딥 뉴럴 네트워크의 특징 학습이 말인식 성능을 좌우한다
본 논문은 깊은 신경망(DNN)이 얕은 네트워크와 전통적인 GMM 기반 모델보다 우수한 이유를 내부 표현의 변이 불변성에 있다고 설명한다. 네트워크 깊이가 증가할수록 입력의 작은 교란에 대한 민감도가 감소하고, 충분히 다양한 학습 데이터를 제공하면 화자, 대역폭, 환경 잡음 등에 강인한 특징을 자동으로 학습한다. 그러나 훈련 데이터와 크게 다른 테스트 샘플에 대해서는 일반화가 어려움을 보인다. 실험을 통해 DNN이 적은 적응 없이도 GMM 대비…
저자: Dong Yu, Michael L. Seltzer, Jinyu Li
본 논문은 딥 뉴럴 네트워크(DNN)가 기존의 얕은 신경망 및 가우시안 혼합 모델(GMM)보다 대규모 어휘 음성 인식 작업에서 현저히 우수한 성능을 보이는 원인을 탐구한다. 저자들은 DNN이 내부에서 학습하는 특징 표현이 다양한 음성 변이에 대해 강인하고 변이 불변(invariant)하다는 가설을 제시하고, 이를 실험적으로 검증한다.
**1. 서론 및 배경**
음성 인식은 화자 억양, 방언, 발음, 말하기 속도, 감정 상태, 환경 잡음, 리버버레이션, 마이크 종류 등 수많은 비정상적·비정상적인 변이 때문에 어려운 문제이다. 전통적인 HMM‑GMM 파이프라인은 VTLN, MLLR, VTS 등 복잡한 적응 기법을 통해 이러한 변이를 보정하지만, 적응 데이터가 충분하지 않거나 실시간 요구가 있는 경우에는 한계가 있다. 최근 CD‑DNN‑HMM(컨텍스트‑디펜던트 딥 뉴럴 네트워크와 HMM 결합) 접근법이 강력한 대안으로 부상했으며, 여러 연구에서 대규모 데이터셋에 대해 뛰어난 결과를 보고하고 있다.
**2. DNN의 구조적 해석**
논문은 DNN을 “비선형 특징 변환 + 로그선형 분류기”라는 두 단계 모델로 재구성한다. 입력 x는 L개의 은닉층을 거치며 v₁, v₂, …, v_L 로 변환되고, 최종 층에서는 softmax를 통해 클래스 사후확률 p(y|x)를 출력한다. 은닉층은 이진 유닛 hᶫ 로 모델링되며, 각 층의 가중치 Wᶫ와 편향 aᶫ을 통해 선형 변환 후 시그모이드(또는 ReLU 등) 비선형 함수를 적용한다. 이때, 은닉층을 고정하고 softmax만 학습하면 조건부 최대 엔트로피(MaxEnt) 모델과 동일하므로, DNN 전체는 특징 학습과 분류기를 동시에 최적화하는 구조가 된다.
**3. 깊이가 성능에 미치는 영향**
표 1과 그림 2를 통해 네트워크 깊이가 증가할수록 WER이 지속적으로 감소함을 보여준다. 1층(2048 유닛)에서는 24.2%의 WER을 기록했지만, 7층(각 2048 유닛)에서는 17.1%까지 낮아진다. 동일 파라미터 수를 가진 얕은 MLP(예: 1×16k)와 비교했을 때, 깊은 네트워크가 현저히 우수함을 확인한다. 다만, 9층 이후에는 개선 폭이 미미해 포화 현상이 나타난다. 이는 깊이가 증가함에 따라 비선형 변환이 충분히 복잡해져 입력을 효과적으로 분리하지만, 지나친 깊이는 학습·추론 비용만 증가시키기 때문이다.
**4. 특징의 변이 불변성**
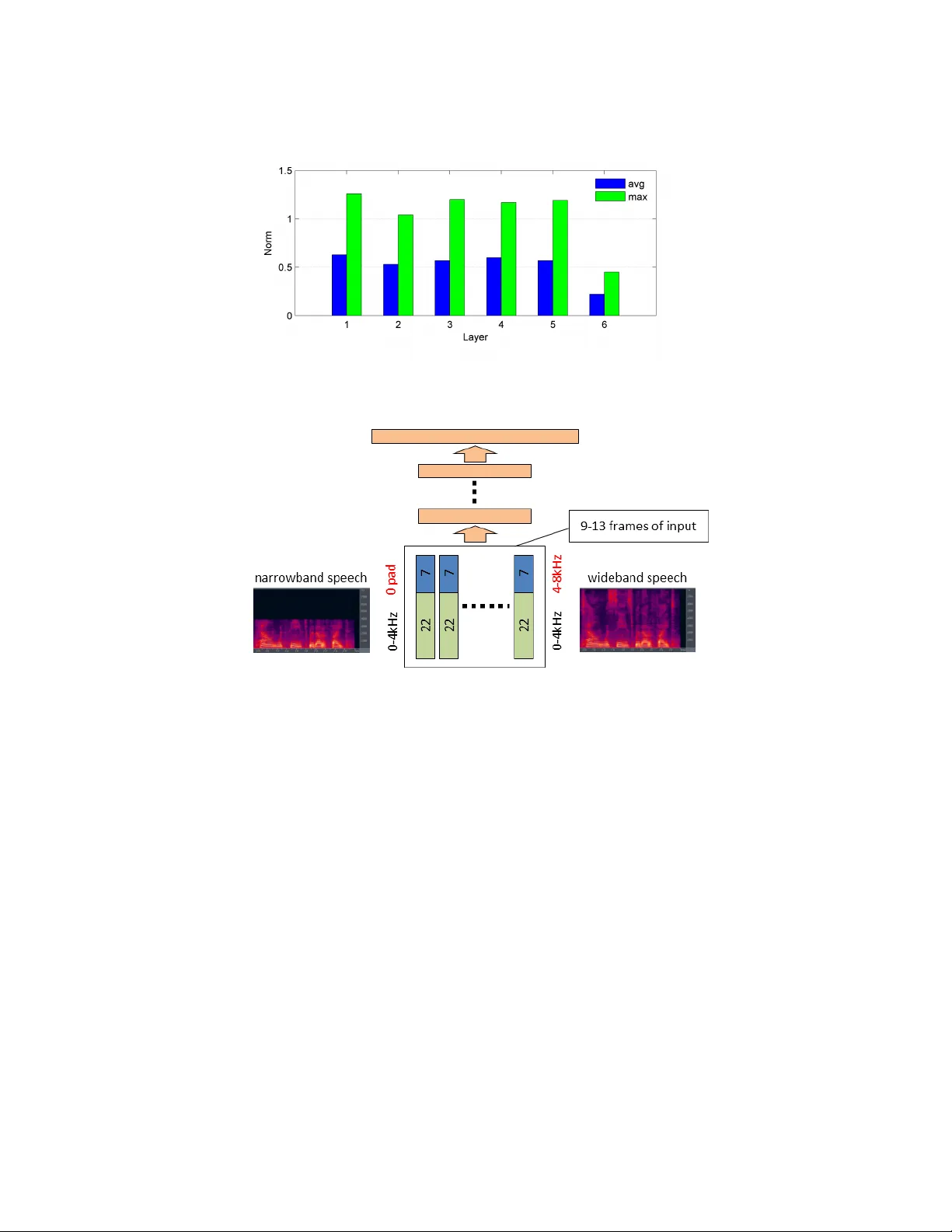
수식 2를 통해 작은 입력 교란 δ가 각 층을 통과하면서 가중치 행렬의 작은 값과 시그모이드의 미분(≤0.25) 때문에 점차 축소된다는 이론적 근거를 제시한다. 실험적으로 6×2k DNN에서 98% 이상의 가중치가 0.5 이하이며, 활성화 비율이 낮아(그림 1) 대부분의 뉴런이 포화되지 않는다. 따라서 높은 층일수록 입력 변동에 대한 민감도가 감소하고, 클래스 경계 근처에서는 오히려 변동이 확대돼 판별력이 유지된다.
**5. 학습 데이터 다양성의 중요성**
“Learning by seeing” 섹션에서는 작은 교란에 대해서는 불변성이 확보되지만, 훈련 데이터와 크게 다른 도메인(예: 대역폭 차이)에서는 성능이 급격히 저하된다는 점을 강조한다. 혼합 대역폭 실험에서 넓은 대역폭(16 kHz)만으로 학습한 DNN은 8 kHz 테스트에서 53.5%의 WER을 보였지만, 16 kHz와 8 kHz 데이터를 모두 포함해 재학습하면 두 조건 모두 28~29% 수준으로 크게 개선된다. 층별 유클리드 거리와 최종 KL 발산을 분석한 결과, 혼합 데이터로 학습한 DNN은 높은 층으로 갈수록 두 대역폭 간 차이가 크게 감소함을 확인한다. 이는 DNN이 학습 데이터에 포함된 변이를 ‘무시할 수 있는 변이’로 인식하고, 내부 표현에서 억제한다는 의미이다.
**6. 화자 변이에 대한 강건성**
화자 적응 기법인 VTLN과 fMLLR을 DNN 입력에 직접 적용할 수 있지만, 논문은 DNN 자체가 화자 변이에 대해 내재적으로 강건함을 보인다고 주장한다. 실험에서는 화자 적응 없이도 DNN이 GMM‑based 시스템과 동등하거나 더 나은 WER을 달성했으며, 이는 깊은 비선형 변환이 화자별 스펙트럼 차이를 효과적으로 정규화하기 때문이다.
**7. 환경 잡음에 대한 강건성 (Aurora 4)**
노이즈 및 채널 변이가 포함된 Aurora 4 데이터셋에서도 DNN은 별도의 환경 적응 없이 GMM‑HMM 대비 경쟁력 있는 성능을 기록한다. 이는 앞서 논의한 ‘특징 불변성’이 잡음과 채널 왜곡에도 적용된다는 증거이며, 복잡한 VTS나 MLLR 같은 전통적 적응 절차를 생략할 수 있음을 시사한다.
**8. 실용적 시사점 및 한계**
- **장점**: 깊은 네트워크는 파라미터 효율성이 높아 얕은 대규모 MLP보다 적은 연산으로 높은 정확도를 제공한다. 또한, 별도 적응·정규화 파이프라인이 필요 없어 시스템 복잡도와 실시간 지연을 크게 감소시킨다.
- **한계**: 훈련 데이터에 포함되지 않은 변이에 대해서는 일반화가 어려워, 데이터 수집 단계에서 다양한 화자·채널·노이즈·대역폭 조건을 충분히 커버해야 한다.
- **미래 연구**: 변이 불변성을 보다 일반화하기 위한 데이터 증강, 도메인 적응을 위한 사전학습/전이학습, 그리고 비선형 변환의 해석 가능성을 높이는 방법론이 필요하다.
결론적으로, DNN의 깊이는 비선형 특징 변환 능력을 강화해 입력 교란에 대한 불변성을 자연스럽게 학습하게 하며, 이는 전통적인 GMM‑HMM 대비 뛰어난 음성 인식 성능을 가능하게 한다. 그러나 “보지 못한” 변이에 대해서는 여전히 한계가 존재하므로, 충분히 대표적인 변이를 포함한 학습 데이터 확보가 성공적인 적용의 핵심이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기