학습 가능한 사전 인코딩 레이어를 활용한 엔드투엔드 언어 식별
본 논문은 전통적인 GMM‑i‑vector 방식과 이론·실험적으로 일치하도록 설계된 새로운 Learnable Dictionary Encoding(LDE) 레이어를 제안한다. LDE 레이어는 CNN 위에 삽입되어 가변 길이 입력을 고차 통계량으로 집계하고 고정 차원의 순서 없는 표현을 생성한다. NIST LRE07 폐쇄형 테스트에서 평균 풀링 대비 오류율이 크게 감소함을 보였다.
저자: Weicheng Cai, Zexin Cai, Xiang Zhang
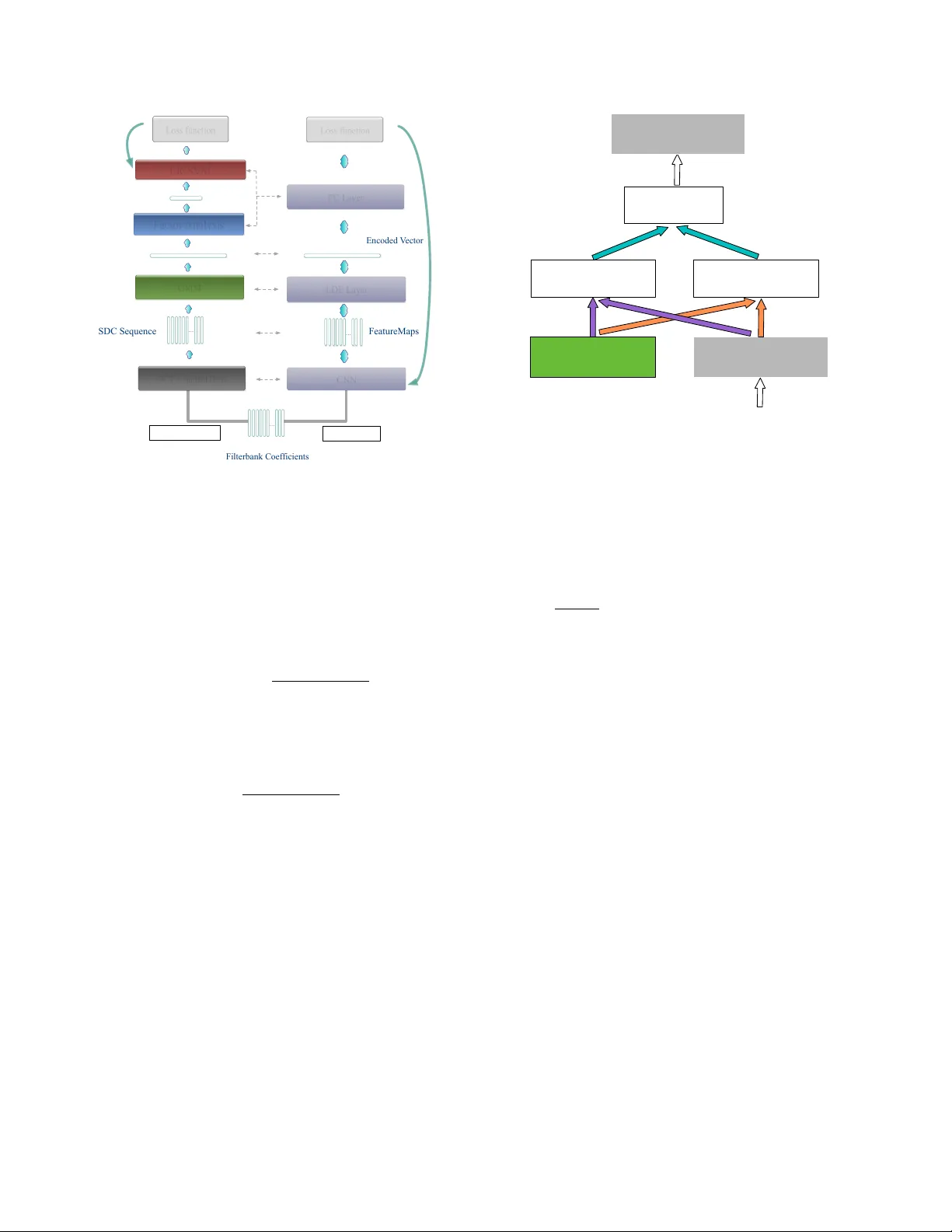
본 논문은 언어 식별(LID) 과제에서 전통적인 GMM‑i‑vector 프레임워크와 최신 딥러닝 기반 엔드‑투‑엔드 모델을 융합하는 새로운 방법을 제안한다. 기존 GMM‑Supervector 방식은 모든 프레임을 하나의 통계적 사전(UBM)으로 묶어 0차·1차 Baum‑Welch 통계량을 추출하고, 이를 고차원 Supervector 혹은 i‑vector로 압축한다. 이러한 접근은 가변 길이 입력을 고정 차원 표현으로 변환하는 데 효과적이지만, 사전 학습이 비지도 방식이며, 최종 분류기와의 연계가 별도로 이루어지는 구조적 한계가 있다.
이에 저자들은 CNN 위에 “Learnable Dictionary Encoding”(LDE) 레이어를 설계하였다. LDE 레이어는 입력 특성 시퀀스 X∈ℝ^{D×L}를 받아, 사전 중심 µ_c (c=1…C)와 스무딩 파라미터 s_c를 학습 가능한 파라미터로 두고, 각 프레임 x_t에 대해 소프트 할당 가중치 w_{tc}=exp(−s_c‖x_t−µ_c‖²)/Σ_m exp(−s_m‖x_t−µ_m‖²) 를 계산한다. 이때 w_{tc}는 전통적인 GMM posterior와 동일한 형태이며, 미분 가능하도록 설계되어 역전파를 통해 사전 자체가 손실에 직접 최적화된다. 이후 잔차 r_{tc}=x_t−µ_c와 가중치 w_{tc}를 곱해 각 사전 원소별 집계 e_c=Σ_t w_{tc}·r_{tc} 를 수행하고, 이를 연결해 D×C 차원의 고정 길이 벡터 E를 만든다. 최종적으로 L2 정규화를 적용해 표현의 스케일을 통일한다.
LDE 레이어는 두 가지 중요한 특성을 가진다. 첫째, 가변 길이 입력을 그대로 처리하면서도 순서에 무관한(순서 없는) 표현을 제공한다. 이는 언어 식별에서 발화 내용이 달라도 언어 고유의 통계적 특성을 포착하는 데 유리하다. 둘째, 사전 중심과 스무딩 파라미터가 학습 과정에서 동시에 업데이트되므로, 데이터 분포에 최적화된 사전이 자동으로 형성된다. 이는 기존 K‑means 기반 하드 할당이나 고정 사전 GMM 대비 더 정교한 특징 집계가 가능함을 의미한다.
실험은 NIST LRE07 폐쇄형 테스트(14개 언어, 3 s, 10 s, 30 s 길이)에서 수행되었다. 베이스라인으로는 Kaldi 기반 GMM‑i‑vector 시스템을 구축했으며, 2048‑component full‑covariance UBM과 600‑dimensional i‑vector를 사용했다. 이 시스템은 C_avg 20.46 %·EER 17.71 %를 기록했다. 딥러닝 기반 비교 모델로는 ResNet‑34 구조의 CNN에 평균 풀링(TAP) 레이어를 추가한 CNN‑TAP과, 동일한 CNN에 LDE 레이어를 삽입한 CNN‑LDE를 사용했다. 입력 특징은 64‑dim log‑mel filterbank이며, VAD를 통해 음성 프레임만을 사용했다.
CNN‑TAP은 C_avg 9.98 %·EER 11.28 %로 GMM‑i‑vector 대비 큰 개선을 보였지만, CNN‑LDE는 사전 원소 수 C에 따라 성능이 변동하였다. C=16일 때 C_avg 9.61 %·EER 8.89 %, C=32일 때 8.70 %·8.12 %, C=64일 때 최적의 8.25 %·7.75 %를 달성했다. C를 128, 256으로 늘리면 과적합 현상이 나타나 성능이 약간 저하되었다. 특히 EER 측면에서 CNN‑LDE(C=64)는 TAP 대비 0.96 % 포인트(≈30 % 상대 개선) 감소했다.
또한, 시스템 레벨에서 CNN‑LDE(C=64)와 CNN‑LDE(C=32)를 스코어 레벨에서 융합한 경우 C_avg 6.98 %·EER 6.09 %까지 추가 개선되었다. 이는 LDE 레이어가 서로 다른 사전 크기의 모델 간에 상보적인 정보를 제공한다는 점을 보여준다.
논문은 LDE 레이어가 기존의 TAP와 달리 “학습 가능한 사전”을 통해 고차 통계량을 집계함으로써, 딥러닝 기반 LID 시스템에 GMM‑Supervector의 장점을 자연스럽게 도입할 수 있음을 입증한다. 또한, 사전 크기와 스무딩 파라미터를 적절히 조정하면 다양한 발화 길이와 잡음 조건에서도 견고한 성능을 유지할 수 있다. 향후 연구에서는 사전 초기화를 phoneme‑aware 방식으로 진행하거나, 다중‑언어 다중‑태스크 학습에 확장하는 방안을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기