십년간 음악 취향 변화 탐지와 간단 특징 기반 분류
본 논문은 음악 신호를 개시·전개·종결의 세 구간으로 나누어 평균·분산·왜도·첨도·파워 스펙트럼 밀도·파노 팩터 등 8가지 단순 통계량을 추출하고, 순차 전진 선택(SFS)과 피셔 판별비(FDR), 주성분 분석(PCA)으로 최적 특징을 선정한다. 선정된 특징을 이용해 LDA, QDA, 나이브 베이즈, KNN, SVM 등 여러 분류기로 인도 히트곡을 1990‑1999년대와 2000‑2014년대로 구분함으로써 지난 10년간 청취자 취향 변화가 통계…
저자: Anish Acharya
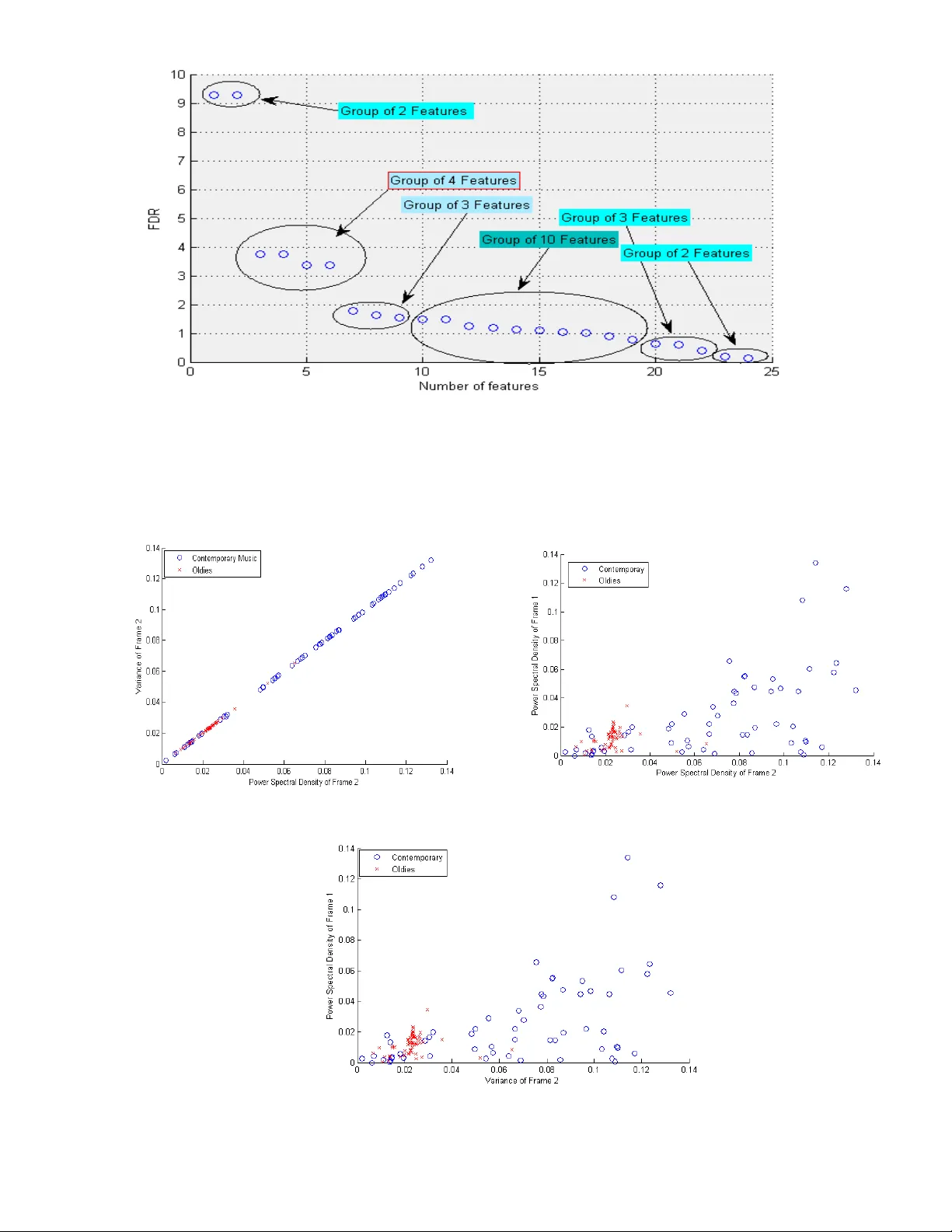
본 논문은 음악 신호를 시간 영역에서 트라페조이드 형태의 envelope을 가진다는 일반적 인식을 출발점으로 삼는다. 저자는 이 envelope을 세 구간, 즉 Opening(시작), Stanzas(전개), Closing(종결)으로 나누고, 각 구간에 대해 8가지 단순 통계량—평균, 분산, 왜도, 첨도, 초왜도, 초첨도, 파노 팩터, 파워 스펙트럼 밀도—을 계산한다. 이렇게 하면 전체 24개의 후보 특징이 생성된다.
데이터셋은 인도 히트곡을 두 시기로 구분한 것으로, 1985‑1999년(구시대)와 2000‑2014년(현시대) 각각 약 350곡을 무작위로 선정하였다. 각 곡은 동일한 비율(첫 5 %를 Opening, 중간 90 %를 Stanzas, 마지막 5 %를 Closing)으로 구분되었으며, 이 비율은 실험을 통해 최적이라고 판단된 값이다.
특징 선택 단계에서는 먼저 피셔 판별비(Fisher Discriminant Ratio, FDR)를 이용해 각 특징의 클래스 구분력을 정량화한다. 이후 주성분 분석(PCA)을 수행해 고유값 순으로 주요 성분을 추출하고, 동일한 순차 전진 선택(Sequential Forward Selection, SFS) 알고리즘을 적용한다. 이렇게 두 가지 경로(원시 FDR 기반, PCA‑FDR 기반)에서 최종적으로 선택된 소수의 특징을 사용한다.
분류기 부분에서는 총 12가지 모델을 실험한다. 선형 판별(LDA), 이차 판별(QDA), 나이브 베이즈, 거리 기반 K‑Nearest Neighbor(KNN) (유클리드, 시티 블록, 코사인, 상관계수 등 다양한 거리 함수), 그리고 선형·다항·RBF 커널을 갖는 서포트 벡터 머신(SVM)이다. 각 모델은 500‑fold Monte‑Carlo 교차 검증을 통해 평가되었으며, 정확도, 정밀도, 재현율, F1 점수 등을 보고한다.
실험 결과, 특히 SVM(RBF)와 LDA가 85 % 이상의 정확도를 기록했으며, 일부 모델은 90 %에 근접하는 성능을 보였다. 이는 단순 통계량만으로도 두 시기의 히트곡을 효과적으로 구분할 수 있음을 시사한다. 저자는 이를 바탕으로 “지난 10년간 인도 청취자들의 음악적 취향이 통계적으로 변했다”는 결론을 내린다.
논문의 주요 기여는 다음과 같다. 첫째, 복잡한 음향 특징(예: MFCC, Chroma) 대신 계산 비용이 낮은 통계량만으로도 높은 분류 성능을 달성할 수 있음을 증명하였다. 둘째, 전체 신호를 세 구간으로 나누어 구간별 특징을 추출함으로써, 동일한 통계량이라도 구간에 따라 구분력이 크게 달라질 수 있음을 보여준다. 셋째, 피처 선택에 FDR과 PCA를 결합한 두 단계 접근법을 제시하고, 이를 SFS와 연계해 최적 특징 집합을 자동으로 도출한다. 넷째, 500‑fold Monte‑Carlo 교차 검증이라는 대규모 검증 절차를 통해 결과의 통계적 신뢰성을 확보하였다.
하지만 몇 가지 비판점도 존재한다. 트라페조이드 형태 가정은 직관적이지만, 실제 다양한 장르와 곡 구조에 대해 정량적 검증이 부족하다. 구간을 고정 비율(5 %·90 %·5 %)로 나누는 방법은 곡마다 다른 전개 속도를 무시한다는 점에서 한계가 있다. 데이터셋 규모가 작고, 인도 히트곡이라는 특수 도메인에 국한돼 있어 다른 문화권이나 장르에 대한 일반화가 어렵다. 또한 기존의 복합 음향 특징과 직접 비교하지 않아, 제안된 방법이 실제 응용(예: 음악 추천, 자동 장르 분류)에서 경쟁력이 있는지 판단하기 어렵다. 피처 선택 과정에서 선택된 특징이 음악적 의미와 어떻게 연결되는지에 대한 해석도 부족하다. 마지막으로 논문 전체에 걸쳐 오탈자와 비표준 용어가 다수 존재해 재현성을 저해할 가능성이 있다.
결론적으로, 이 연구는 “간단한 통계량 + 구간 분할”이라는 새로운 아이디어를 제시하고, 제한된 실험 환경에서 높은 분류 정확도를 달성했지만, 가정의 보편성 검증, 데이터 규모 확대, 기존 방법과의 비교, 그리고 결과 해석 측면에서 추가 연구가 필요하다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기