시각·텍스트 멀티태스크로 저자원 음성 의미 검색 강화
본 연구는 이미지와 연계된 음성 캡션을 활용해 시각적 감독과 제한된 텍스트 감독을 동시에 학습하는 멀티태스크 모델을 제안한다. 외부 이미지 태거가 제공하는 키워드 확률을 시각적 목표로, 일부 전사된 음성 데이터를 이용한 단어 bag‑of‑words를 텍스트 목표로 사용한다. 세 가지 손실(시각 손실, 텍스트 손실, 대조표현 손실)을 가중합한 후, 다양한 전사량(21분~34시간)에서 의미 검색 성능을 평가한다. 실험 결과, 5시간 정도의 전사만으…
저자: Ankita Pasad, Bowen Shi, Herman Kamper
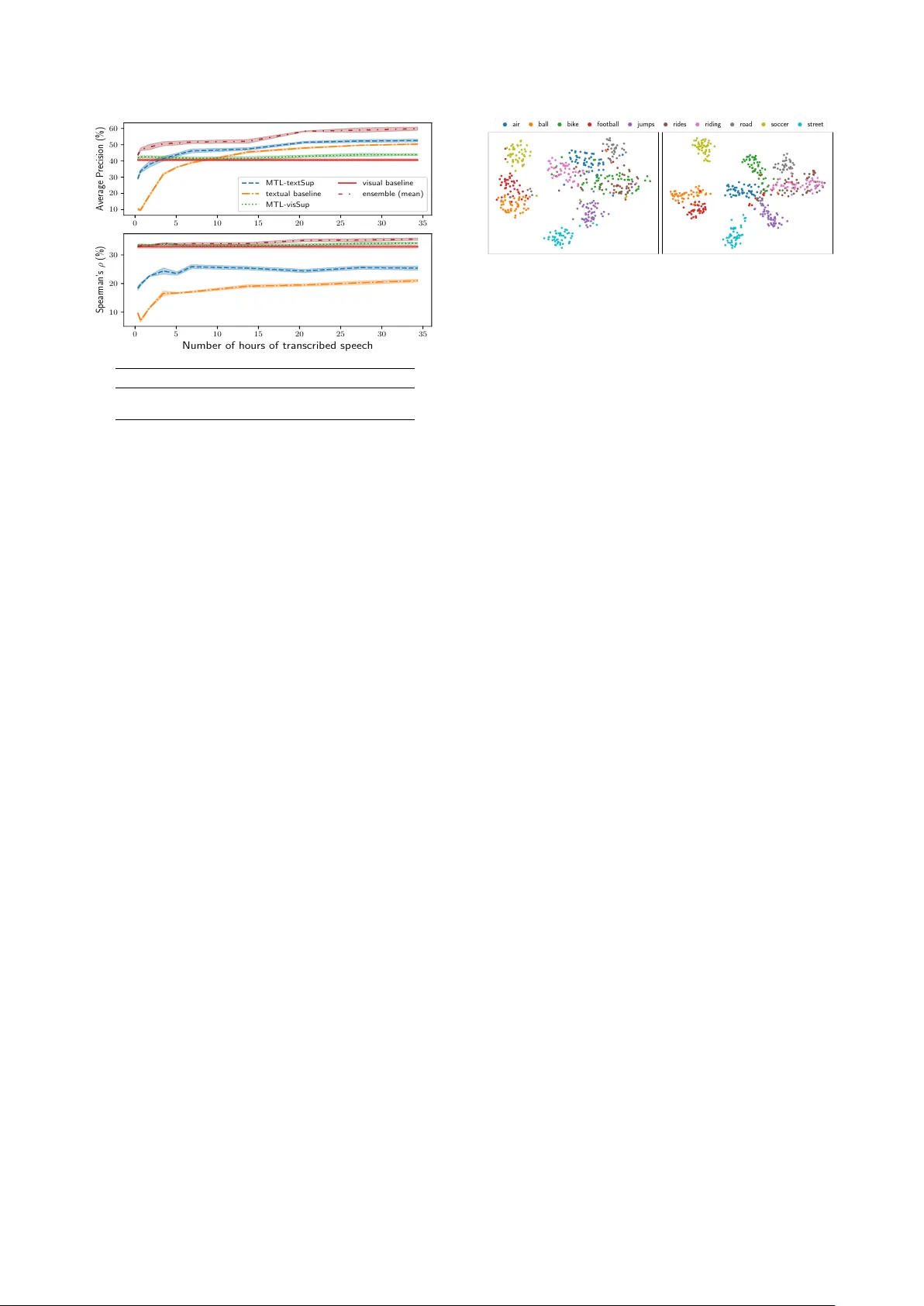
본 논문은 저자원 언어 환경에서 음성 의미 검색을 수행하기 위해 시각적 감독과 텍스트 감독을 동시에 활용하는 멀티태스크 학습 프레임워크를 설계하고, 그 효과를 정량적으로 검증한다. 연구 배경으로는 최근 이미지와 연계된 음성 캡션을 이용해 텍스트 없이도 의미적 음성 표현을 학습할 수 있다는 점이 있다(
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기