역방향 합리적 제어: 연속 비선형 POMDP 모델 추정
본 논문은 동물의 행동을 “자신만의 내부 모델에 따라 최적화된” 것으로 가정하고, 부분관측 연속 비선형 시스템에서 에이전트가 사용하는 동적·보상 파라미터를 역추정하는 프레임워크를 제시한다. 확장 칼만 필터 기반 belief 표현, actor‑critic 기반 정책 학습, 그리고 파라미터 공간 전역 탐색을 결합해 시뮬레이션된 에이전트의 내부 모델을 높은 정확도로 복원한다.
저자: Saurabh Daptardar, Paul Schrater, Xaq Pitkow
본 논문은 동물 행동을 “자신이 가진 내부 세계 모델에 따라 최적화된” 것으로 가정하고, 부분관측 연속 비선형 시스템에서 에이전트가 사용하는 동적·보상 파라미터를 역추정하는 새로운 프레임워크인 “역방향 합리적 제어(Inverse Rational Control, IRC)”를 제안한다. 기존의 IRL(역강화학습)이나 IOC(역최적제어) 연구는 주로 이산형, 완전관측 환경에 초점을 맞추어 왔으며, 연속 상태·액션과 비선형 동역학, 그리고 관측 노이즈가 존재하는 POMDP 상황에서는 계산 복잡도가 급격히 증가한다는 한계가 있었다.
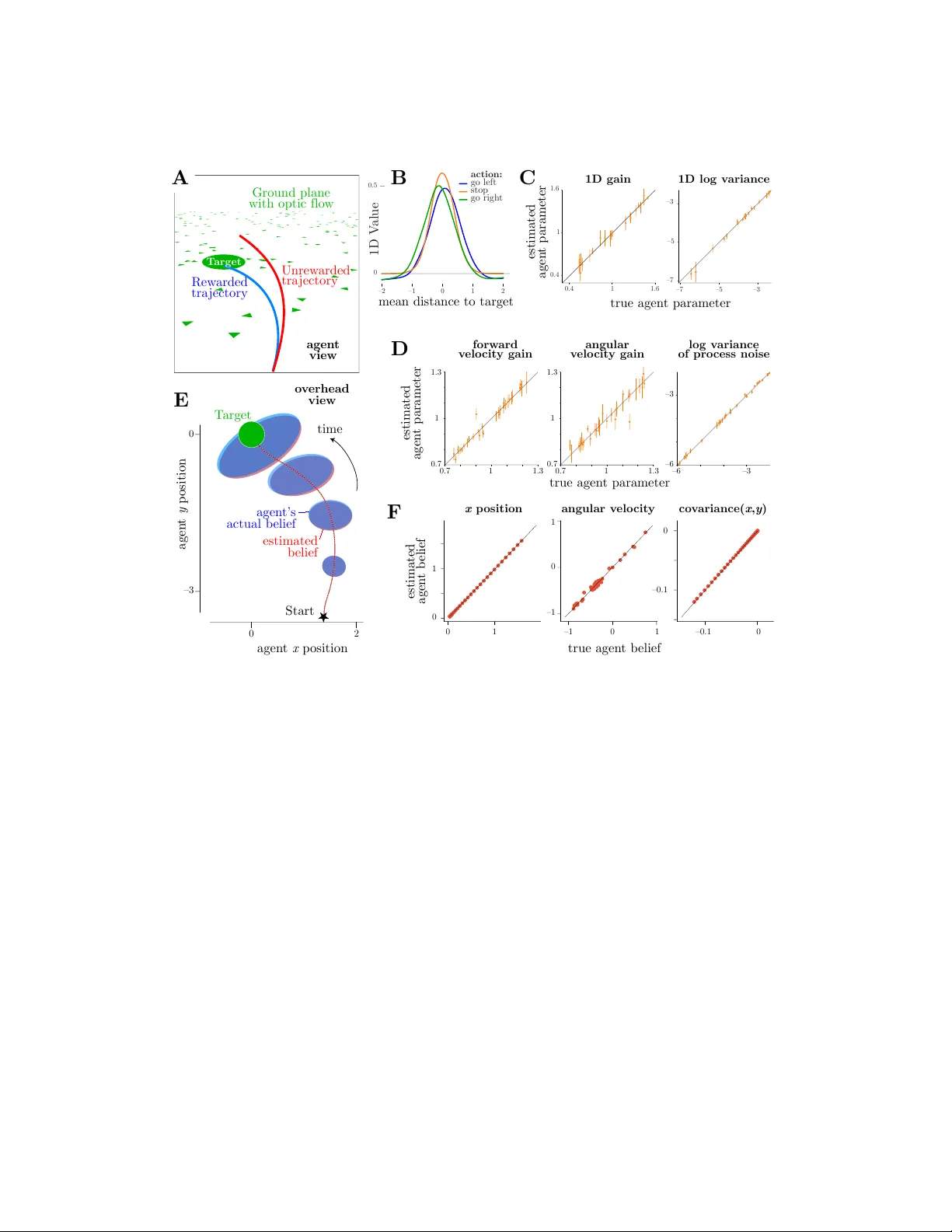
논문은 먼저 POMDP를 (S, A, Ω, R, T, O, γ) 로 정의하고, 에이전트가 내부적으로 가정하는 파라미터 θ = (θ_r, θ_t, θ_o) 로 보상, 전이, 관측 모델을 파라미터화한다. belief b_t = p(s_t | o_{1:t}, a_{1:t}, θ) 는 연속 상태에 대해 다변량 가우시안으로 근사하고, EKF(Extended Kalman Filter)를 이용해 시간에 따라 업데이트한다. 이렇게 정의된 belief 공간에서 최적 정책 π_θ(a | b)와 상태‑액션 가치 함수 Q_θ(b, a)는 Bellman 방정식에 따라 정의되지만, 실제 계산은 비선형·연속 특성 때문에 직접 해석이 불가능하다.
이를 해결하기 위해 저자들은 두 단계 학습 절차를 설계한다. 첫 번째 단계인 “모델 군집 최적 정책 학습”에서는 파라미터 공간 Θ 전체에 대해 샘플링(θ ∼ U(Θ))을 수행하고, 각 θ에 대해 현재 정책 π_θ를 사용해 belief‑action 트래젝터리를 생성한다. 생성된 트래젝터리를 기반으로 Q_θ를 근사하기 위해 강화학습(특히 DDPG 기반 actor‑critic) 방식을 적용한다. 정책 업데이트는 ε‑greedy, softmax, 혹은 연속 액션에 적합한 정책 그라디언트 방법을 사용한다. 이 과정을 반복해 정책과 가치 함수가 수렴하면, 파라미터 전역에 걸친 최적 정책 집합 {π*_θ}와 가치 함수 {Q*_θ}를 확보한다.
두 번째 단계인 “역방향 합리적 제어”에서는 실제 에이전트가 남긴 관측 가능한 데이터(상태 s_t와 행동 a_t 시퀀스)를 이용해 파라미터 θ를 추정한다. 로그우도는
L(θ) = ∑_t
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기