정규화 근사 하강법으로 구현한 다층 스파이킹 신경망의 시공간 오류 역전파 학습
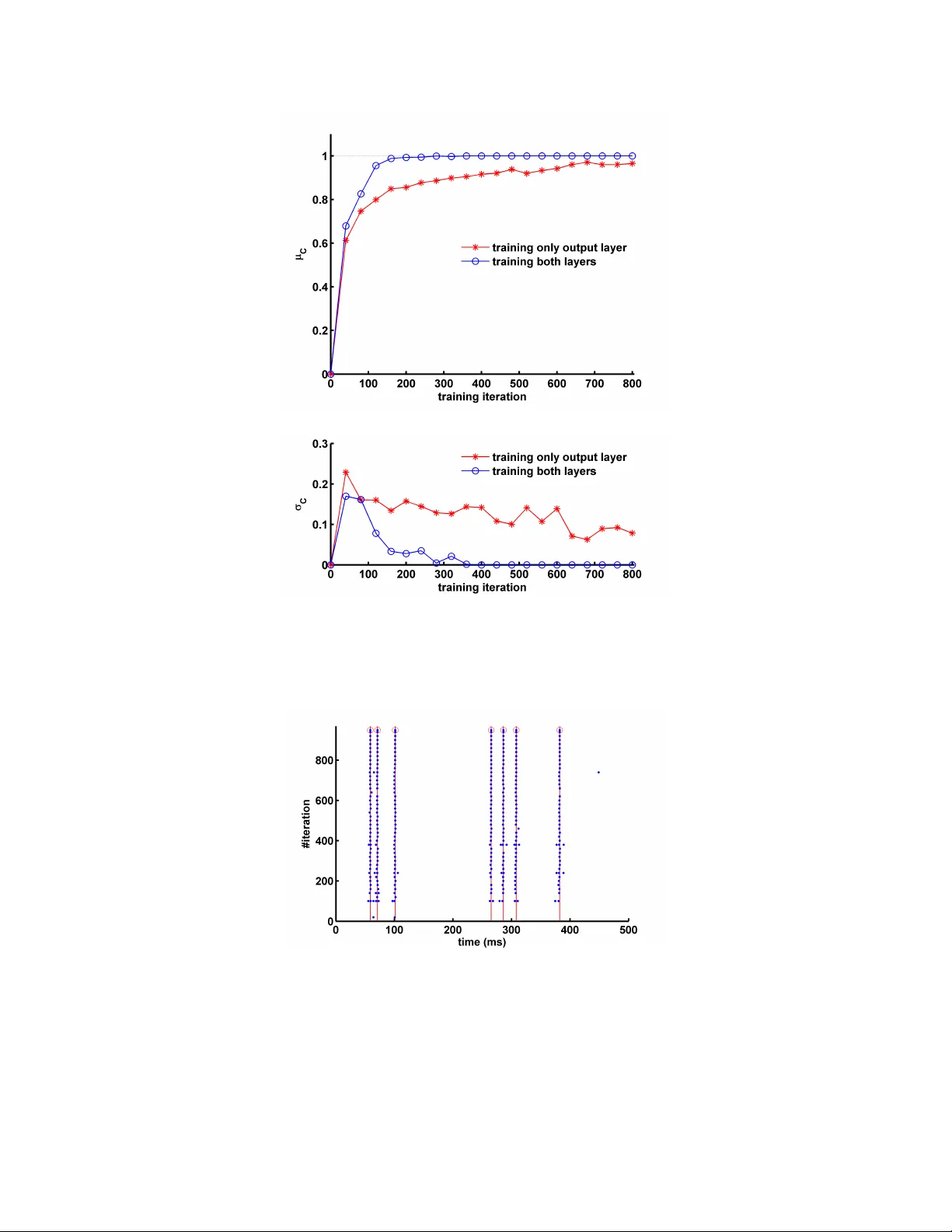
본 논문은 다층 피드포워드 스파이킹 신경망(SNN)의 학습을 위해 목표 함수를 막전위 편차로 정의하고, 정규화 근사 하강법(NormAD)을 이용해 시공간 오류 역전파 규칙을 도출한다. 2‑계층 XOR 문제와 3‑계층 일반 스파이크 기반 과제에서 우수한 수렴 속도와 정확도를 보이며, 깊은 SNN 구축을 위한 핵심 알고리즘으로 제시된다.
저자: Navin Anwani, Bipin Rajendran
본 논문은 스파이킹 신경망(SNN)의 다층 학습을 위한 새로운 최적화 프레임워크를 제시한다. 서론에서는 인간 뇌의 거대한 뉴런·시냅스 네트워크가 보여주는 고차원 학습 능력을 모방하고자 하는 동기를 설명하고, 기존의 SpikeProp, ReSuMe, STDP 기반 방법들이 스파이크 시점 차이를 직접 최소화하려다 비선형·비볼록 최적화 문제에 빠져 학습 속도와 정확도가 제한되는 점을 지적한다.
관련 연구 섹션에서는 SpikeProp(단일 스파이크), 다중 스파이크 확장, STDP·Widrow‑Hoff 결합 방식, NSEBP, multi‑STIP 등 다양한 접근법을 정리하고, 이들 대부분이 고정된 네트워크 구조에 대한 가중치 업데이트만을 다루거나, 목표 함수를 스파이크 시점 차이로 정의해 미분이 불가능한 문제에 직면한다는 공통점을 강조한다.
3절에서는 LIF(Leaky Integrate‑and‑Fire) 뉴런 모델을 수학적으로 정리한다. 입력 스파이크열은 시냅스 커널 α(t)와 가중치 w에 의해 전류 i(t)=w·α(t−t_f) 로 변환되고, 모든 시냅스 전류는 가중합 I(t)=wᵀc(t) 로 합산된다. 이후 누설 적분기 h(t)= (1/C_m)·exp(−t/τ_L)·u(t) 와 컨볼루션되어 막전위 V(t)=E_L + wᵀd(t) 가 생성된다. 여기서 d(t) = (c(t)·u(t−t_l))∗h(t) 로 정의되며, t_l 은 마지막 스파이크 시점이다. V(t)가 임계값 V_T 를 초과하면 스파이크가 발생하고 V(t) 가 E_L 로 리셋된다.
4절에서는 다층 피드포워드 SNN의 학습 문제를 공식화한다. 목표는 각 출력 뉴런의 막전위 궤적 V_out(t) 가 사전에 정의된 목표 전위 V*_out(t) 와 최소 L2 차이를 갖도록 하는 것이다. 손실 함수 J = ½∫
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기