효율적인 방 시뮬레이터 구현으로 딥 뉴럴 네트워크 음성 모델 학습 가속
본 논문은 구글의 기존 Room Simulator가 CPU 사용량의 80%를 차지하던 문제를 해결하기 위해 OLA(Overlap‑Add) 기반 필터링과 FFTW3 라이브러리를 활용한 고속 구현을 제안한다. 또한 RIR(방 임펄스 응답) 길이를 20 dB 이하로 잘라도 인식 정확도에 영향을 주지 않음을 실험적으로 확인하였다. 결과적으로 CPU 사용량을 9.7 % 수준으로 낮추고, 단일 머신에서 22.4배, 구글 분산 학습 인프라에서는 37.3배의…
저자: Chanwoo Kim, Ehsan Variani, Arun Narayanan
본 논문은 구글 홈 및 음성 검색 시스템에서 사용되는 대규모 방 시뮬레이터(Room Simulator)의 연산 효율성을 크게 개선한 연구이다. 기존 시스템은 이미지 메서드 기반으로 수천 개의 가상 방을 생성하고, 각 방에 대해 다중 마이크·다중 소스 조합으로 RIR을 계산한다. 평균 RIR 길이는 0.243 초(≈3,893 샘플)이며, 평균 음성 신호 길이는 7.31 초(≈116,991 샘플)이다. 이러한 파라미터로 직접 시간 영역 컨볼루션을 수행하면 2.32 × 10⁹개의 실수 곱셈이 필요해 CPU 부하가 과도하게 발생한다.
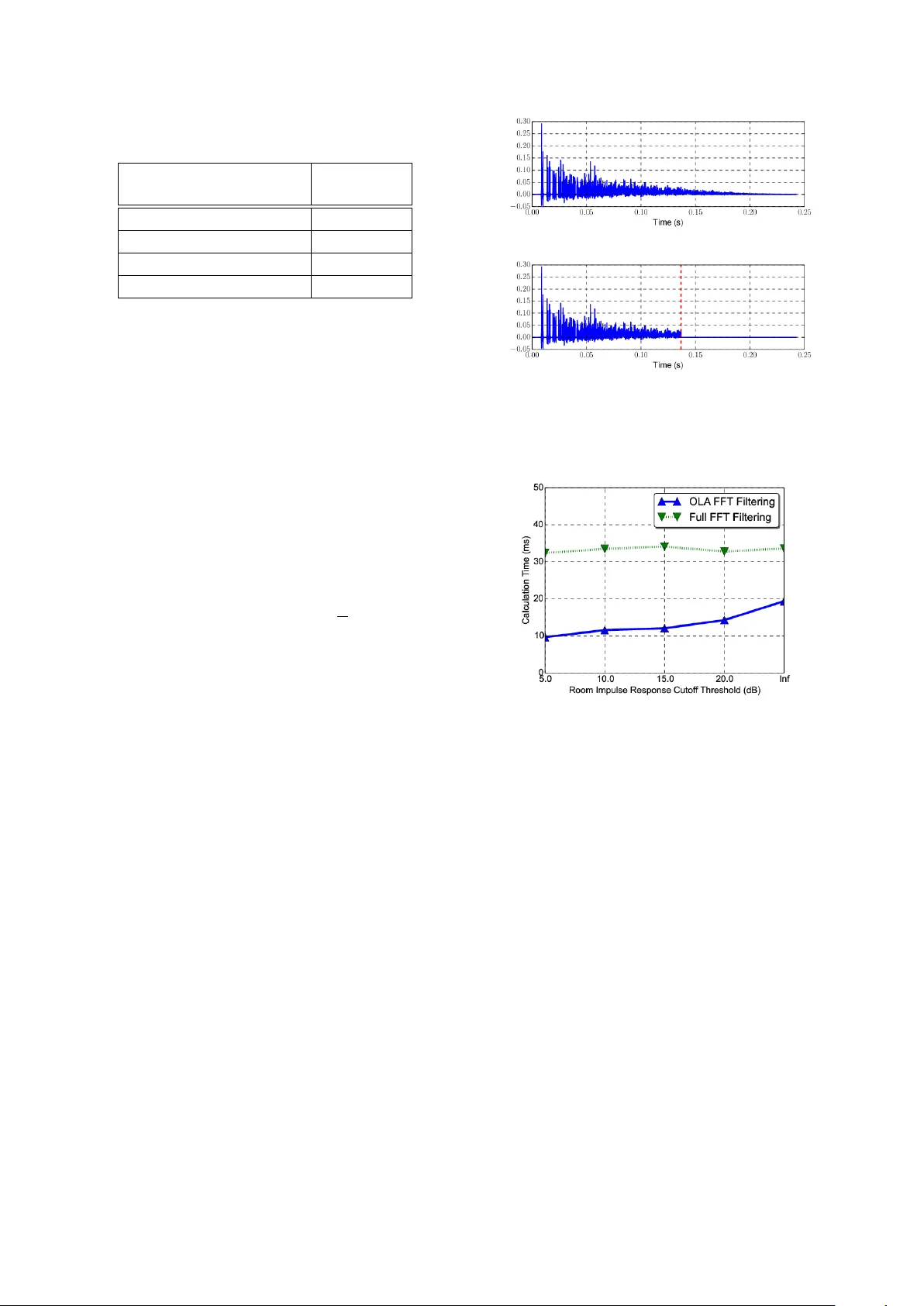
이를 해결하기 위해 저자들은 두 가지 핵심 기술을 도입했다. 첫 번째는 FFTW3 라이브러리의 실수‑FFT를 활용한 고속 변환이다. 기존에 사용하던 Kiss‑FFT 기반 구현보다 약 3배 빠른 성능을 보였다. 두 번째는 Overlap‑Add(OLA) 방식의 블록 기반 필터링이다. 입력 신호를 길이 N(2^m)인 블록으로 나누어 각 블록마다 FFT‑IFFT와 복소 곱을 수행하고, 겹치는 구간을 합산한다. 이 방법은 전체 연산량을 Cₒₗₐ = I·J·⌈Nₓ/(N−Nₕ+1)⌉·(4N·log₂N+2N)+2N·log₂N 로 표현할 수 있으며, 최적 블록 크기 N=2¹⁴일 때 평균 실수 곱셈 수는 5.08 × 10⁷으로 기존 FFT‑Convolution 대비 약 2.7배 효율적이다.
또한 저자들은 RIR의 꼬리 부분을 전력 기준으로 절단하는 간단한 전처리 기법을 제안한다. 전력 임계값 pₜₕ = max(h²)·10^{−η/10} 로 정의하고, η=20 dB 이하로 절단하면 평균 RIR 길이가 크게 감소하면서도 인식 정확도에 부정적 영향을 주지 않는다. 반면 η=5 dB 이하로 절단하면 far‑field 재녹음 테스트에서 WER가 20 % 이상 상승하는 등 성능 저하가 뚜렷하게 나타난다. 이는 훈련 데이터에 충분히 긴 잔향을 포함시켜야 실제 환경에서의 강인성을 확보할 수 있음을 의미한다.
실험은 22 백만(≈18,000 시간) 음성 utterance와 3 백만 개의 방 설정을 사용해 수행되었다. 모델은 5‑layer LSTM(각 768 유닛)과 8,192개의 소프트맥스 노드로 구성되었으며, 128‑dim log‑Mel 피처를 4‑frame 스택(512‑dim) 후 3배 다운샘플링하여 입력했다. 결과는 다음과 같다.
1. **CPU 사용량**: 기존 시스템에서 Room Simulator가 전체 CPU 사용량의 80 %를 차지했으나, FFTW3‑OLA + 20 dB RIR 절단 적용 시 전체 파이프라인에서 9.69 %로 감소했다.
2. **속도 향상**: 단일 데스크톱 머신에서 평균 처리 시간이 320.8 ms → 19.4 ms(≈22.4배)로 단축되었으며, 구글 Borg 클러스터에서는 전체 시뮬레이션 파이프라인이 37.3배 가속되었다.
3. **인식 정확도**: 원본 테스트 셋에서는 WER 11.70 % → 11.20 %(MTR 적용)로 약간 개선되었고, 시뮬레이션된 노이즈 셋 A/B에서는 20 dB 절단이 오히려 약간의 WER 감소를 보였다. 반면 5 dB 이하 절단 시에는 특히 실제 하드웨어에서 재녹음한 far‑field 셋에서 WER가 20 % 이상 급증했다.
결론적으로, OLA 기반 FFT 필터링과 RIR 길이 최적화는 대규모 음성 데이터 증강의 연산 비용을 크게 낮추면서도 모델 성능을 유지하거나 향상시킬 수 있음을 입증한다. 이러한 접근은 CPU‑GPU 혼합 학습 환경에서 특히 유용하며, 향후 실시간 음향 시뮬레이션, 가상 현실 오디오, 그리고 다른 대규모 오디오 데이터 증강 작업에도 적용 가능할 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기