언어식별을 위한 엔드투엔드 학습과 인코딩 레이어 설계
본 논문은 기존 GMM‑i‑vector 파이프라인과 이론·실험적으로 일치하는 새로운 엔드투엔드 언어식별 모델을 제안한다. 프론트엔드로 깊은 Residual CNN을 사용하고, 가변 길이 입력을 고정 차원의 발화 수준 벡터로 변환하는 일반화된 인코딩 레이어(TAP, RNN, LDE)를 적용한다. NIST LRE07 폐쇄형 테스트에서 제안된 CNN‑LDE 구조가 기존 GMM‑i‑vector 및 DNN‑PPP 기반 시스템을 능가하는 성능을 보이며, …
저자: Weicheng Cai, Zexin Cai, Wenbo Liu
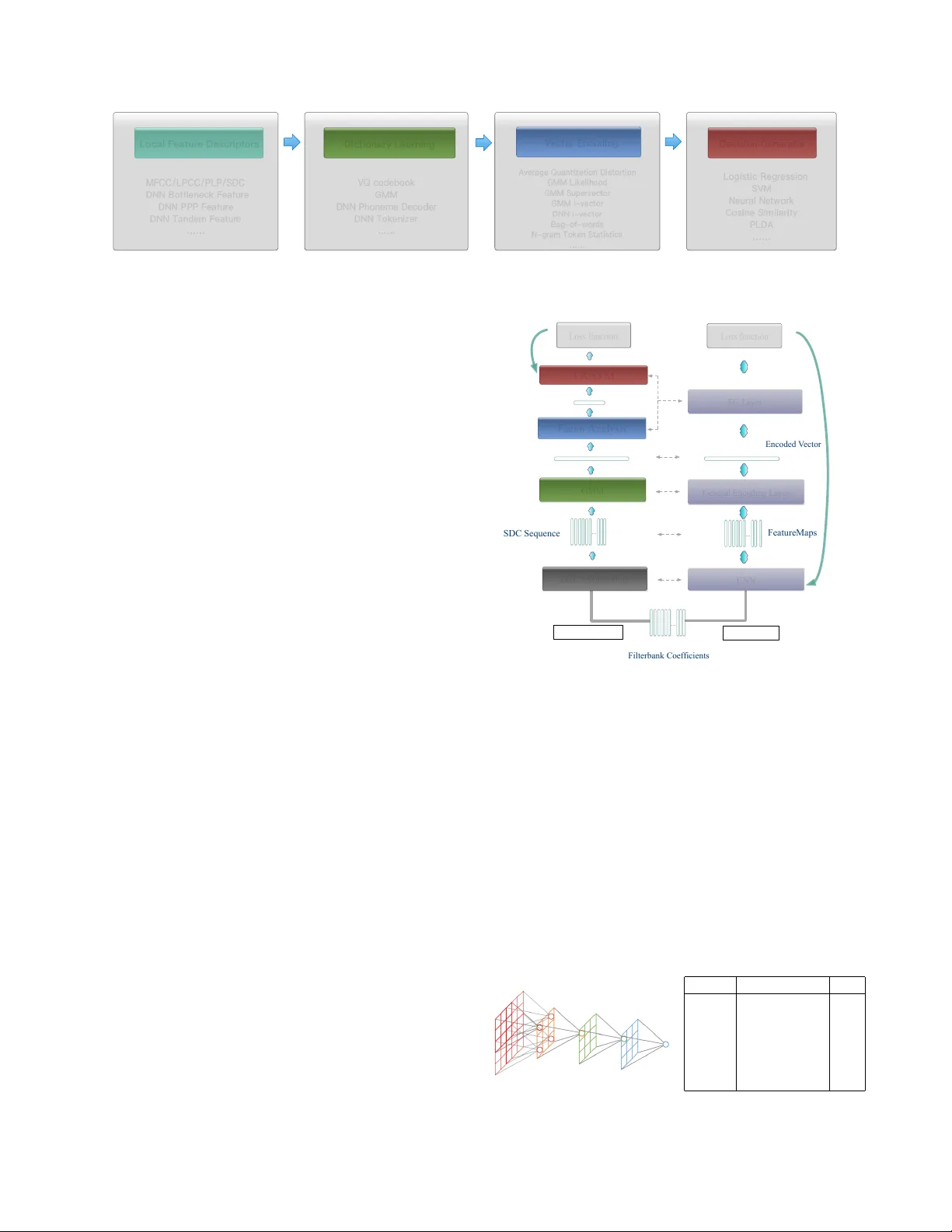
본 논문은 언어식별(LID) 작업을 위한 새로운 엔드투엔드 학습 프레임워크를 제시한다. 기존의 GMM‑i‑vector 파이프라인은 로컬 특징 추출, 딕셔너리 학습, 벡터 인코딩, 분류기 학습 네 단계로 구성되며, 각 단계가 독립적으로 최적화된다. 이러한 구조는 비지도 방식으로 딕셔너리를 학습하기 때문에, 언어 구분에 유용한 패턴을 충분히 반영하지 못할 가능성이 있다. 최근 딥러닝 기반 엔드투엔드 접근이 등장했지만, 왜 성능이 좋은지에 대한 체계적인 분석이 부족했다.
저자들은 먼저 CNN이 LID에 어떻게 기여하는지를 탐구한다. CNN은 이미지 인식에서 입증된 바와 같이, 격자 형태의 입력에 대해 지역적인 필터를 학습한다. 음성 신호를 64‑dimensional Fbank 형태로 변환하면, CNN은 시간‑주파수 격자 위에서 컨볼루션을 수행한다. 여러 층을 쌓고 스트라이드와 풀링을 적용함으로써, 각 뉴런의 수용 영역이 점차 확대되어 전체 발화 구간을 포괄한다. 따라서 CNN은 가변 길이 입력을 고차원 로컬 특징 맵으로 변환하고, 이 특징 맵은 여전히 시간 순서를 보존한다.
다음으로 저자들은 이러한 시계열 특징을 발화 수준의 고정 차원 벡터로 변환하는 “일반 인코딩 레이어”를 제안한다. 인코딩 레이어는 입력 텐서 (D_in × L)를 받아, 시간 차원을 집계해 (D_out × C) 형태의 벡터를 출력한다. 여기서 C는 딕셔너리 컴포넌트 수를 의미한다. 세 가지 구현을 비교한다.
1. **Temporal Average Pooling (TAP)**: 가장 단순한 형태로, 모든 프레임의 평균을 취한다. 이는 시간 순서를 무시하고 순수히 통계적 분포만을 반영한다.
2. **Recurrent Encoding (LSTM/GRU)**: 순환 신경망을 사용해 프레임 순서를 모델링한다. 마지막 은닉 상태를 발화 벡터로 사용한다. 이 방식은 시간 의존성을 포착하지만, 실험에서는 긴 발화(30 s)에서 성능이 급격히 저하되는 “문장 길이 저주” 현상이 관찰되었다.
3. **Learnable Dictionary Encoding (LDE)**: 전통적인 GMM‑Supervector 아이디어를 딥러닝 형태로 구현한다. 학습 가능한 딕셔너리 중심을 정의하고, 각 프레임이 중심에 얼마나 가까운지를 가중치로 사용해 고차 통계량을 축적한다. LDE는 딕셔너리 학습과 벡터 인코딩을 하나의 레이어로 통합해, 손실 함수에 의해 직접 최적화된다.
실험은 NIST LRE07 폐쇄형 14개 언어 데이터셋을 사용했다. 훈련 데이터는 Callfriend, LRE2003/2005, SRE2008 등 약 37,000개의 발화로 구성되었다. 테스트는 3 s, 10 s, 30 s 세 가지 길이로 나뉘었다. 베이스라인으로는 56‑dimensional SDC 기반 GMM‑i‑vector, DNN‑i‑vector, DNN‑PPP, DNN‑tandem, 그리고 다양한 RNN 기반 모델이 포함되었다.
결과는 다음과 같다. GMM‑i‑vector은 3 s에서 C_avg 20.46 %/EER 17.71 %를 기록했으며, DNN‑PPP는 8.00 %/6.90 %로 가장 좋은 베이스라인이었다. 제안된 엔드투엔드 모델 중, CNN‑LDE가 3 s에서 C_avg 8.25 %/EER 7.75 %, 10 s에서 2.61 %/2.31 %, 30 s에서 1.13 %/0.96 %를 달성해 모든 베이스라인을 크게 앞섰다. CNN‑TAP도 비교적 좋은 성능을 보였지만, LDE가 가장 우수했다. 반면, CNN‑GRU와 CNN‑LSTM은 10 s 이하에서는 경쟁력 있었지만, 30 s에서는 성능이 급격히 떨어졌다.
이러한 결과는 두 가지 중요한 시사점을 제공한다. 첫째, 언어식별은 발화 내용보다 언어 고유의 통계적 특성(음소, 억양, 스펙트럼 분포 등)을 포착하는 것이 핵심이다. 따라서 시간 순서를 보존하는 RNN보다 시간 불변 특성을 강조하는 평균 풀링이나 딕셔너리 기반 인코딩이 더 적합하다. 둘째, LDE는 전통적인 딕셔너리 학습과 고차 통계량 추출을 하나의 파라미터화된 레이어로 구현함으로써, 별도의 사전 학습 단계 없이도 최적의 특징을 자동으로 학습한다. 이는 엔드투엔드 학습이 전체 파이프라인을 공동 최적화함으로써, 기존 GMM‑i‑vector이 갖는 “각 단계가 고정된 채 최적화”라는 한계를 극복한다는 것을 실증한다.
결론적으로, 본 연구는 CNN과 일반 인코딩 레이어(특히 LDE)를 결합한 엔드투엔드 LID 모델이 기존 GMM‑i‑vector 및 DNN‑PPP 기반 시스템을 능가함을 입증한다. 또한, 시간 불변 특성의 중요성을 강조함으로써, 향후 LID뿐 아니라 다른 파라링귀스틱 음성 인식 과제에도 적용 가능한 설계 원칙을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기