적응형 비평가 기반 최적 운동학 제어
본 논문은 로봇 매니퓰레이터의 운동학 제어를 최적화하기 위해 단일 네트워크 적응형 비평가(SNAC) 구조를 활용한다. 기존의 비평가 가중치 업데이트가 백프로파게이션에 의존하던 문제를 해결하고, 새로운 가중치 조정 법칙을 제안하여 최적 비용 수렴과 폐루프 안정성을 동시에 보장한다. 고정 목표 위치 도달(규제)과 시간 변화 궤적 추적(추적) 두 상황을 각각 최적 규제와 최적 추적 문제로 모델링하고, Lyapunov 기반 증명을 통해 이론적 안정성을…
저자: Aiswarya Menon, Ravi Prakash, Laxmidhar Behera
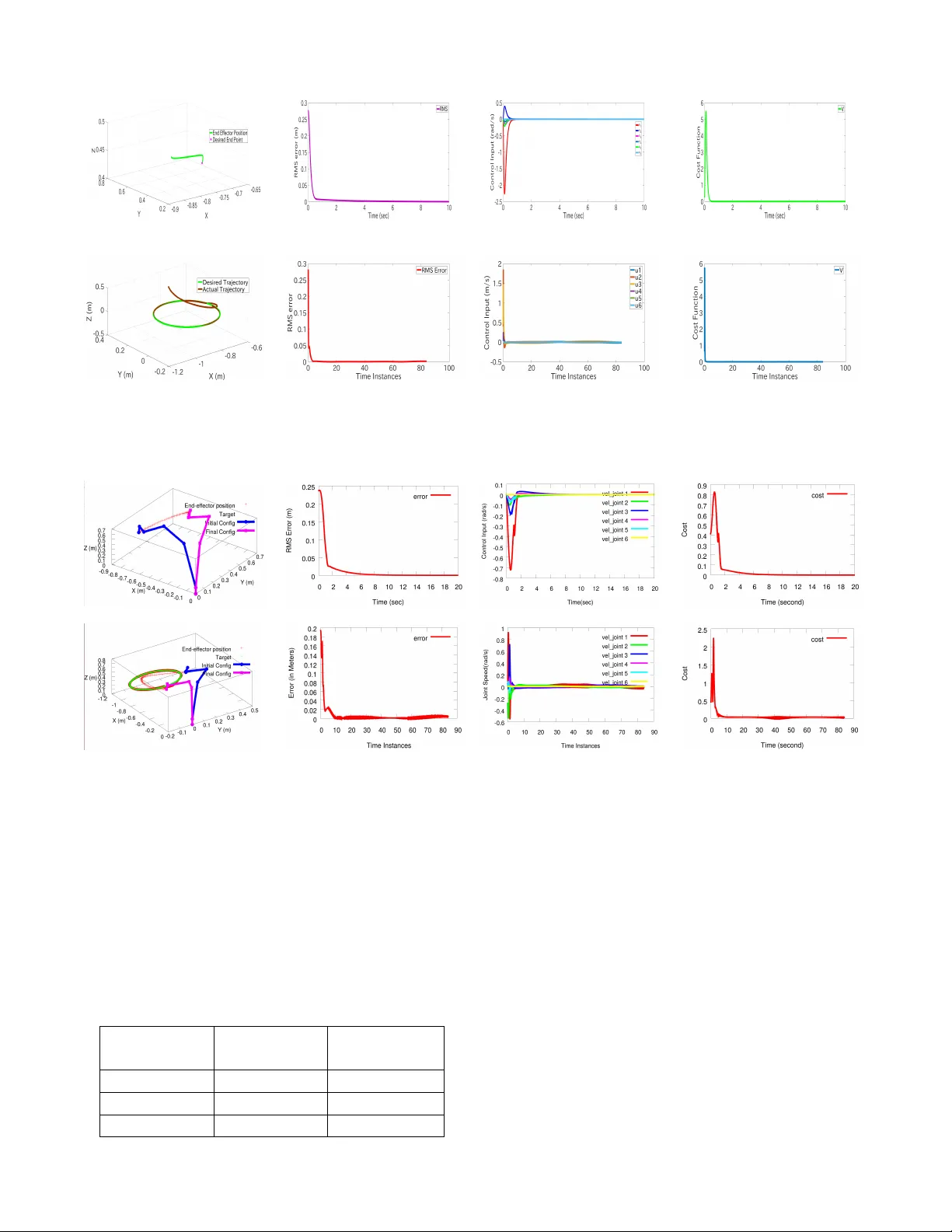
본 논문은 로봇 매니퓰레이터의 운동학 제어를 최적화하기 위해 단일 네트워크 적응형 비평가(SNAC) 구조를 활용하고, 기존의 비평가 가중치 업데이트가 백프로파게이션에 의존하던 한계를 극복하는 새로운 가중치 조정 법칙을 제안한다. 논문은 크게 네 부분으로 구성된다.
첫 번째 부분에서는 문제 정의와 기존 연구 동향을 소개한다. 현대 로봇 시스템은 자유도 증가와 복잡한 작업 환경으로 인해 전방 운동학을 해석적으로 구하기 어려워졌다. 기존에는 뉴럴 네트워크나 퍼지 네트워크를 이용해 역운동학을 근사했지만, 전역 비용 함수를 최적화하면서 동시에 역운동학을 학습하는 방법은 부족했다. 또한, Hamilton‑Jacobi‑Bellman(HJB) 방정식 기반의 최적 제어는 해석적 해가 존재하지 않아 근사 동적 프로그래밍(ADP) 기법을 사용했으며, 이때 두 개의 네트워크(액션, 비평가)를 이용해 최적 정책을 학습한다. SNAC는 이러한 구조를 단일 네트워크로 축소했지만, 비평가 가중치를 백프로파게이션으로 업데이트하면서 최적 비용에 대한 수렴성을 이론적으로 증명하지 못했다.
두 번째 부분에서는 고정 목표 위치 도달(규제) 문제를 다룬다. 로봇의 전방 운동학을 속도 수준에서 \(\dot x = J u\) 로 표현하고, 목표 위치 \(x_d\) 와의 오차 \(e = x - x_d\) 를 정의한다. 무한 시간 Horizon의 비용함수 \(V = \int_0^\infty (e^T Q e + u^T R u) dt\) 를 최소화하기 위해 HJB 방정식을 도출하고, 최적 제어법칙 \(u^* = -\frac12 R^{-1} J^T \nabla V\) 를 얻는다. 비평가 함수 \(V\) 를 단일 은닉층 신경망으로 근사하고, 목표 가중치 \(W_c\) 와 근사 오차 \(\epsilon_c\) 로 분리한다. 기존 연구와 달리, 비평가 가중치 업데이트를 \(\dot{\hat W}_c = \alpha \nabla \sigma_c J R^{-1} J^T \nabla J_s(e)\) 로 정의한다. 여기서 \(J_s(e)=\frac12 e^T e\) 는 Lyapunov 후보이며, \(\alpha\)는 학습률이다.
세 번째 부분에서는 시간 변화 궤적을 추적하는 문제(추적)를 다룬다. 목표 궤적 \(x_d(t)\) 가 동적 시스템 \(\dot x_d = \phi(x_d)\) 를 따른다고 가정하고, 오차와 목표 궤적을 결합한 증강 상태 \(\xi =
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기