오디오 적대적 예제 방어를 위한 시간 의존성 활용
본 논문은 자동음성인식(ASR) 시스템에 대한 적대적 공격을 방어하기 위해 오디오의 고유한 시간 의존성을 이용한 탐지 방법을 제안한다. 이미지 분야에서 흔히 쓰이는 입력 변환 방어가 오디오에서는 제한적인 효과만 보이며, 최신 적대적 공격에도 쉽게 우회된다. 반면, 입력을 앞부분(k‑프리픽스)과 전체 시퀀스의 전사 결과를 비교해 일관성을 측정하는 시간 의존성 기반 방법은 비적응형·적응형 공격 모두에 대해 높은 탐지 정확도를 유지한다. 실험은 Li…
저자: Zhuolin Yang, Bo Li, Pin-Yu Chen
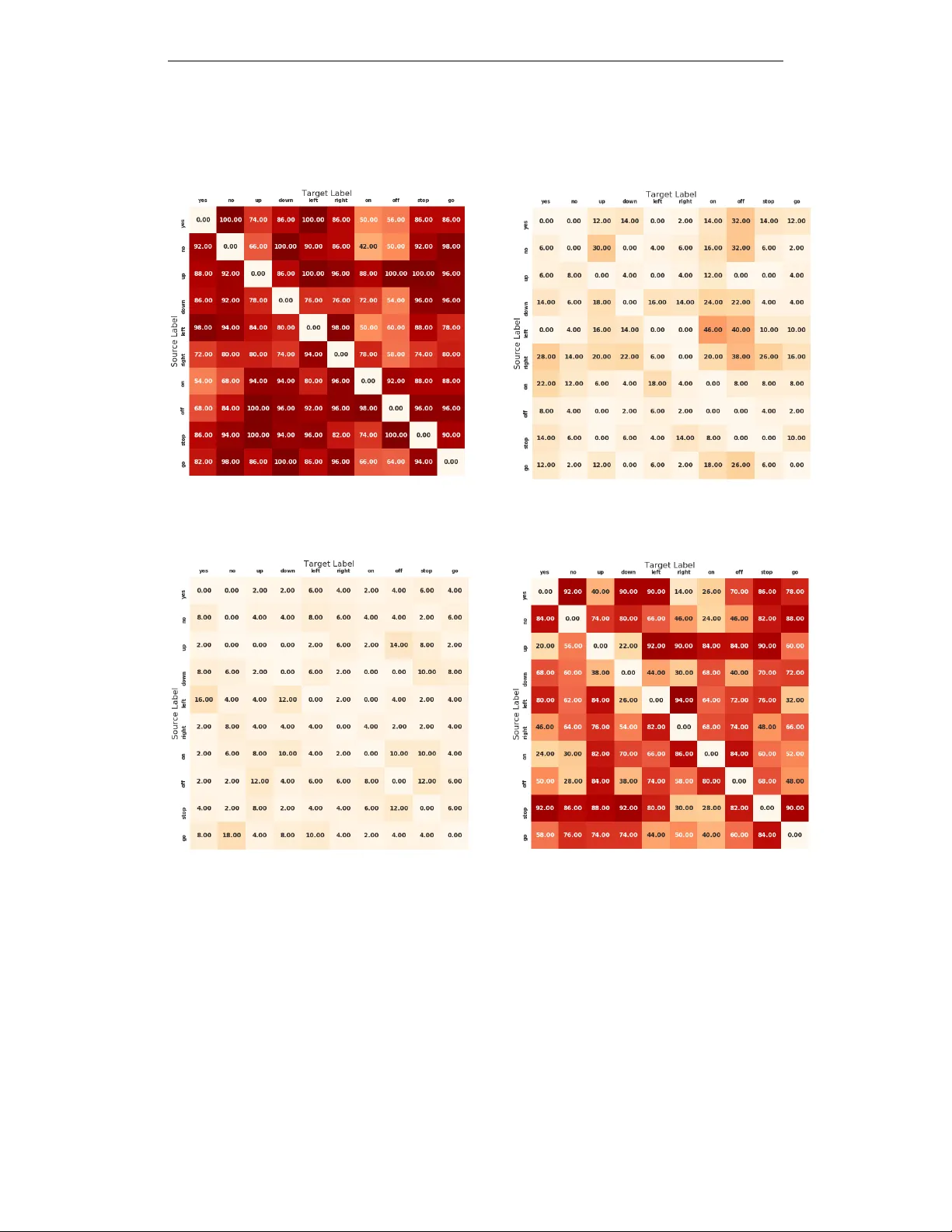
본 논문은 오디오 분야에서 적대적 예제에 대한 방어 메커니즘을 탐구한다. 서론에서는 딥러닝 모델이 이미지뿐 아니라 음성 인식에서도 적대적 공격에 취약함을 지적하고, 이미지에서 성공한 입력 변환 방어가 오디오에도 적용 가능한지 의문을 제기한다. 이어서 데이터 고유의 특성, 특히 시간 의존성이 방어에 활용될 수 있는지를 탐구한다.
관련 연구 파트에서는 이미지와 오디오 적대적 공격의 공통점과 차이점을 정리하고, 기존의 적대적 훈련·데이터 증강 방식은 본 연구와 무관함을 밝힌다. 또한, 이미지에서 공간 일관성을 이용한 방어가 오디오에서는 시간 일관성으로 대체될 수 있음을 제시한다.
입력 변환 방어 섹션에서는 네 가지 기본 변환을 구현한다. 파형 양자화는 작은 진폭 교란을 정수 격자에 맞추어 소멸시키려는 시도이며, 로컬 스무딩은 고정 윈도우 내 평균·중앙값을 적용해 급격한 변화를 완화한다. 다운샘플링은 Nyquist 이론에 근거해 샘플링 레이트를 절반으로 낮추고 복원함으로써 고주파 교란을 제거한다. 마지막으로 시퀀스‑투‑시퀀스 자동인코더는 전체 오디오를 프레임 단위로 재구성해 잡음을 억제한다. 실험 결과, 이들 변환은 최신 적대적 공격(Athalye et al., 2018) 대비 방어 효과가 미미하고, 오히려 정상 음성의 WER·CER을 상승시켜 실용성이 떨어진다. 이는 입력 변환이 “gradient obfuscation”을 일으키며, 공격자가 이를 역추적해 우회할 수 있음을 확인한다.
시간 의존성 기반 탐지 방법(TD)은 핵심 기여이다. 오디오 시퀀스의 앞부분(k‑프리픽스)을 별도 입력으로 ASR에 넣어 전사 S_k를 얻고, 전체 시퀀스를 입력한 뒤 전사 결과의 앞부분을 추출해 S_{whole,k}를 만든다. 두 전사 사이의 Word Error Rate(WER)을 거리로 정의하고, 사전에 설정한 임계값보다 크면 해당 샘플을 적대적이라고 판단한다. 정상 음성은 모델이 시계열 정보를 일관되게 활용하므로 두 전사 간 WER이 낮으며, 적대적 교란은 전역적인 파형 변형을 일으켜 일관성을 깨뜨리므로 높은 WER을 만든다.
실험 설계는 다음과 같다. 데이터셋으로는 LibriSpeech(테스트 클린), Mozilla Common Voice, Speech Commands를 사용한다. 모델은 DeepSpeech(양방향 RNN 기반)와 CNN 기반 음성 명령 분류 모델, 그리고 Kaldi 기반 음성 인식 시스템을 채택한다. 공격은 세 종류를 포함한다. (1) Genetic Algorithm 기반 음성 명령 공격(GA) – 비정형 교란으로 라벨을 바꾸는 공격; (2) Carlini‑Wagner 최적화 기반 음성‑텍스트 공격(Opt) – CTC 손실을 최소화해 목표 텍스트를 강제; (3) Commander Song 공격(Commander) – 실제 노래에 삽입해 물리적 재생까지 가능한 공격. 각 공격마다 100개의 샘플을 생성하고, 방어 효과를 WER·CER 및 탐지 정확도로 평가한다.
결과는 다음과 같다. 입력 변환 방어는 WER·CER 감소 효과가 거의 없으며, 특히 Athalye식 적대적 예제에 대해 방어가 무력화된다. 반면, TD 방법은 비적응형 공격에 대해 96% 이상의 탐지 정확도를 보였고, 적응형 공격(공격자가 방어 로직을 완전히 알 경우)에도 90% 이상 정확도를 유지한다. 이는 시간 의존성 정보가 교란에 대해 비교적 강인함을 의미한다. 또한, TD는 정상 음성에 대한 인식 성능에 거의 영향을 주지 않아 실용적인 방어 메커니즘으로 평가된다.
논의 파트에서는 k 값 선택의 민감도, 프리픽스 길이가 짧을 경우 문맥 부족으로 인한 오탐, 길 경우 연산 비용 증가 등을 언급한다. 또한, 완전 무음 교란이나 비음성 신호에 대한 적용 가능성을 제시하고, 다중 스케일 프리픽스와 동적 임계값 학습을 통한 향후 연구 방향을 제안한다. 결론에서는 이미지와 달리 오디오에서는 데이터 고유의 시간 의존성을 활용한 방어가 효과적이며, 도메인 특화 방어 전략이 적대적 공격 대응에 핵심임을 강조한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기