GPU 가속으로 재탄생한 i‑Vector: 3000배 빠른 프레임 정렬과 25배 빠른 학습
본 논문은 i‑Vector 추출 파이프라인을 GPU로 구현해 프레임 사후확률 계산을 실시간 대비 3000배, i‑Vector 추출기 학습을 25배 가속한다. 가속 덕분에 UBM 업데이트와 프레임 정렬 재계산을 학습 중에 적용할 수 있게 되었으며, Kaldi의 비공식적인 ‘bias‑augmented’ 구현을 정리하고 최소 발산 재추정(min‑divergence) 기법을 상세히 제시한다. VoxCeleb 실험에서 기존 Kaldi 구현보다 1~2% …
저자: Ville Vestman, Kong Aik Lee, Tomi H. Kinnunen
본 논문은 i‑Vector 기반 화자 임베딩 추출에 GPU 가속을 적용함으로써 기존 CPU‑기반 Kaldi 구현의 병목을 해소하고, 새로운 연구 가능성을 열어준다. 서론에서는 i‑Vector가 한때 화자 인식의 표준이었지만, 최근 딥러닝 기반 임베딩(x‑Vector 등)에 밀려 성능이 뒤처졌으며, 학습 비용이 높은 것이 실험 설계에 제약을 주는 주요 원인임을 지적한다. 이를 극복하기 위해 저자들은 최신 GPU 연산 프레임워크(PyTorch)와 Kaldi의 데이터 포맷을 지원하는 PyKaldi를 결합해 전체 파이프라인을 재구현한다.
핵심 기술은 두 단계에 집중된다. 첫 번째는 프레임 사후확률(posteriors) 계산이다. Kaldi와 동일하게 대각 공분산 UBM을 이용해 각 프레임당 상위 20개의 Gaussian을 사전 선택하고, 이후 전체 공분산 UBM으로 정밀 계산을 수행한다. 이때 0.025 이하의 사후확률을 버리고, 남은 값들을 정규화해 평균 4개의 Gaussian만을 저장한다. GPU에서 이 과정을 배치 단위로 수행함으로써 실시간 대비 약 3000배의 속도 향상을 달성한다. 두 번째는 i‑Vector 추출기 학습이다. Baum‑Welch 통계는 CPU에서 계산하고, EM 알고리즘의 E‑step과 M‑step은 GPU에서 행렬 연산으로 처리한다. 전체 학습 과정은 5번의 반복만에 25배 가속되었으며, 이는 5번 반복을 수행하는 데 걸리는 시간과 Kaldi CPU 구현을 직접 비교해 확인하였다.
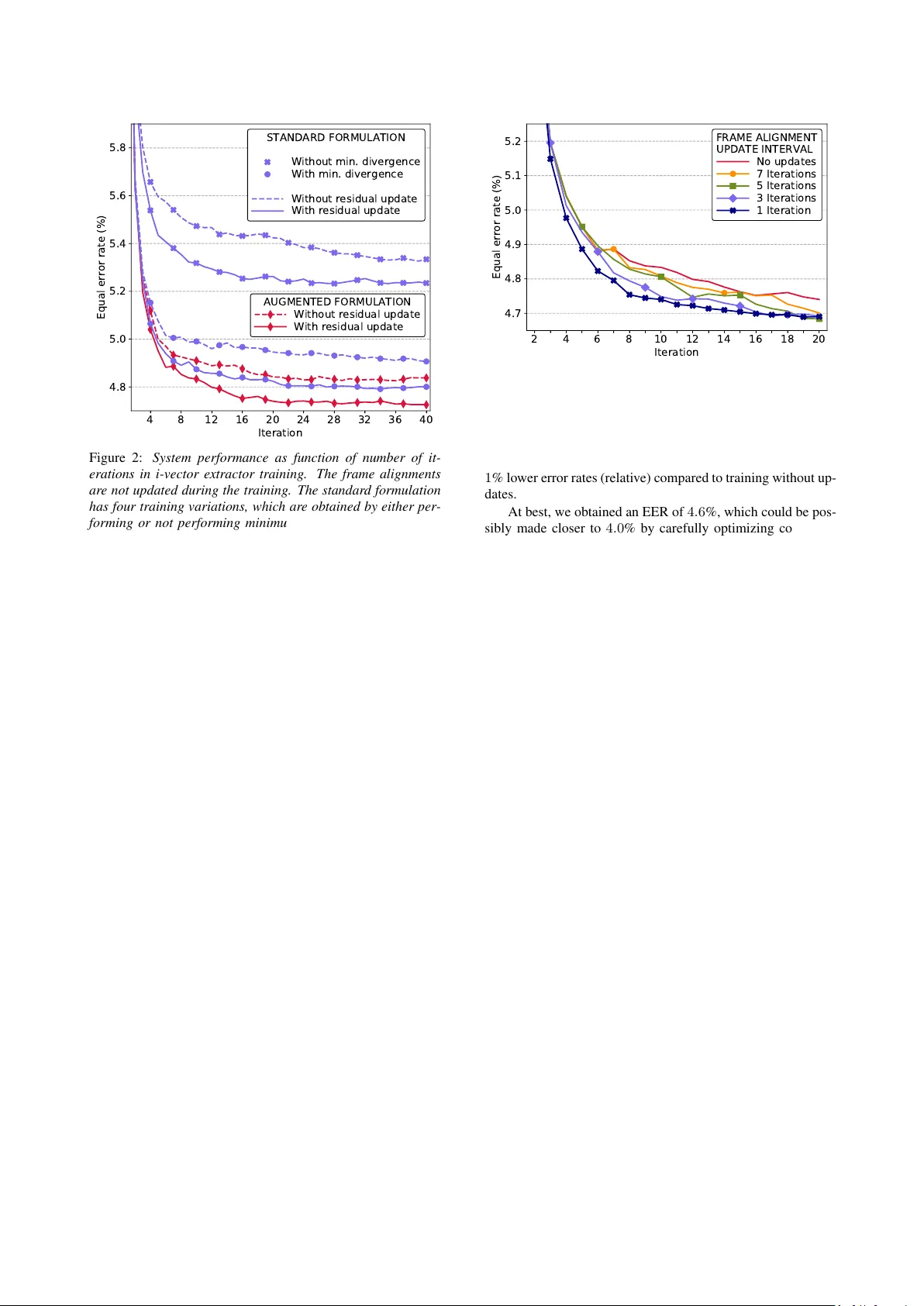
논문은 Kaldi의 i‑Vector 구현이 ‘bias‑augmented’ 형태라는 점을 강조한다. 표준 형태에서는 각 Gaussian의 평균 m_c와 총변동성 행렬 T_c를 별도로 추정하지만, Kaldi에서는 평균을 T_c의 첫 번째 열에 포함시켜 하나의 행렬로 공동 학습한다. 이 설계는 평균 중심화가 필요 없으며, EM 업데이트 식이 약간 변형된다. 저자들은 이 차이를 명확히 정리하고, 특히 최소 발산 재추정(min‑divergence re‑estimation) 단계에서 필요한 두 변환(P₁, P₂)을 상세히 설명한다. P₁은 i‑Vector 공분산을 백색화(whitening)하는 변환이며, P₂는 Householder 변환을 이용해 평균 벡터를 첫 번째 차원에만 남기도록 조정한다. 이를 통해 augmented 모델에서도 표준 정규분포에 가까운 i‑Vector를 얻을 수 있다.
학습 향상을 위한 추가 전략으로는 UBM 업데이트와 프레임 정렬 재계산(realignment)이 있다. 기존 Kaldi에서는 학습 동안 UBM과 정렬을 고정했지만, GPU 가속으로 매 반복마다 UBM 평균을 현재 T_c의 첫 번째 열과 prior p를 곱해 갱신하고, 이를 기반으로 프레임 사후확률을 다시 계산한다. 이 과정은 화자 정보를 손실시키지 않으면서 모델 적합도를 높인다.
실험은 VoxCeleb1/2 데이터셋을 사용해 수행되었다. MFCC(72 차원, Δ, ΔΔ 포함)와 2048‑component full‑covariance UBM을 구축하고, 가장 긴 100 000개의 발화를 학습에 사용했다. 학습된 i‑Vector는 중심화와 길이 정규화 후 LDA(400→200)와 PLDA로 스코어링했으며, VoxCeleb1의 37 720개 시험을 통해 EER을 측정했다. 실험 변수는 (1) 표준 vs. augmented 모델, (2) 최소 발산 재추정 적용 여부, (3) residual 공분산 Σ_c 업데이트 여부, (4) 프레임 정렬 재계산 여부이다. 결과는 다음과 같다. – augmented 모델이 전반적으로 표준 모델보다 0.5~1.5% 낮은 EER을 보였다. – 최소 발산 재추정과 residual 업데이트를 동시에 적용했을 때 가장 큰 성능 향상이 관찰되었다 (약 1~2% 절대적 개선). – 프레임 정렬을 매 반복마다 재계산하면 추가 0.2~0.3% 정도의 EER 감소가 있었다. 모든 실험은 5번의 무작위 초기화에 대해 평균을 취해 통계적 신뢰성을 확보하였다.
결론에서는 GPU 가속이 i‑Vector 파이프라인을 실질적으로 혁신했으며, 이를 통해 기존에 비용 때문에 포기했던 다양한 모델 변형과 학습 전략을 자유롭게 탐색할 수 있게 되었다고 주장한다. 또한, Kaldi의 undocumented ‘bias‑augmented’ 구현을 명확히 문서화함으로써 커뮤니티가 이를 기반으로 새로운 연구를 전개할 수 있는 토대를 제공한다. 향후 연구 방향으로는 이 가속 프레임워크를 다른 총변동성 기반 모델, 혹은 딥러닝 기반 임베딩과 결합해 하이브리드 시스템을 구축하거나, 실시간 화자 인증 시스템에 적용하는 방안을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기