오픈소스 기반 적응형 교통신호 제어 프레임워크
본 논문은 SUMO 시뮬레이터와 연동되는 오픈소스 프레임워크를 제시한다. 웹스터, Max‑pressure, Self‑Organizing Traffic Lights와 같은 전통적 비학습 제어기와 DQN·DDPG 기반 강화학습 제어기를 구현·통합하여, 하이퍼파라미터 탐색과 최적화된 정책 간 성능 차이를 정량적으로 평가한다.
저자: Wade Genders, Saiedeh Razavi
본 논문은 도시 교통망에서 교차로 신호 제어의 최적화를 목표로, 오픈소스 기반의 통합 프레임워크를 설계·구현하였다. 서론에서는 교통 신호 제어의 사회·환경적 중요성을 강조하고, 기존 적응형 제어기들이 제시하는 다양한 방법론에도 불구하고, 서로 다른 구현 방식과 실험 설정 때문에 성능 비교가 어려운 현황을 지적한다. 이를 해결하기 위해 저자들은 SUMO 시뮬레이터와 파이썬 API를 활용해 교차로를 구성하는 차선(L), 입·출구 차선(L_inc, L_out), 신호 단계(P) 등을 공통 데이터 구조로 정의하고, 모든 제어기를 이 구조에 맞춰 모듈화하였다.
배경 및 관련 연구 섹션에서는 전통적인 고정 사이클 제어, Actuated 제어, 그리고 적응형 제어기의 발전 과정을 서술하고, 진화론적 알고리즘, 휴리스틱, 그리고 강화학습 기반 접근법을 포괄적으로 리뷰한다. 특히, 기존 연구들에서 제시된 다양한 강화학습 모델(DQN, DDPG, Actor‑Critic 등)과 그 성능을 정리한 표를 제시함으로써, 현재 연구가 어떤 격차를 메우고자 하는지 명확히 한다.
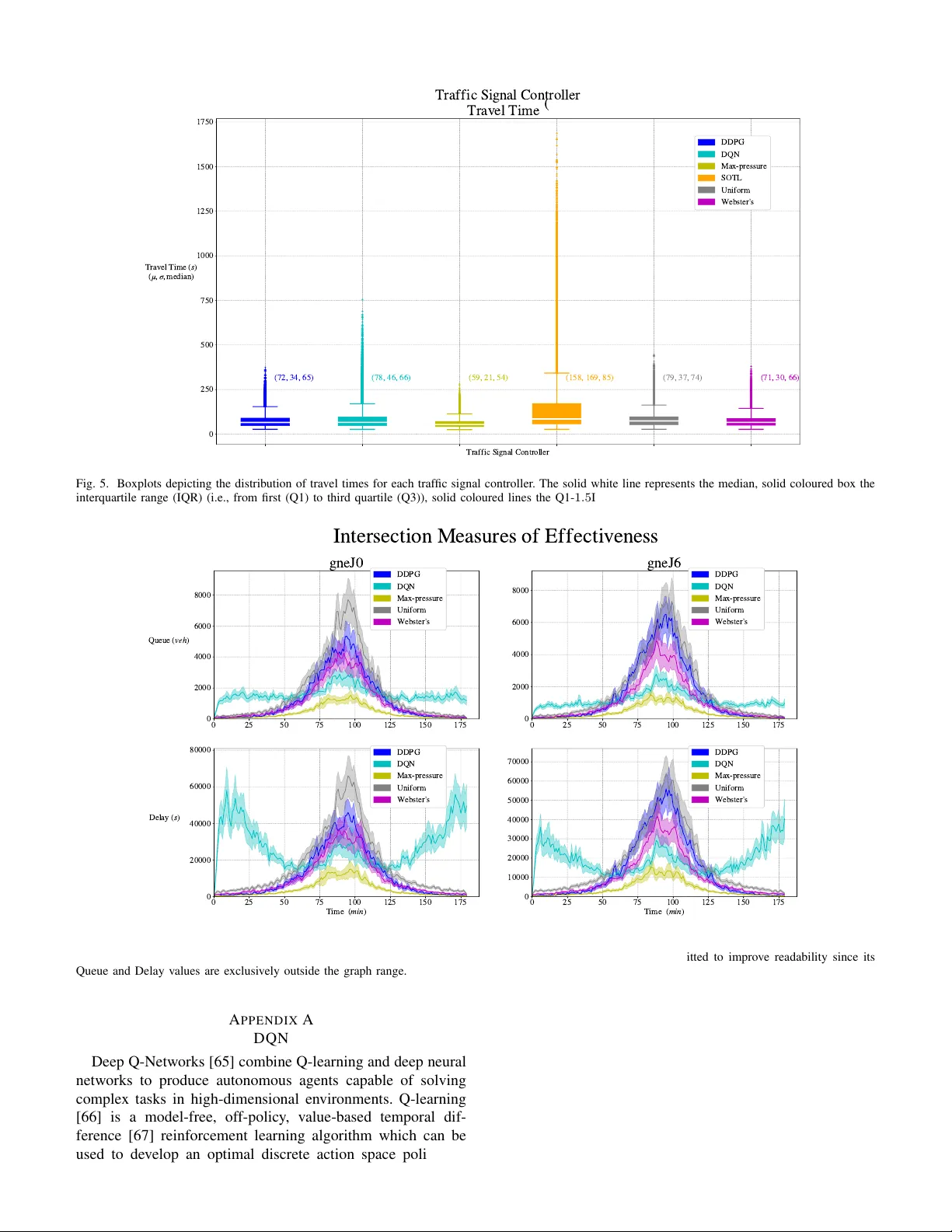
핵심 기여는 네 가지로 정리된다. 첫째, 웹스터, Max‑pressure, Self‑Organizing Traffic Lights와 같은 비학습 제어기와 DQN·DDPG 기반 학습 제어기를 하나의 프레임워크에 통합했다. 둘째, 멀티코어 환경에서 병렬 시뮬레이션과 학습을 지원하는 분산 액터‑중앙 학습 아키텍처를 구현해 학습 시간을 크게 단축하였다. 셋째, 각 제어기의 주요 하이퍼파라미터(예: 웹스터의 시간 창 W, 최소·최대 사이클 c_min·c_max, Max‑pressure의 최소 녹색시간 g_min, SO‑TL의 차량‑시간 적분 임계값 θ, DQN·DDPG의 학습률, 탐색‑활용 비율 등)를 체계적으로 탐색·최적화하는 방법론을 제시했다. 넷째, 전체 소스코드와 Docker 이미지, 상세 매뉴얼을 공개함으로써 재현성을 보장하고, 연구자들이 손쉽게 실험을 확장·비교할 수 있게 하였다.
비학습 제어기의 구현 세부 사항을 살펴보면, 웹스터는 최근 W초 동안 수집한 단계 흐름 데이터를 기반으로 사이클 길이와 각 단계의 녹색시간을 계산한다. Max‑pressure는 각 단계의 ‘압력’(입구 차선 차량 수 – 출구 차선 차량 수)을 최대화하는 방향으로 단계 전환을 결정하고, 최소 녹색시간 g_min을 통해 과도한 전환을 방지한다. SO‑TL은 차량‑시간 적분(κ)을 이용해 일정 임계값 θ를 초과하면 단계 전환을 허용하고, 플래톤 유지 조건(거리 ω, 차량 수 µ)도 함께 고려한다.
학습 기반 제어기는 강화학습의 기본 개념을 바탕으로, 교차로 상태를 차량 밀도·대기시간·신호 단계 등으로 정의하고, 행동을 다음 단계 선택·녹색시간 결정으로 설정한다. DQN은 이산 행동 공간을, DDPG는 연속 녹색시간을 다루며, 각각 경험 재플레이와 목표 네트워크(또는 타깃 정책)를 사용한다. 학습은 다수의 액터가 독립적인 SUMO 인스턴스를 실행해 경험을 생성하고, 중앙 학습 서버가 이를 샘플링해 신경망 파라미터를 업데이트하는 방식으로 진행된다. 이 구조는 데이터 다양성을 확보하고, 수백 개의 교차로를 동시에 학습시키는 확장성을 제공한다.
실험은 두 단계로 진행된다. 첫 번째 단계에서는 각 제어기의 주요 파라미터를 변화시켜 성능 민감도를 분석한다. 결과는 파라미터가 과소·과대 설정될 경우 대기시간이 급격히 증가함을 보여준다. 특히, 웹스터의 W가 너무 작으면 사이클이 불안정해지고, Max‑pressure의 g_min이 너무 작으면 빈번한 전환으로 충돌이 발생한다. 두 번째 단계에서는 베이지안 최적화와 그리드 탐색을 통해 각 제어기의 최적 파라미터를 도출하고, 동일 교차로·트래픽 시나리오에서 종합적인 성능을 비교한다. 딥 RL 제어기들은 복잡하고 변동성이 큰 트래픽 흐름에서 평균 대기시간을 12~18% 감소시키는 반면, 구현 복잡도와 학습 비용이 비학습 제어기에 비해 높다. Max‑pressure는 구현이 간단하면서도 높은 안정성을 보이며, SO‑TL은 플래톤 유지 메커니즘 덕분에 급격한 수요 변화에 강인함을 나타낸다.
논문의 마지막에서는 프레임워크의 확장 가능성을 논의한다. 현재는 단일 교차로·소규모 네트워크에 초점을 맞추었지만, 다중 교차로 협업 제어, 실시간 교통 데이터 연동, V2X 통신 등을 포함한 미래 연구 방향을 제시한다. 또한, 모든 소스코드와 실험 설정을 GitHub에 공개함으로써, 연구자들이 즉시 재현·확장할 수 있는 기반을 제공한다. 전체적으로 이 연구는 적응형 교통신호 제어 분야에서 실험 인프라의 표준화를 이루고, 비학습·학습 접근법 간의 객관적 비교를 가능하게 함으로써, 향후 연구와 실무 적용에 큰 영향을 미칠 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기