짧은 발화용 딥러닝 i벡터 매핑으로 화자 검증 성능 향상
본 논문은 짧은 발화에서 발생하는 i벡터 변동성을 완화하기 위해, DNN 기반 i벡터 추출과 두 단계·단일 단계 자동인코더(Auto‑Encoder) 기반 비선형 매핑 기법을 제안한다. NIST SRE 2010과 SITW 데이터셋에서 최대 28.43% 상대 EER 개선을 달성하였다.
저자: Jinxi Guo, Ning Xu, Kailun Qian
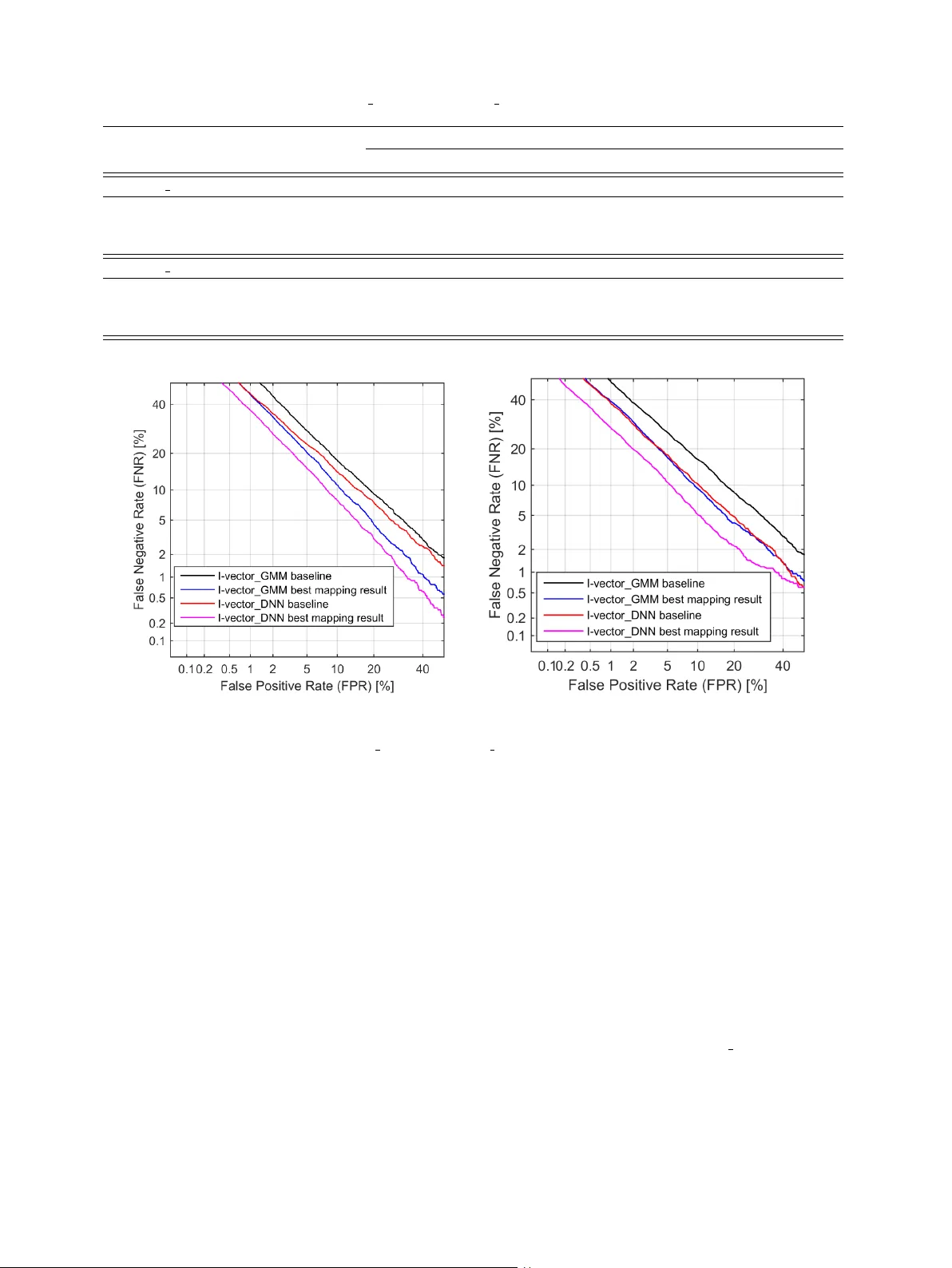
본 논문은 텍스트‑독립 화자 인증 시스템에서 짧은 발화(1~5 초)로 인한 성능 저하 문제를 다루며, 두 가지 주요 연구 흐름을 제시한다. 첫 번째 흐름은 기존 i벡터 추출 방법인 GMM‑UBM과 DNN‑UBM을 비교하여, DNN‑UBM이 모든 발화 길이에서 우수함을 확인한다. GMM‑UBM은 비지도 학습으로 훈련된 혼합 가우시안 모델을 사용해 충분통계(Nc, Fc)를 계산하고, 총변동 행렬 T를 통해 저차원 i벡터 w를 추정한다. 반면 DNN‑UBM은 TDNN 기반의 senone 분류기를 이용해 각 프레임에 대한 음소 posterior P(c|y_t,Θ)를 얻어, 보다 정확한 충분통계를 제공한다. 실험 결과, 짧은 발화일수록 두 방법 모두 성능이 급격히 저하되지만, DNN‑UBM 기반 i벡터가 평균 2~3 % 낮은 EER을 기록한다.
두 번째 흐름은 짧은 발화 i벡터를 장시간 발화 i벡터로 매핑하는 비선형 변환 모델을 설계한다. 저자들은 직접 회귀 DNN을 학습하면 과적합이 발생한다는 점을 지적하고, 자동인코더(Auto‑Encoder)를 활용한 두 가지 매핑 전략을 제안한다.
1) **두 단계 방식(DNN1)**: 짧은 i벡터 w_s와 대응되는 긴 i벡터 w_l을 연결(concatenation)한 z =
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기