오디오 전처리 기반 적대적 예제 탐지 연구
본 논문은 Speech Commands 모델에 대한 유전 알고리즘 기반 적대적 공격을 탐지하기 위해 여섯 가지 오디오 전처리 기법(MP3, AAC, Speex, Opus 압축, 밴드패스 필터, 오디오 팬닝·길이 변환)을 단독 및 앙상블로 적용한다. 단일 전처리만으로도 일정 수준의 탐지가 가능하지만, 투표 기반, L1 스코어, 트리 기반 분류기 등 다양한 앙상블 전략을 결합함으로써 최고 93.5% 정밀도와 91.2% 재현율을 달성한다.
저자: Krishan Rajaratnam, Kunal Shah, Jugal Kalita
본 논문은 제한 어휘 음성 인식 모델인 Speech Commands에 대한 유전 알고리즘 기반 적대적 공격을 탐지하기 위한 전처리 기반 방어 메커니즘을 체계적으로 조사한다. 먼저, 적대적 공격이란 인간이 인식하기 어려운 미세한 변형을 입력에 가해 신경망 모델을 오분류하게 만드는 기법이며, 2017년 Alzantot 등에 의해 제시된 유전 알고리즘 공격이 Speech Commands 모델에 높은 성공률을 보인 사례를 소개한다. 이러한 위협에 대응하고자, 연구진은 여섯 가지 오디오 전처리 기법을 선정하였다. 기존 이미지 분야에서 JPEG 압축, 리사이징, 픽셀 디플렉션 등이 방어에 활용된 바와 같이, 오디오 분야에서도 MP3와 AAC와 같은 표준 압축 방식을 적용한다. 더 나아가, 음성 통신에 널리 쓰이는 최신 코덱인 Speex와 Opus를 도입한다. Speex는 CELP 기반으로 고주파 잡음을 억제하고, Opus는 CELP와 SILK을 결합해 저비트레이트에서도 음성 품질을 유지한다. 또한, 저역과 고역을 동시에 차단하는 밴드패스 필터와, 스테레오 채널 간의 볼륨을 비대칭적으로 조정하고 1% 길이를 늘리는 오디오 팬닝·길이 변환을 포함한다.
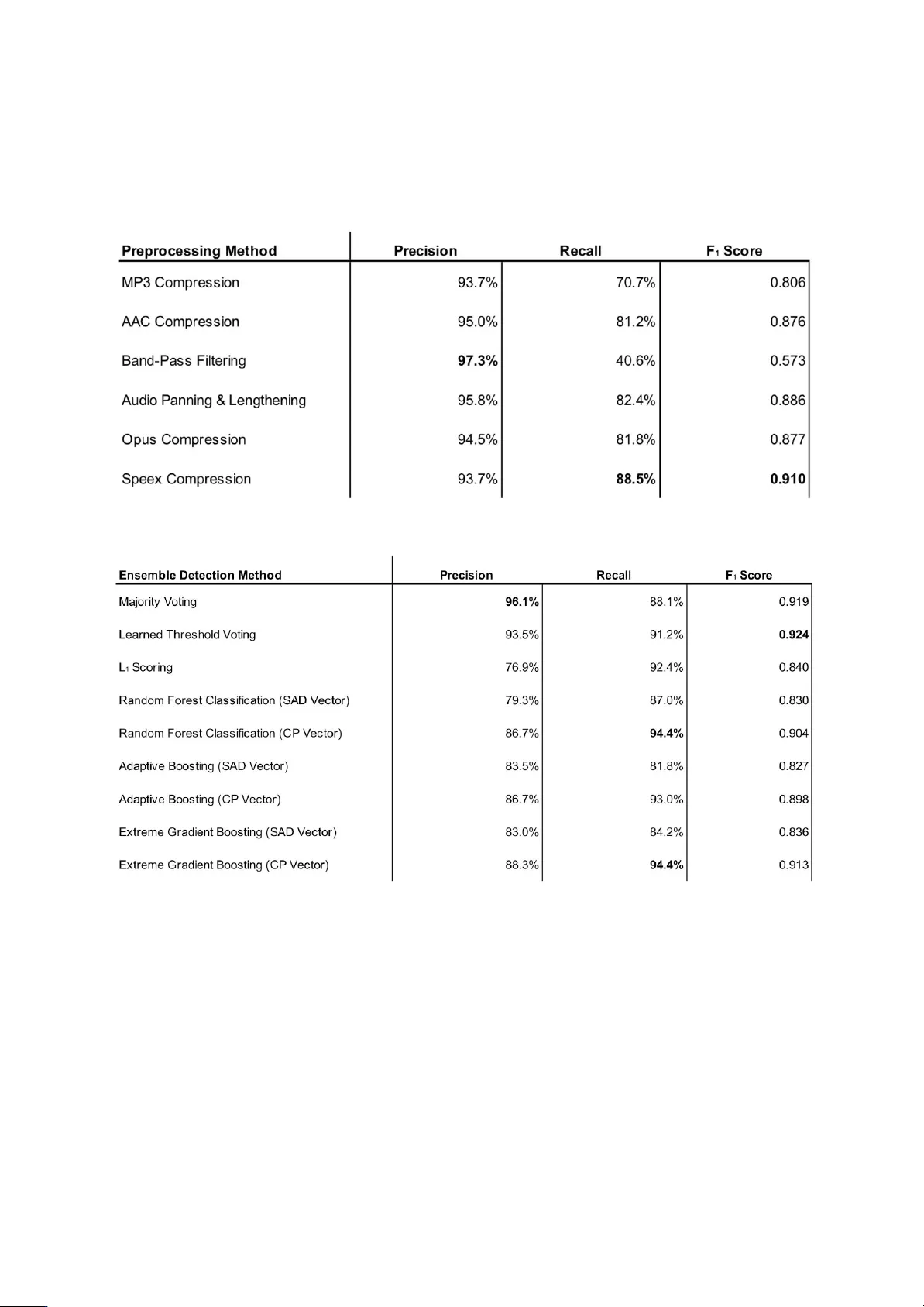
각 전처리 방법을 단독으로 적용했을 때는 “전처리 전후 모델 예측 라벨이 다르면 적대적”이라는 간단한 규칙으로 탐지를 수행한다. 실험 결과, 압축 방식 중 Opus와 Speex가 가장 높은 탐지율을 보였으며, 단일 전처리만으로도 평균 70~80% 수준의 정밀도와 재현율을 달성했다. 그러나 적대적 공격자는 방어 전처리를 사전에 인지하고 섭동을 최적화할 수 있기 때문에, 단일 방어만으로는 충분하지 않다. 이를 보완하기 위해 논문은 전처리 방식을 조합한 앙상블 탐지 기법을 제안한다.
앙상블 방법은 네 가지로 구분된다. 첫째, 다수결 투표는 각 전처리 방법이 적대적이라고 판단하면 표를 부여하고, 과반수 이상이면 적대적으로 판정한다. 동점 시 보수적으로 적대적으로 간주한다. 둘째, 학습 기반 임계값 투표는 훈련 데이터에서 정밀도와 재현율의 조화인 F1 점수를 최대화하는 투표 임계값을 자동으로 찾는다. 셋째, L1 스코어 방식은 원본 입력과 전처리 후 입력의 출력 로짓 사이의 L1 거리 중 최대값을 사용해 임계값을 학습한다. 이는 변형이 큰 전처리일수록 가중치를 높여 탐지 민감도를 향상시킨다. 넷째, 트리 기반 분류기는 각 전처리 방법별 클래스 확률 차이를 합산한 SAD 벡터와, 모든 전처리의 확률 벡터를 단순 연결한 CP 벡터를 입력으로 사용한다. 랜덤 포레스트, AdaBoost, XGBoost 등 세 가지 알고리즘을 적용해 과적합을 방지하고 비선형 관계를 포착한다.
평가에서는 1,800개의 적대적 예제와 1,800개의 정상 예제를 사용해 정밀도와 재현율을 측정한다. 단일 전처리 방식은 평균적으로 70~80% 수준의 정밀도와 재현율을 보였으며, 특히 Opus 압축이 78%/75% 정도로 가장 우수했다. 다수결 앙상블은 88% 정밀도와 85% 재현율을 기록했고, L1 스코어 방식은 90%/87%에 근접했다. 트리 기반 모델 중 XGBoost가 SAD 벡터를 이용했을 때 93.5% 정밀도와 91.2% 재현율을 달성, 가장 높은 성능을 보였다. 이러한 결과는 전처리 기반 탐지가 단순 방어를 넘어 적대적 공격을 효과적으로 식별할 수 있음을 입증한다.
논문의 주요 기여는 다음과 같다. (1) 기존 연구에서 다루지 않았던 최신 음성 코덱(Speex, Opus)을 전처리 방어에 적용해 높은 탐지 성능을 확인하였다. (2) 전처리 결과의 라벨 변화뿐 아니라 출력 로짓의 L1 거리와 클래스별 확률 차이를 활용한 정교한 앙상블 기법을 제시하였다. (3) 트리 기반 학습 모델을 이용해 다차원 특징을 효과적으로 결합함으로써, 적대적 예제 탐지의 정밀도와 재현율을 크게 향상시켰다.
결론적으로, 전처리 단계에서 발생하는 신호 변형을 정량화하고 이를 기반으로 다양한 앙상블 전략을 적용함으로써, Speech Commands 모델에 대한 유전 알고리즘 기반 적대적 공격을 높은 정확도로 탐지할 수 있다. 특히, Opus와 Speex와 같은 현대 음성 코덱이 기존 압축 방식보다 인간 음성 특성을 보존하면서도 섭동을 억제하는 데 유리함을 보여, 실시간 통신이나 VoIP 환경에서 실용적인 방어 메커니즘으로 활용될 가능성을 제시한다. 향후 연구에서는 공격자가 전처리 방식을 회피하도록 설계된 적대적 샘플에 대한 견고성 평가와, 실시간 시스템에 적용 가능한 경량화 모델 개발이 필요하다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기