다양하고 고품질 오디오 텍스처 합성: 새로운 손실 함수와 평가 지표
본 논문은 이미지 텍스처 합성에 성공한 Gram‑matrix 기반 방법을 오디오 도메인에 적용한다. 저차원 특성 때문에 다양성 확보가 어려운 점을 지적하고, 리듬 보존을 위한 자동상관 손실과 텍스처 다양성을 촉진하는 새로운 다양성 손실을 제안한다. 또한 VGGish 모델을 이용한 오디오 전용 Inception‑score인 “VGGish loss”로 품질을 정량화하고, 품질‑다양성 간의 트레이드오프를 실험적으로 분석한다.
저자: Joseph Antognini, Matt Hoffman, Ron J. Weiss
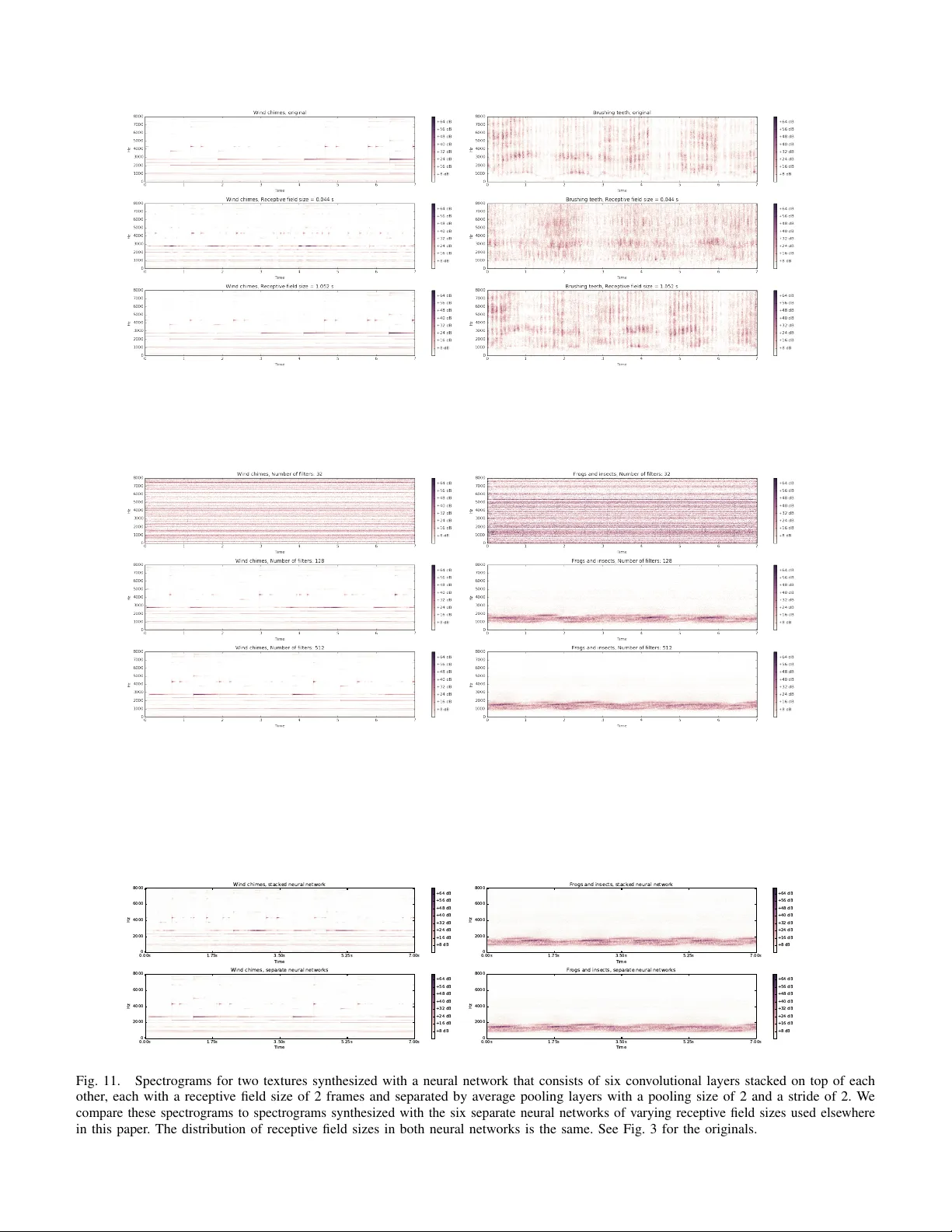
본 논문은 이미지 분야에서 성공을 거둔 Gram‑matrix 기반 텍스처 합성 기법을 오디오 도메인에 확장하고, 오디오 특유의 저차원(채널 대비 샘플 수) 문제를 해결하기 위한 새로운 손실 함수와 평가 지표를 제안한다. 먼저, 텍스처 정의를 “무한히 긴 정적 확률 과정”으로 정형화하고, 실제로는 제한된 길이의 클립만을 관측한다는 전제 하에 충분통계 φ를 이용해 최대 엔트로피 분포를 모델링한다. 오디오를 직접 파형으로 다루는 대신, 16 kHz 샘플링, 512‑점 Hann 윈도우, 64‑점 홉을 사용해 로그 스펙트로그램을 만든다. 이때 절댓값을 취하고 1을 더한 뒤 로그를 씌워 양의 값을 확보하고, Griffin‑Lim 알고리즘(500 iteration)으로 역변환한다.
특징 추출은 6개의 단일 은닉층 랜덤 CNN으로 구성한다. 각 네트워크는 1‑차원 컨볼루션을 사용하고, 커널 크기는 2, 4, 8, 16, 32, 64 프레임으로 다양하게 설정해 다양한 시간 스케일을 포착한다. 필터 수는 512개이며 Glorot 초기화로 무작위 가중치를 부여한다. 저자는 사전 학습된 AudioSet CNN보다 무작위 CNN이 텍스처 재현에 더 효과적임을 실험적으로 확인한다.
합성 손실 L은 세 부분의 가중합으로 정의된다. (1) L Gram 은 각 네트워크의 특징 맵에 대해 시간 평균 외적을 구하고, 합성 스펙트로그램과 원본 스펙트로그램의 Gram 행렬 차이를 Frobenius norm으로 최소화한다. 이는 기존 이미지 기반 방법과 동일하지만, 오디오에서는 채널 수가 많아 통계적 불안정성이 커진다. (2) L autocorr 은 특징 맵의 자동상관 함수를 계산해 200 ms~2 s 구간의 랙에 대해 정규화된 차이를 최소화한다. 이는 리듬이나 주기성을 보존하는 데 핵심이며, 짧은 랙은 이미 개별 CNN의 수용 영역에 포함돼 별도 손실이 필요 없다고 판단한다. (3) L div 은 기존 이미지 다양성 손실(L Sendik)의 부정적 무한 감소 문제를 해결하기 위해, 합성 텍스처를 원본과 모든 가능한 시간 시프트(s)로 비교하고, 그 중 가장 큰 손실을 선택한다. 시프트는 50 프레임 간격으로 샘플링하고, 최근 최적화 단계에서 큰 손실을 보인 시프트를 우선적으로 재계산한다.
최적화는 L‑BFGS‑B 알고리즘을 2000 iteration 수행한다. 초기 100 iteration에만 L div 을 포함해 다양성을 확보하고, 이후에는 품질 손실을 방지하기 위해 제외한다. 최종 스펙트로그램을 Griffin‑Lim으로 복원해 오디오를 생성한다.
평가에서는 VGGish 모델을 이용한 “VGGish score”를 도입한다. VGGish는 AudioSet으로 사전 학습된 CNN이며, 527개의 라벨에 대한 로지스틱 회귀를 추가해 확률 분포 p_VGGish(y|x)를 얻는다. 원본 텍스처와 합성 텍스처 각각에 대해 라벨 분포를 구하고, KL divergence의 기댓값을 지수화해 점수를 산출한다. 높은 점수는 원본과 라벨 분포가 유사함을 의미한다. 또한 자동상관 점수와 다양성 점수를 별도로 측정한다. 실험 결과, L Gram 만 사용할 때 VGGish 점수가 가장 높지만 다양성 점수는 낮으며, L autocorr 을 추가하면 자동상관 점수는 크게 개선되지만 VGGish 점수와 단시간 품질이 감소한다. L div 가중치를 크게 하면 다양성 점수는 크게 낮아지지만 전체 품질 역시 감소한다는 전형적인 트레이드오프가 관찰된다. McDermat & Simoncelli(2002) 방식은 가장 낮은 다양성 점수를 보였지만, 자동상관 점수와 VGGish 점수가 크게 악화된다.
정성적 청취 실험에서는 리듬이 뚜렷한 풍경음(바람, 물소리)과 피치가 명확한 악기음(피아노, 종소리) 모두에서 제안된 손실 조합이 원본과 유사하면서도 새로운 변형을 생성함을 확인했다. 특히 자동상관 손실이 없는 경우 리듬이 흐트러지는 현상이 나타났으며, 다양성 손실이 없으면 합성 결과가 원본을 거의 그대로 복제하는 경향이 있었다.
마지막으로, 저자들은 이러한 텍스처 합성 프레임워크가 오디오 스타일 전송에도 적용 가능함을 논의한다. 스타일 전송에서는 콘텐츠와 스타일 텍스처의 Gram 행렬을 동시에 맞추는 것이 핵심이며, 제안된 자동상관 및 다양성 손실이 스타일의 리듬과 변형성을 유지하는 데 기여할 수 있다. 향후 연구에서는 더 큰 데이터셋과 사전 학습된 모델을 활용한 하이브리드 접근법, 그리고 실시간 합성을 위한 효율적인 최적화 알고리즘 개발이 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기