언더디터미네이션 소스 분리를 위한 일반화된 다채널 변분 오토인코더
본 논문은 기존 MNMF·ILRMA에서 사용하던 NMF 기반 스펙트로그램 모델을 딥러닝 기반 CVAE로 대체한 MVAE를, 마이크 수보다 소스가 많은 언더디터미네이션 상황에서도 적용할 수 있도록 일반화한 GMVAE 프레임워크를 제안한다. 실험에서는 2개의 마이크로 3개의 음성 소스를 분리했을 때, 기존 MNMF 대비 SDR·SIR·SAR 지표에서 모두 우수한 성능을 보였다.
저자: Shogo Seki, Hirokazu Kameoka, Li Li
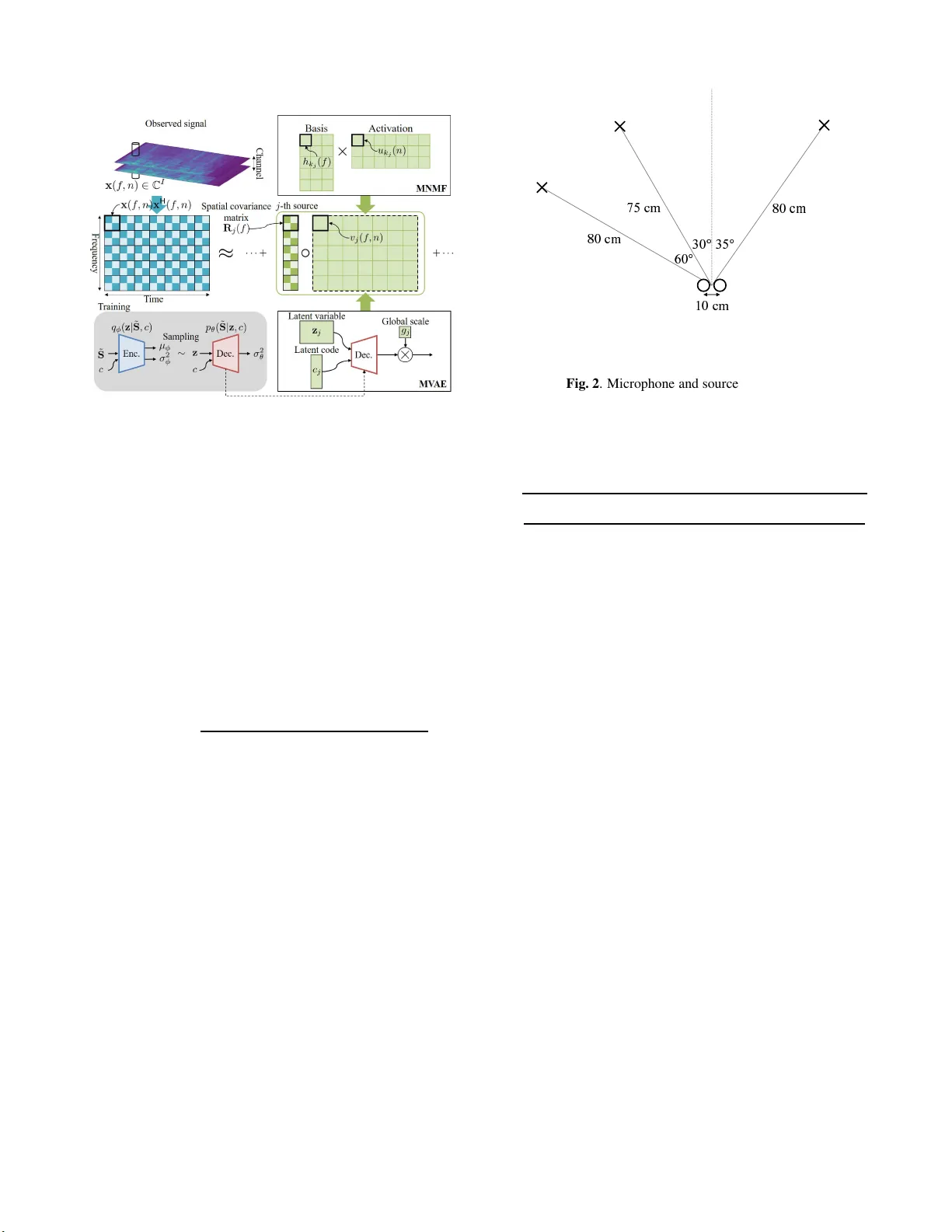
본 논문은 다채널 오디오 소스 분리 문제를 언더디터미네이션(마이크보다 소스가 많은) 상황에서도 효과적으로 해결하기 위해, 기존의 MNMF·ILRMA 프레임워크에 딥러닝 기반의 조건부 변분 오토인코더(CVAE)를 도입한 Generalized MVAE(GMVAE)라는 새로운 모델을 제안한다.
1. **배경 및 문제 정의**
- 다채널 소스 분리는 관측 마이크 신호 x(f,n) 을 복소 가우시안 로컬 모델(LGM)로 가정하고, 소스 s(f,n) 의 분산 v_j(f,n) 을 모델링한다.
- MNMF와 그 특수 형태인 ILRMA는 v_j(f,n) 을 NMF 형태(선형 결합 템플릿)로 제한한다. 이 제한은 스펙트로그램이 비선형적이거나 복잡한 경우 모델링 오류를 초래한다.
- MVAE는 이러한 한계를 극복하기 위해 사전 학습된 CVAE를 사용해 v_j(f,n) 을 비선형 함수 g_j σ_θ²(f,n;z_j,c_j) 로 대체한다. CVAE는 입력 스펙트로그램 S̃와 클래스 라벨 c (예: 화자 ID)를 조건으로 하여 잠재 변수 z 와 디코더 파라미터 θ 를 통해 복소 가우시안 분산을 생성한다.
2. **GMVAE 모델 설계**
- 기존 MVAE는 결정적(마이크 수 = 소스 수) 혼합에만 적용 가능했으나, GMVAE는 이를 일반화해 I (마이크) < J (소스)인 경우에도 적용한다.
- 로그 가능도 L = −log p(X|A,V) 에 대한 MM(majorization‑minimization) 기법을 사용한다. 보조 변수 P_j(f,n) 과 K(f,n) 을 정의해 L 을 상한 L̃ 으로 변형하고, L̃ 을 R_j, g_j, (z_j,c_j) 에 대해 교대로 최소화한다.
- **공간 공분산 R_j 업데이트**: 알제브라적 리카티 방정식 R_j Ψ_j R_j = Ω_j (식 12‑14) 을 풀어 얻는다. 이는 MNMF와 동일한 형태이며, 수치적 안정성을 위해 대칭화와 작은 정규화 항 εI 을 추가한다.
- **잠재 변수와 라벨 업데이트**: z_j 와 c_j 은 디코더 θ 에 대한 손실을 역전파로 최적화한다. c_j 는 softmax 레이어를 통해 확률 분포(합 1)로 강제한다. 이는 라벨이 원‑핫 형태일 때 다중 클래스 구분을 가능하게 한다.
- **전역 스케일 g_j 업데이트**: 식 (34)와 같이 닫힌 형태의 곱셈 업데이트를 수행한다. 이는 디코더가 출력하는 분산 σ_θ² 와 현재 추정된 공간 공분산 R_j 사이의 일치도를 반영한다.
3. **알고리즘 흐름**
1) CVAE(인코더 φ, 디코더 θ)를 라벨링된 스펙트로그램 데이터로 사전 학습한다(식 29).
2) 초기값 R_j, g_j, (z_j,c_j) 를 무작위 혹은 사전 추정값으로 설정한다.
3) 각 반복에서 (a) R_j 업데이트, (b) (z_j,c_j) 백프로파게이션, (c) g_j 업데이트를 순차적으로 수행한다.
4) 보조 변수 P_j, K 를 식 (31‑32)로 갱신하고, 수렴 기준(로그 가능도 변화)까지 반복한다.
4. **실험 설정**
- 데이터: VCC 2018의 4명 화자(2여성, 2남성) 음성 샘플을 사용, 각 화자당 81문장을 학습, 35문장을 평가에 사용.
- 혼합 시나리오: 2채널·3소스(예: SF1+SF2+SM2 등) 10가지 조합을 생성.
- 전처리: 16 kHz 샘플링, 256 ms 프레임, 128 ms 홉.
- CVAE 구조: 3‑layer 전방 컨볼루션 + gated linear unit, 3‑layer 역방향 디컨볼루션 + GLU, 최적화는 Adam(β1=0.9, β2=0.999).
- 비교 대상: 기존 MNMF(공유 템플릿 모델)와 동일 조건 하에서 평가.
5. **결과 및 분석**
- SDR, SIR, SAR 모두에서 GMVAE가 MNMF 대비 평균 1‑2 dB 향상. 특히 화자 간 스펙트럼 차이가 큰 조합에서 큰 이득을 보였다.
- 로그 가능도 수렴 그래프는 MM 기반 업데이트가 안정적으로 수렴함을 확인.
- 라벨 c 가 정확히 제공될 경우 성능이 최적화되지만, 라벨이 부정확하거나 누락될 경우 softmax 레이어가 자동으로 확률 분포를 학습해 어느 정도 복원력을 유지한다.
6. **한계 및 향후 연구**
- CVAE 사전 학습에 라벨링된 대규모 데이터가 필요하며, 라벨이 없는 경우에는 비지도형 클러스터링과 결합한 확장이 필요.
- 현재는 모든 소스에 동일 CVAE를 공유하므로, 서로 다른 종류(음악, 잡음 등)의 소스를 동시에 처리하려면 다중 디코더 혹은 멀티태스크 학습이 요구된다.
- 실시간 적용을 위해 경량화된 네트워크 설계와 GPU 최적화가 필요하다.
결론적으로, GMVAE는 NMF 기반 모델의 선형 제한을 딥러닝 기반 비선형 모델로 대체함으로써 언더디터미네이션 상황에서도 높은 분리 성능을 달성했으며, MM 기반 수학적 프레임워크와 딥러닝의 표현력을 성공적으로 결합한 사례로 평가된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기