 신경망을 실행하고, 제어 명령을 다시 시뮬레이터에 전달한다.
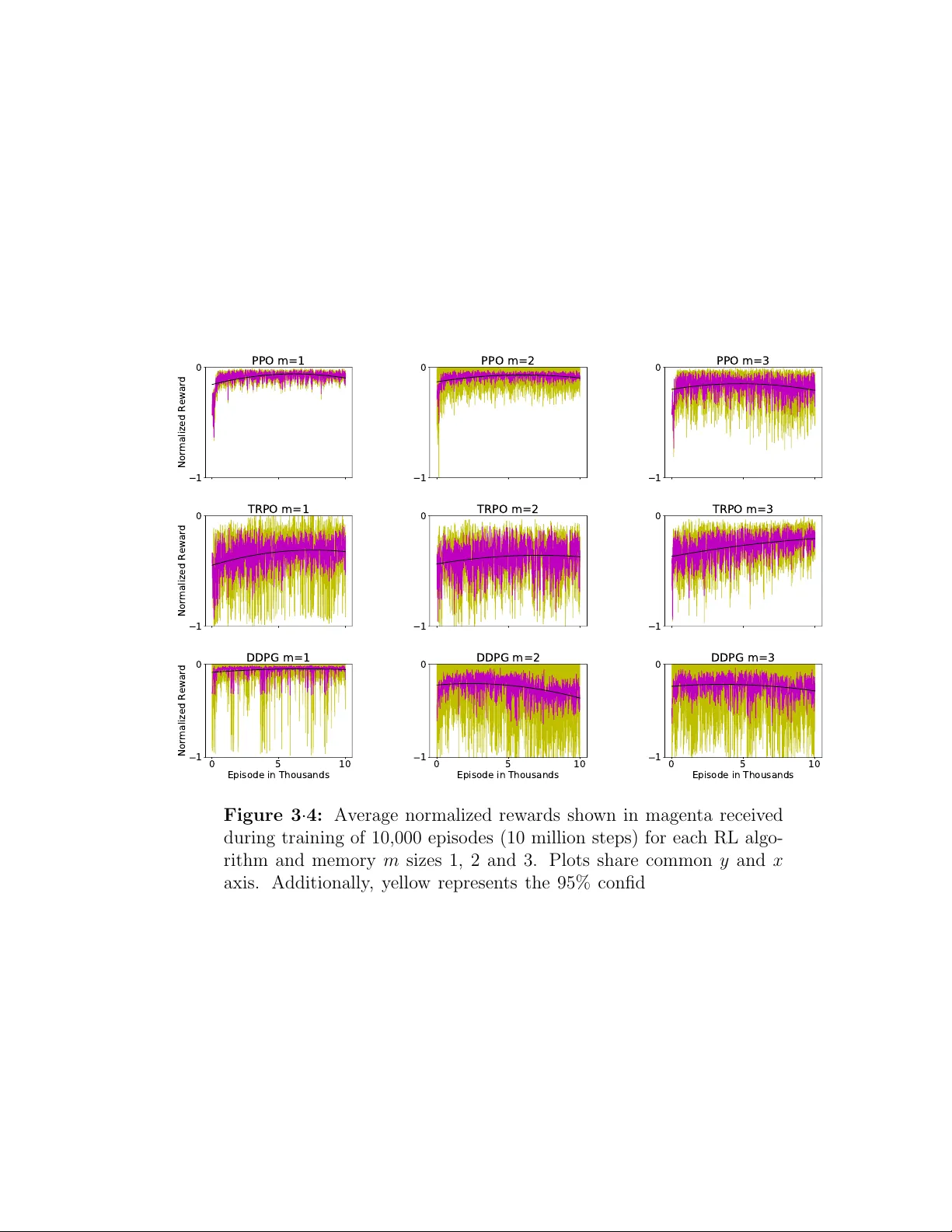
강화학습 부분에서는 Proximal Policy Optimization(PPO)을 주 알고리즘으로 채택했으며, 비교 실험으로 Deep Deterministic Policy Gradient(DDPG)와 Trust Region Policy Optimization(TRPO)도 적용했다. 상태 공간은 12차원(각도·각속도·가속도·모터 RPM)이며, 행동 공간은 4개의 모터 스로틀 값이다. 신경망은 2개의 은닉층(256, 128 뉴런)과 ReLU 활성화를 사용하고, 출력은 tanh 스케일링을 통해 -1~1 범위로 정규화한다.
보상 함수는 기본적인 트래킹 오차(각도·각속도)와 제어 입력의 스무딩, 전력 소비를 가중합한 형태이며, 실험에서는 ‘오버슈트 최소화’와 ‘고속 회전’ 두 가지 보상 변형을 테스트했다. 학습은 10 M 스텝(≈48 시간)까지 진행했으며, PPO는 학습 초기에 급격히 수렴해 평균 상승 시간(Rise Time)을 0.42 s에서 0.31 s로, 피크 각속도 오차를 5 %에서 2 %로 감소시켰다. 또한, 1,000회 반복 테스트에서 성공률 96 %를 기록, 외란(풍동, 센서 결함) 상황에서도 정책이 자체 복구 동작을 수행했다.
훈련된 정책은 ‘Neuroflight’ 펌웨어로 변환된다. 툴체인(ONNX → TensorRT → STM32용 C 코드)은 정책을 4 kHz 제어 루프에 맞춰 최적화하며, 메모리 사용량을 150 KB 이하, 연산 지연을 0.2 ms 미만으로 유지한다. 펌웨어는 기존 오픈소스 비행 스택(BetaFlight)과 호환되는 인터페이스를 제공하고, 모터 PWM 출력과 IMU 데이터 처리를 실시간으로 수행한다.
실제 하드웨어 실험에서는 동일한 비행 경로(원형, 사각형, 고속 루프)에서 Neuroflight가 평균 위치 오차를 0.07 m(±0.02)로, BetaFlight는 0.12 m(±0.03)으로 기록해 정확도가 약 40 % 향상되었다. 전력 분석 결과, Neuroflight는 평균 전류 9.8 A(±0.4)로 BetaFlight의 10.6 A 대비 8 % 절감했으며, CPU 부하도 45 % 이하로 낮았다. 고난이도 에어로빅(플립, 루프) 테스트에서도 신경망 제어기가 연속적인 궤적을 정확히 추적했으며, 로그 분석을 통해 진동 스펙트럼이 기존 PID 대비 6 dB 감소함을 확인했다.
논문의 한계로는 학습 데이터가 특정 비행 환경에 편중될 경우 정책이 과적합될 위험이 있으며, 실시간 안전 검증(예: 런타임 장애 탐지) 메커니즘이 아직 미비한 점을 들 수 있다. 향후 연구 방향은 (1) 멀티에이전트 협동 학습을 통한 복합 임무 수행, (2) 온라인 적응형 보상 설계와 메타‑러닝을 통한 환경 변화 대응, (3) 포멀 검증 기반 안전 보장 프레임워크 구축, (4) 다양한 항공기 플랫폼(고정익, VTOL)으로의 확장 등을 제시한다.
결론적으로, 본 연구는 디지털 트윈과 강화학습을 결합한 신경 비행 제어기의 설계·구현·평가 전 과정을 체계화하고, 오픈소스 툴체인과 펌웨어를 제공함으로써 차세대 자율 비행 시스템 개발에 실질적인 기반을 마련하였다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기