프로토타입 기반 딥 메트릭 학습을 활용한 화자 인식
본 논문은 화자 임베딩 모델을 프로토타입 네트워크 손실(PNL)로 최적화하여, 기존의 트리플릿 손실(TL) 기반 모델보다 보이지 않는 화자에 대한 인식 성능을 크게 향상시켰다. 동일한 시퀀스 임베딩 구조를 사용했음에도 불구하고, PNL 모델은 화자 검증과 식별 모두에서 낮은 EER과 높은 정확도를 달성했으며, 학습 속도와 구현 편의성에서도 TL을 능가한다.
저자: Jixuan Wang, Kuan-Chieh Wang, Marc Law
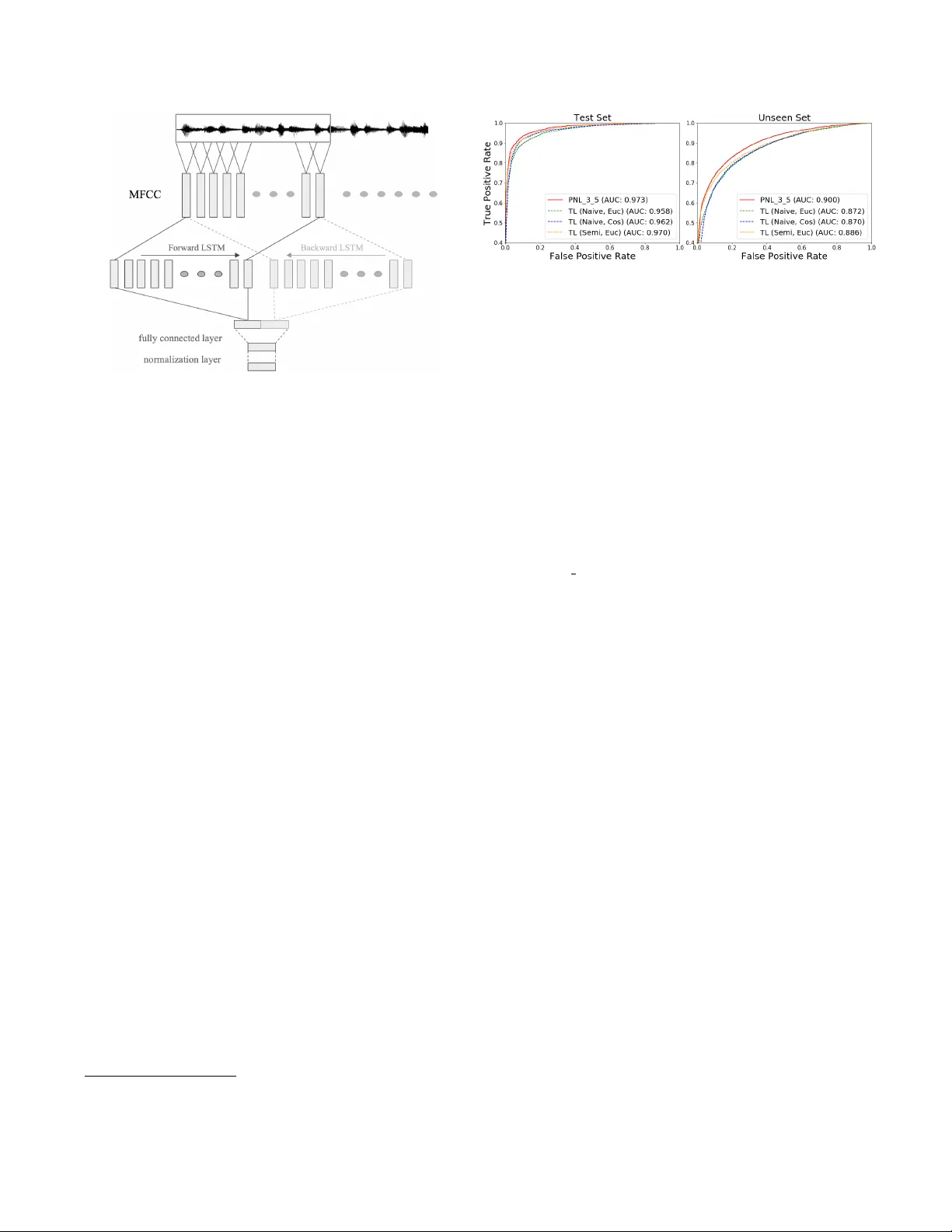
본 논문은 화자 임베딩 모델을 최적화하는 새로운 접근법으로, 최근 이미지 분야에서 뛰어난 성능을 보인 프로토타입 네트워크 손실(Prototypical Network Loss, PNL)을 화자 인식에 적용한다. 기존의 딥 메트릭 학습에서는 트리플릿 손실(Triplet Loss, TL)이 주류였으며, 이는 앵커‑양성‑음성 삼중항을 구성해 마진을 두고 거리 순서를 학습한다. 그러나 TL은 삼중항 샘플링 전략에 크게 의존하고, 동일 클래스 내부 거리 최소화를 직접적으로 보장하지 못한다는 한계가 있다.
PNL은 에피소드 기반 학습을 사용한다. 하나의 에피소드는 K개의 화자(클래스)를 무작위로 선택하고, 각 화자마다 서포트 셋(S)과 쿼리 셋(Q)을 구성한다. 서포트 셋의 임베딩 평균을 해당 화자의 프로토타입(centroid)으로 정의하고, 쿼리 샘플을 이 프로토타입들과의 거리 기반 소프트맥스 확률로 분류한다. 손실은 크로스 엔트로피 형태이며, 이는 동일 화자 샘플이 프로토타입에 가까워지도록 직접적인 압력을 가한다.
실험에 사용된 임베딩 네트워크는 TristouNet과 동일한 구조를 채택했다. 입력은 25 ms 윈도우, 10 ms 스트라이드로 추출한 19차원 MFCC에 1차·2차 미분 및 에너지 파생을 추가해 59차원 특성 벡터를 만든다. 이 시퀀스는 양방향 LSTM을 통과하고, 시간 평균 풀링 후 전결합층과 정규화 층을 거쳐 16차원 임베딩을 출력한다. 거리 함수는 제곱 유클리드 거리이며, TL에서는 마진 α를 0으로 설정해 순수 거리 차이만을 이용한다.
데이터셋은 VCTK와 VoxCeleb2를 사용한다. VCTK는 90명의 화자를 훈련/검증/테스트용으로, 나머지 18명을 ‘unseen’ 셋으로 분리했다. VoxCeleb2는 71명의 화자를 훈련/검증용, 30명을 ‘unseen’ 셋으로 구성했다. 두 데이터셋 모두 2초 길이의 발화를 사용해 비교 가능성을 확보했다.
성능 평가는 세 가지 측면에서 진행되었다. 첫째, “same/different” 실험에서는 동일 화자와 다른 화자 쌍을 무작위로 선택해 거리 임계값으로 판별하고 ROC 곡선을 그렸다. 여기서 PNL은 보이지 않는 화자에 대해 TL보다 현저히 높은 AUC를 기록했다. 둘째, 화자 식별(Speaker Identification, SI)에서는 K‑way(6‑way, 18‑way 등) 설정에서 S개의 등록 샘플과 Q개의 쿼리 샘플을 사용해 프로토타입 기반 최근접 이웃 분류를 수행했다. 3‑shot PNL 모델은 18‑way 식별에서 TL(Semi‑hard, Euclidean) 대비 19% 상대 정확도 향상을 보였으며, 1‑shot PNL도 TL의 Naïve 샘플링 대비 비슷하거나 더 나은 성능을 기록했다. 셋째, 화자 검증(Speaker Verification, SV)에서는 EER(Equal Error Rate)을 측정했다. 2초, 10초, 60초 길이의 등록 발화에 대해 PNL은 TL보다 일관되게 낮은 EER을 보였으며, 통계적으로 유의미한 차이(p < 0.001)를 나타냈다.
이론적 분석에서는 PNL이 Bregman 발산 기반 클러스터링의 특수 형태임을 언급한다. 프로토타입은 각 클래스 평균 벡터이며, 샘플 수가 많을수록 평균에 대한 추정이 정확해져 손실 최소화가 효율적으로 이루어진다. 반면 TL은 전역 최적점에서도 클래스가 하나의 구형 클러스터로 모여 있지 않을 수 있다는 연구 결과와 일치한다. 실험적으로도 TL은 ‘way’ 수가 증가할수록 정확도가 급격히 떨어지는 반면, PNL은 비교적 안정적인 성능을 유지한다.
실용적인 장점도 강조된다. PNL은 삼중항 샘플링과 마진 파라미터 튜닝이 필요 없으며, 동일 배치 크기에서 약 3배 빠른 학습 속도를 보인다. 이는 대규모 음성 데이터와 실시간 시스템에 유리하다. 논문은 향후 더 깊은 시퀀스 모델(예: Transformer 기반)과 화자 다이어리제이션 파이프라인에 PNL 기반 임베딩을 통합하는 연구 방향을 제시한다.
결론적으로, 프로토타입 기반 손실을 적용한 화자 임베딩 모델은 동일한 네트워크 구조에서도 TL보다 전반적인 인식 성능이 우수하고, 학습 효율성과 구현 편의성에서도 장점을 제공한다. 이는 화자 인식 시스템이 실제 서비스 환경에서 새로운 화자를 빠르게 등록하고 정확히 식별해야 하는 요구를 충족시키는 중요한 진전이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기