멀티채널 사운드 이벤트 검출을 위한 시간‑주파수‑채널 Squeeze‑Excitation 모델
본 논문은 다중 마이크 배열에서의 사운드 이벤트 검출(Sound Event Detection, SED)을 위해, 시간‑주파수와 채널 두 축의 상호 의존성을 동시에 학습하는 tfc‑SE(Time‑Frequency‑Channel Squeeze‑Excitation) 모듈을 제안한다. 기존 CRNN 구조에 tfc‑SE 블록을 삽입하면 연산량은 크게 증가하지 않으면서 ER을 0.2538에서 0.2026(‑20.17 %)로, F1을 5.72 % 향상시킨다…
저자: Wei Xia, Kazuhito Koishida
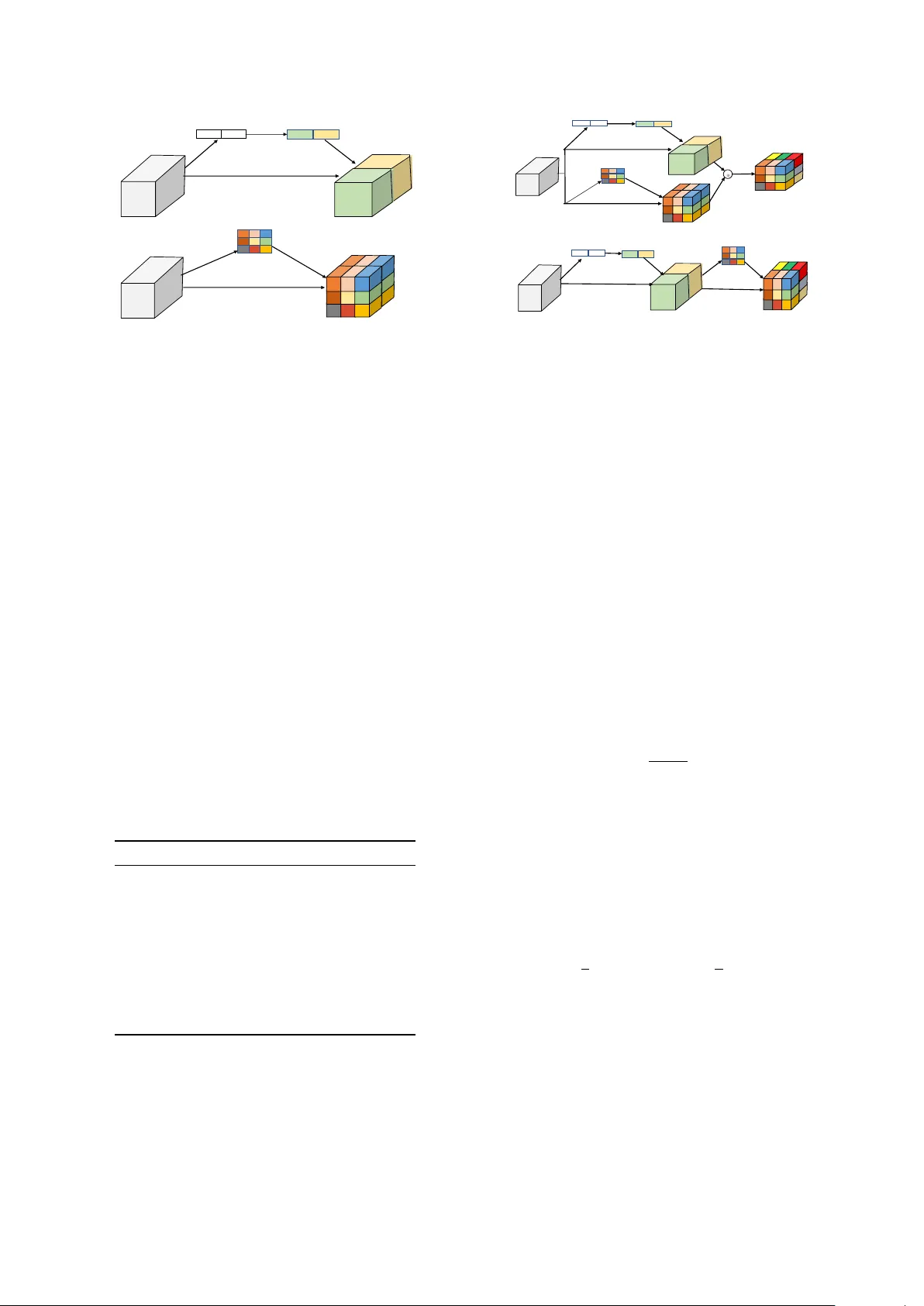
본 논문은 멀티채널 오디오에서의 사운드 이벤트 검출(Sound Event Detection, SED) 성능을 향상시키기 위해, 기존의 Convolutional Recurrent Neural Network(CRNN) 구조에 새로운 Squeeze‑Excitation(SE) 모듈을 도입한다. 제안된 tfc‑SE(Time‑Frequency‑Channel Squeeze‑Excitation) 모듈은 두 개의 서브 블록, 즉 시간‑주파수 SE(tf‑SE)와 채널 SE(c‑SE)로 구성된다.
c‑SE 블록은 전통적인 SE와 동일하게 전역 평균 풀링을 통해 각 채널에 대한 전역 통계 z∈ℝ^{1×1×C}를 추출한다. 이후 차원 축소 비율 r을 적용한 두 개의 완전 연결층과 ReLU, 시그모이드 활성화를 거쳐 채널별 가중치 s∈ℝ^{1×1×C}를 얻는다. 이 가중치는 원본 피처 U의 각 채널에 원소별 곱셈을 수행함으로써, 중요한 채널을 강조하고 불필요한 채널을 억제한다.
tf‑SE 블록은 채널 차원을 1×1 컨볼루션으로 압축한 뒤, 시그모이드 함수를 적용해 시간‑주파수 위치별 중요도 맵 S∈ℝ^{T×F}를 만든다. 이 맵은 각 (시간, 주파수) 좌표에 대한 스칼라 값 s_{i,j}를 제공하며, 원본 피처 U의 해당 위치에 원소별 곱셈을 수행해 시간‑주파수 영역에서의 주의를 구현한다.
두 블록을 결합하는 방법은 크게 두 가지이다. 첫 번째는 동시(concurrent) 방식으로, c‑SE와 tf‑SE가 각각 독립적으로 재조정한 피처를 동일한 시점에 어그리게이션한다. 어그리게이션 연산으로는 합산, 곱셈, 최대값, 채널 연결(Concatenation) 네 가지를 실험하였다. 실험 결과, 최대값 연산이 가장 높은 성능을 보였으며, 이는 두 주의 맵이 서로 보완적인 정보를 제공하면서도 파라미터 증가 없이 효율적인 결합을 가능하게 하기 때문이다. 두 번째는 순차(sequential) 방식으로, 먼저 c‑SE를 적용해 채널 차원을 재조정한 뒤, 그 결과에 tf‑SE를 적용한다. 순차 방식이 전체 성능에서 가장 우수했으며, F1 점수 84.23 %와 ER 0.2026을 달성하였다.
데이터셋은 8채널 마이크 어레이를 시뮬레이션한 CRESIM (TUT Sound Events 2018)이며, 11개의 환경음 클래스를 포함한다. 각 녹음은 30 초 길이이며, 최대 3개의 겹치는 이벤트가 존재한다. 입력 피처는 각 채널의 magnitude와 phase 스펙트로그램을 결합한 16채널 형태이며, 프레임당 512 포인트 FFT와 50 % 오버랩을 사용한다. 프레임 수준에서 평균·분산 정규화를 수행하고, T=256 프레임(≈1.5 s) 시퀀스로 구성한다.
CRNN 기반 모델은 3개의 2D CNN(3×3, 64필터) → MaxPool → Bi‑GRU(128) → FC(128) → FC(N) 구조이며, Adam(1e‑3) 옵티마이저와 교차 엔트로피 손실 함수를 사용해 1000 epoch까지 학습한다. 조기 종료는 100 epoch 연속 SS‑ED 점수 향상이 없을 경우 적용한다.
성능 평가는 1 초 세그먼트 기반 ER과 F‑score를 사용했으며, 제안 모델은 원본 CRNN 대비 ER을 20.17 % 감소(0.2538→0.2026), F1을 5.72 % 상승시켰다. 동시 방식에서도 모든 어그리게이션 방법이 원본보다 개선을 보였으며, 특히 최대값 어그리게이션은 F1 85.79 %와 ER 0.1703을 기록했다. 차원 축소 비율 r에 대한 민감도 분석에서는 r=8~16 사이가 최적임을 확인했으며, r가 너무 작으면 채널 의존성을 충분히 포착하지 못하고, r가 너무 크면 과적합 위험이 증가한다는 trade‑off를 제시한다.
결론적으로, tfc‑SE 모듈은 시간‑주파수와 채널 두 차원에서 독립적인 주의 메커니즘을 동시에 제공함으로써, 멀티채널 사운드 이벤트 검출에서 복합적인 패턴을 효과적으로 학습한다. 연산량 증가는 미미하지만 성능 향상이 현저하여, 실시간 또는 저전력 환경에서도 적용 가능성이 높다. 향후 연구에서는 실제 마이크 어레이 녹음, 다양한 스펙트로그램 변형, 그리고 다른 시퀀스 모델(RNN, Transformer)과의 결합을 통해 일반화 성능을 더욱 확장할 수 있을 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기