멀티채널 키워드 스포팅을 위한 청각주의 기반 엔드투엔드 모델
본 논문은 마이크 어레이 입력을 직접 학습 목표인 키워드 검출에 최적화하는 주의(attention) 메커니즘을 도입한 엔드투엔드 모델을 제안한다. 단일채널 전처리 대비 모든 테스트 환경에서 정확도가 향상되었으며, 다중 과제 학습, 전이 학습, 그리고 다중 목표 스펙트럼 매핑을 결합하면 -20 dB SNR의 극한 잡음 상황에서도 0.1 FA/h당 깨우기율이 30 % 절대적으로 상승한다.
저자: Haitong Zhang, Junbo Zhang, Yujun Wang
본 논문은 스마트폰·스마트 스피커 등에서 사용되는 “키워드 스포팅”(KWS) 시스템을 다중 마이크 어레이 입력에 직접 적용할 수 있는 새로운 엔드투엔드 모델을 제안한다. 기존 KWS는 보통 단일 채널 음성에 대해 설계되었으며, 다중 채널을 활용하려면 빔포밍·에코 캔슬레이션(AEC) 등 전처리 단계가 필요했다. 그러나 이러한 전처리 단계는 최종 검출 목표와 독립적으로 설계되기 때문에 최적화가 어려워 잡음이 심한 환경에서 성능이 급격히 저하되는 문제가 있었다.
저자들은 이러한 한계를 극복하기 위해 6채널(각 40차원 FBANK) 입력을 소프트 어텐션 메커니즘을 통해 가중합하고, 이를 단일 채널 특징 x′_t 로 변환한다. 어텐션 가중치는 각 채널별 중요도를 학습하며, softmax 정규화를 거쳐 6차원 벡터 A_t 를 만든다. 이렇게 얻어진 x′_t 는 GRU 기반 인코더(2층 GRU + 1층 FC)로 전달되어 시퀀스‑투‑시퀀스 방식으로 전체 키워드 존재 확률을 프레임 단위로 예측한다. 예측값은 n프레임(논문에서는 n=12) 평균을 통해 스무딩되며, 최종 판단에 사용된다.
다음으로, 모델의 일반화 능력을 높이기 위해 두 가지 보조 학습 전략을 도입한다. 첫 번째는 스펙트럼 매핑을 보조 과제로 설정하는 다중 과제 학습이다. 여기서는 다채널 입력을 전통적인 전처리(빔포밍·AEC)로 얻은 단일채널 스펙트럼으로 매핑하도록 학습한다. 손실 함수는 L_total = α·L_KWS + (1‑α)·L_map 형태이며, α는 0.5로 설정한다. 실험 결과, 훈련·테스트 데이터가 유사한 경우(예: 깨끗한 데이터) 매핑 과제가 약간의 정확도 향상을 제공한다. 그러나 잡음이 심한 테스트에서는 매핑 목표가 훈련 잡음과 불일치해 오히려 성능이 저하된다.
두 번째 전략은 전이 학습과 다중 목표 스펙트럼 매핑을 결합한 것이다. 먼저 깨끗한 데이터로 사전 학습된 어텐션 모델을 초기 파라미터로 사용하고, 인공적으로 SNR ≈ ‑10 dB인 잡음 데이터를 추가해 미세조정한다. 여기서 한 가지 목표(청음)만을 매핑하는 경우는 잡음 환경에서 큰 이득을 보지 못한다. 따라서 저자들은 세 가지 목표(청음, +5 dB, +10 dB)를 동시에 학습하도록 손실을 L_total = α·L_KWS + β·L_map_clean + θ·L_map_noise1 + δ·L_map_noise2 로 정의하고, α = 0.5, β = 0.2, θ = 0.2, δ = 0.1 로 설정한다. 이 다중 목표 매핑은 모델이 다양한 SNR 조건을 동시에 학습하게 하여, 실제 테스트에서 -20 dB 수준의 극심한 잡음에도 견디는 능력을 부여한다.
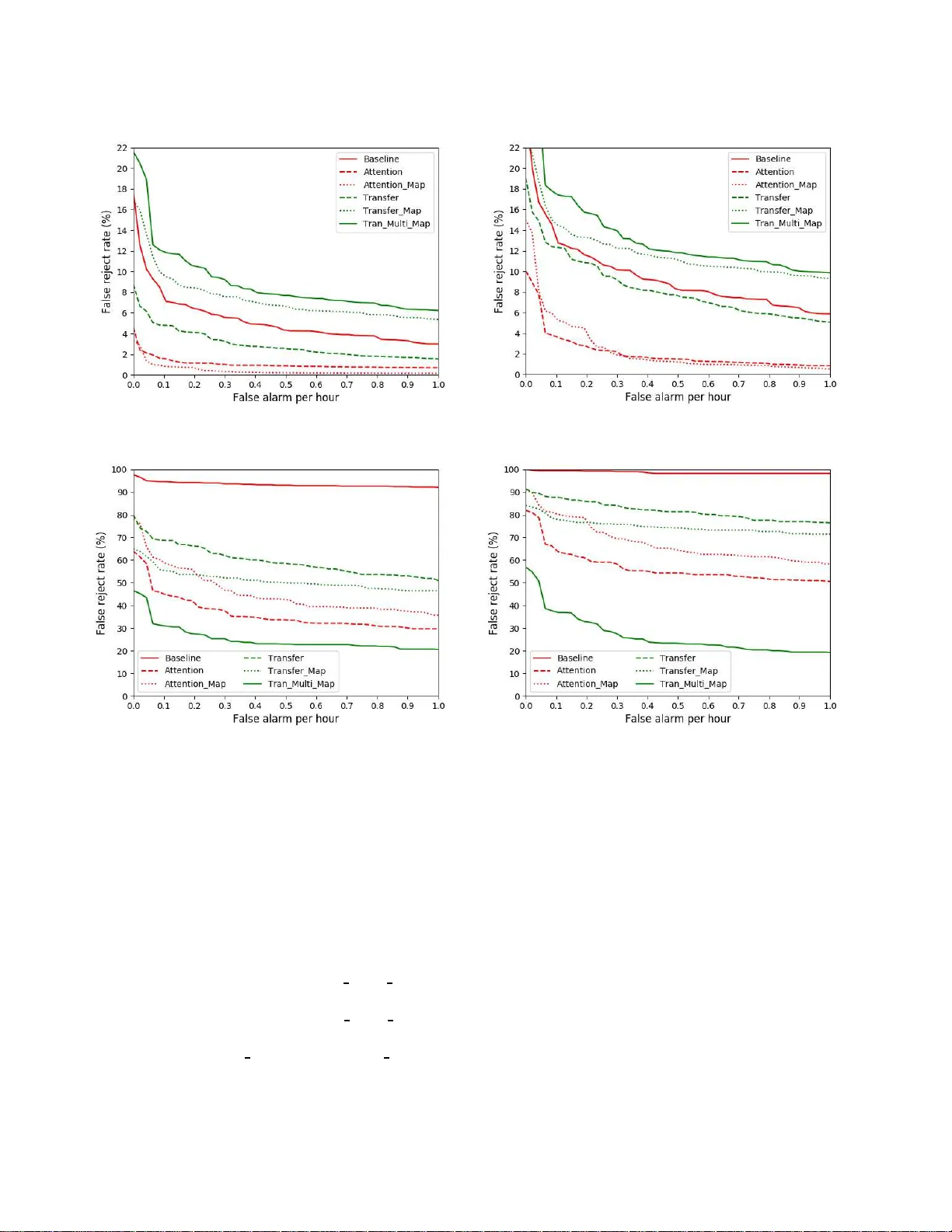
실험은 다음과 같이 구성되었다. 훈련 데이터는 240 k개의 키워드 발화(에코 포함)와 200 시간의 비키워드 음성으로 구성되었으며, 검증용으로 10 %를 사용했다. 테스트는 깨끗한 비에코·에코 데이터와 두 종류의 잡음 데이터(하드‑노이즈: SNR ≈ ‑20 dB, 이지‑노이즈: SNR ≈ ‑18 dB)로 이루어졌다. 베이스라인은 7채널 입력에 빔포밍·AEC를 적용한 전통적인 전처리 방식이며, 특징은 PCEN 기반 40차원 FBANK이다.
결과는 다음과 같다. 어텐션 기반 모델은 베이스라인 대비 모든 테스트 셋에서 0.5 FA/h당 정확도가 4 %~7 % 상승했으며, 특히 잡음 데이터에서는 하드‑노이즈에서 40 %, 이지‑노이즈에서 60 %의 상대적 향상을 보였다. 다중 과제 학습(단일 매핑) 모델은 깨끗한 데이터에서 어텐션보다 약간 우수했지만, 잡음 데이터에서는 성능이 떨어졌다. 전이 학습만 적용한 모델도 잡음 데이터에서 어텐션보다 못했지만, 전이 학습 + 다중 목표 매핑(Tra Multi Map) 모델은 하드‑노이즈에서 0.5 FA/h당 깨우기율을 기존 어텐션 대비 30 % 절대적으로, 이지‑노이즈에서는 10 % 절대적으로 향상시켰다.
결론적으로, 마이크 어레이 입력을 전처리 없이 직접 어텐션으로 통합하는 접근법이 기존 빔포밍·AEC 기반 전처리보다 뛰어난 성능을 제공한다. 또한, 다중 목표 스펙트럼 매핑과 전이 학습을 결합하면 극한 잡음 환경에서도 강인한 KWS 시스템을 구현할 수 있음을 입증한다. 이 연구는 향후 음성 인식 및 음성 기반 인터페이스에서 전처리‑비의존형 딥러닝 모델 설계에 중요한 시사점을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기