에너지와 타이밍 데이터를 결합한 딥러닝 기반 뉴트리노‑핵 상호작용 정점 재구성
본 논문은 MINERvA 실험에서 수집된 에너지와 타이밍 정보를 동시에 활용한 합성곱 신경망 모델을 제안한다. 1,453,884개의 시뮬레이션 데이터를 이용해 11개의 세그먼트 분류와 Z축 절대 위치 회귀를 수행했으며, 기존 최고 성능 대비 분류 정확도를 4 %p 상승시켰고 R²는 0.9919로 향상시켰다. 또한 모델 크기와 학습 시간을 크게 줄였다.
저자: Linghao Song, Fan Chen, Steven R. Young
본 논문은 고에너지 물리학 분야에서 뉴트리노‑핵 상호작용 사건의 정점(vertex) 위치를 정확히 추정하는 문제를 다룬다. MINERvA 실험은 뉴트리노 빔을 이용해 다양한 핵 타깃에 대한 상호작용을 기록하며, 각 사건은 플라스틱 섬광체 모듈에 의해 에너지와 타이밍 두 종류의 신호가 이미지 형태로 저장된다. 기존 연구에서는 에너지 이미지만을 이용해 CNN 기반 분류기를 설계하거나, 타이밍 이미지만을 이용해 스파이킹 신경망을 적용했지만, 두 데이터 유형을 동시에 활용한 사례는 없었다.
데이터는 GENIE와 Geant4 시뮬레이터를 통해 생성된 1,453,884개의 사건으로 구성되며, 각 사건은 X‑view(127 × 94), U‑view, V‑view(127 × 47) 두 종류의 뷰를 갖는다. U와 V 뷰는 가로 축을 2배 복제해 127 × 94 형태로 맞춘 뒤, 에너지와 타이밍을 각각 3채널씩 쌓아 총 6채널 텐서를 만든다. 입력 데이터는 뷰별 평균·표준편차를 이용해 정규화하고, uint8 형식으로 변환해 메모리 효율을 높였다.
모델 설계는 ResNet과 DenseNet의 아이디어를 결합한 블록 구조를 채택한다. B1, B2, B3 세 개의 블록은 각각 배치 정규화 → 3×3 컨볼루션 → 맥스 풀링 순서로 구성되며, 블록 간에는 스트라이드가 2 또는 4인 컨볼루션을 통해 다운샘플링하면서도 이전 블록 출력을 채널 차원에서 직접 연결(concatenation)한다. 이러한 직접 연결은 특징 재사용을 촉진하고, 파라미터 수를 최소화하면서도 깊은 네트워크 학습을 가능하게 한다. 최종 분류 레이어는 24 × 7 × 5 텐서를 840 차원으로 펼쳐 전결합층에 입력하고, 11개의 세그먼트 중 하나를 예측한다.
Z축 절대 위치 회귀는 사전 학습된 분류 네트워크의 컨볼루션 부분을 고정하고, 840‑512‑1 구조의 전결합층 두 개만 재학습하는 전이학습 방식을 사용한다. 이는 동일한 입력 데이터를 활용하면서도 두 과업을 효율적으로 공유할 수 있게 한다.
학습은 두 대의 NVIDIA TITAN X(Pascal) GPU를 데이터 병렬 방식으로 수행했으며, SGD 옵티마이저와 단계적 학습률 감소 전략을 적용했다. 분류 모델은 20 epoch, 회귀 모델은 8 epoch 동안 학습했으며, 배치 크기 256, 모멘텀 0.8, 가중치 감쇠 5e‑4를 사용했다.
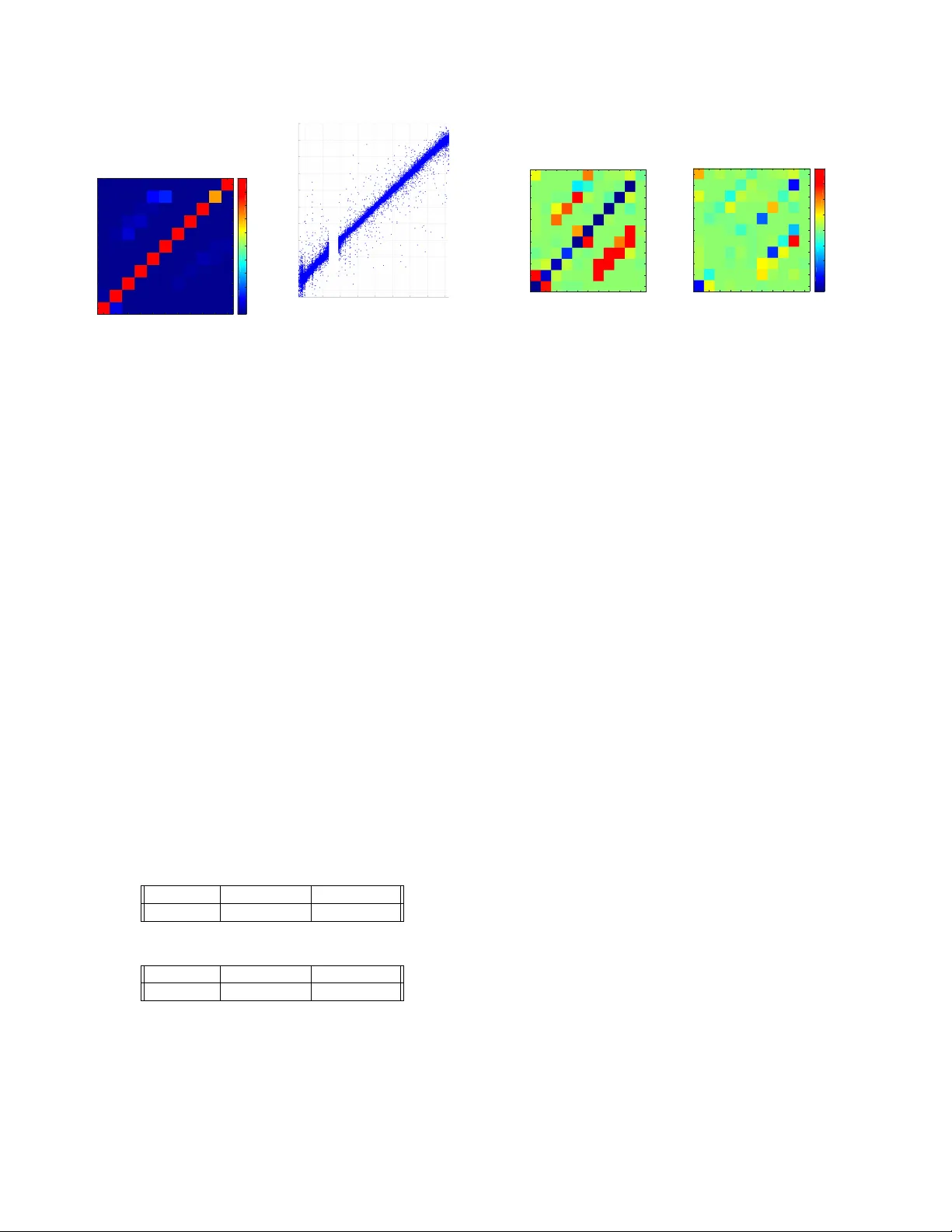
성능 평가 결과, 에너지와 타이밍을 모두 사용했을 때 세그먼트 분류 정확도는 98.09%로 기존 94.09% 대비 4 %p 상승했으며, 모델 크기는 0.488 MB, 학습 시간은 2.5 시간으로 이전 모델(14.5 MB, 10 시간)보다 크게 효율적이었다. 회귀 과업에서는 R²가 0.9919로, 기존 0.96을 크게 초과했다. 혼동 행렬을 살펴보면 대부분의 세그먼트에서 높은 정확도를 보였으나, 데이터 비중이 매우 낮은 세그먼트 9에서 오분류가 발생했다. 이는 클래스 불균형에 기인한 것으로, 향후 가중치 조정이나 오버샘플링 기법이 필요하다.
에너지와 타이밍을 각각 단독으로 사용할 경우, 분류 정확도는 에너지만 사용했을 때 97.95%, 타이밍만 사용했을 때 96.92%로 약간 감소했지만, 회귀 R²는 0.9901~0.9915 수준으로 큰 차이를 보이지 않았다. 이는 타이밍 데이터가 위치 추정에 보조적인 정보를 제공하지만, 핵심적인 특징은 에너지 데이터에 더 많이 포함되어 있음을 시사한다.
결론적으로, 본 연구는 두 종류의 물리량을 동시에 활용한 CNN 기반 모델이 뉴트리노‑핵 상호작용 정점 재구성에서 높은 정확도와 효율성을 동시에 달성할 수 있음을 입증했다. 향후 연구에서는 시계열 특성을 더 잘 포착하기 위해 RNN이나 Transformer 기반 구조를 도입하고, 클래스 불균형 문제를 해결하기 위한 데이터 증강 및 손실 함수 설계가 제안된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기