포트 해밀토니안 기반 신경망 학습 프레임워크
본 논문은 신경망 가중치를 이산적인 업데이트가 아닌 연속적인 미분방정식, 즉 포트‑해밀토니안 시스템으로 모델링한다. 손실 함수를 해밀토니안으로 설정해 에너지 감소를 보장함으로써 최적점으로의 수렴을 이론적으로 뒷받침한다. 실험을 통해 제안 방법의 유효성을 확인하였다.
저자: Stefano Massaroli, Michael Poli, Federico Califano
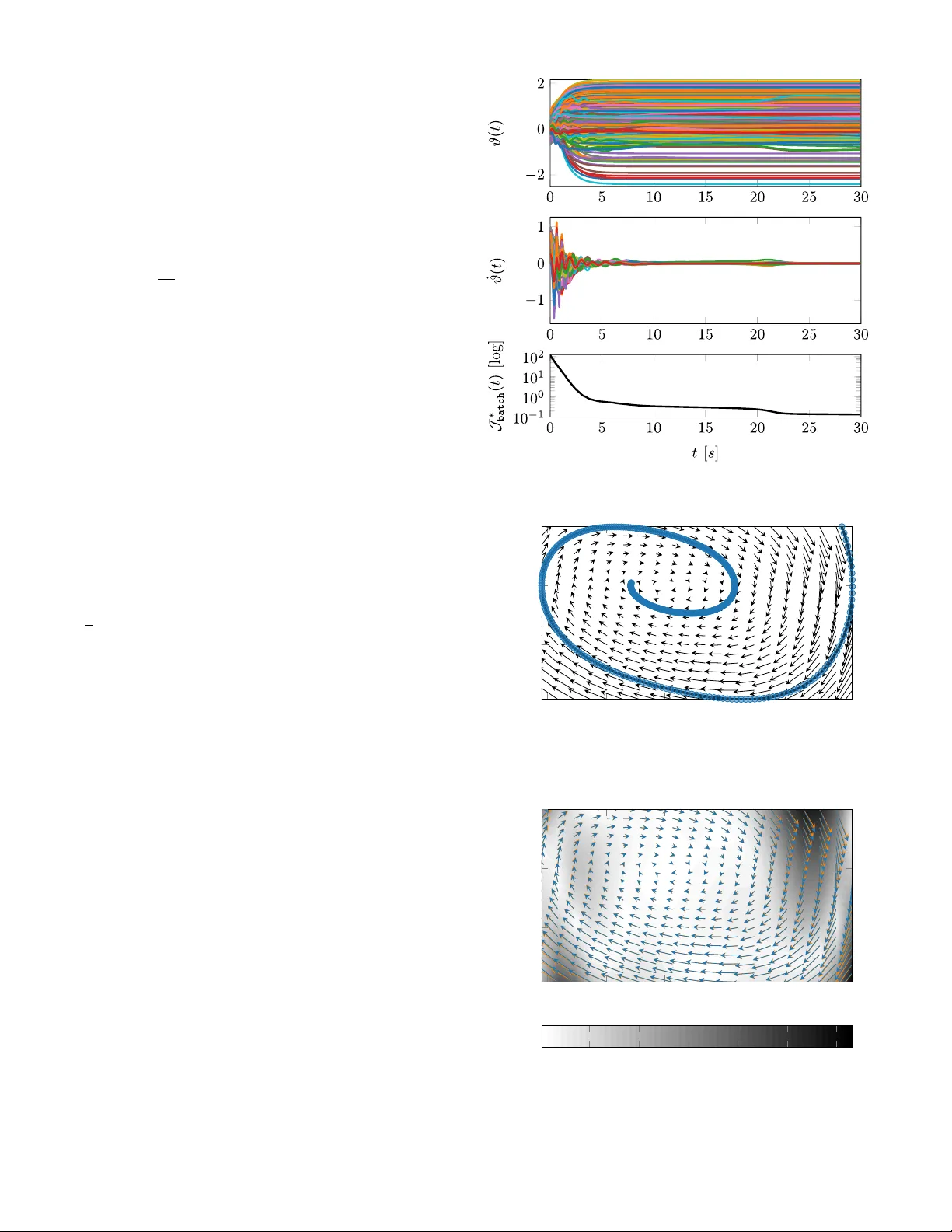
본 논문은 신경망 학습을 전통적인 이산적 파라미터 업데이트가 아닌 연속적인 동역학, 구체적으로 포트‑해밀토니안(PH) 시스템으로 재구성하는 새로운 프레임워크를 제안한다. 서론에서는 딥러닝이 현재 대부분 확률적 경사하강법(SGD), Adam, RMSProp 등 차분 방정식 기반 최적화에 의존하고 있음을 지적하고, 이러한 이산적 접근이 비볼록 손실 지형에서 전역 최적점 보장을 어렵게 만든다고 비판한다. 최근 ODE‑Net과 같은 연속적 레이어 모델이 등장했지만, 여전히 파라미터는 이산적으로 최적화된다는 점을 강조한다.
관련 연구 파트에서는 연속 레이어 모델, Hamiltonian 기반 네트워크, 에너지 기반 모델(Hopffield 등)과의 차이를 정리한다. 특히, 기존 연구들은 네트워크 출력 자체를 ODE로 모델링하거나, Hamiltonian을 정규화 항으로 사용했지만 파라미터 동역학을 연속화하지는 않았다.
문제 정의 파트에서는 신경망을 f(u,θ) 형태의 매핑으로 정의하고, 손실 J(u,y,θ) 를 최소화하는 전통적 최적화 문제를 공식화한다. 차분식 θ_{t+1}=θ_t+Γ(·) 와 대비해, 본 논문은 파라미터를 상태 ξ=(θ,ω) 로 두고, ξ의 연속시간 동역학을 PH 시스템 형태로 기술한다. PH 시스템은
˙ξ =
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기