경찰 바디워너드 오디오 자동 갈등 탐지
본 논문은 경찰 바디워너드 오디오(BWA)에서 갈등 상황을 자동으로 식별하기 위한 파이프라인을 제안한다. 적응형 잡음 제거와 비음성 필터링을 거친 뒤, 반복 구문과 발화 강도를 기반으로 새로운 갈등 지표를 정의한다. 105개의 LAPD 데이터에 적용한 결과, 고·중·저 갈등 파일을 효과적으로 순위화하여 수작업 검토 시간을 크게 절감한다.
저자: Alistair Letcher, Jelena Triv{s}ovic, Collin Cademartori
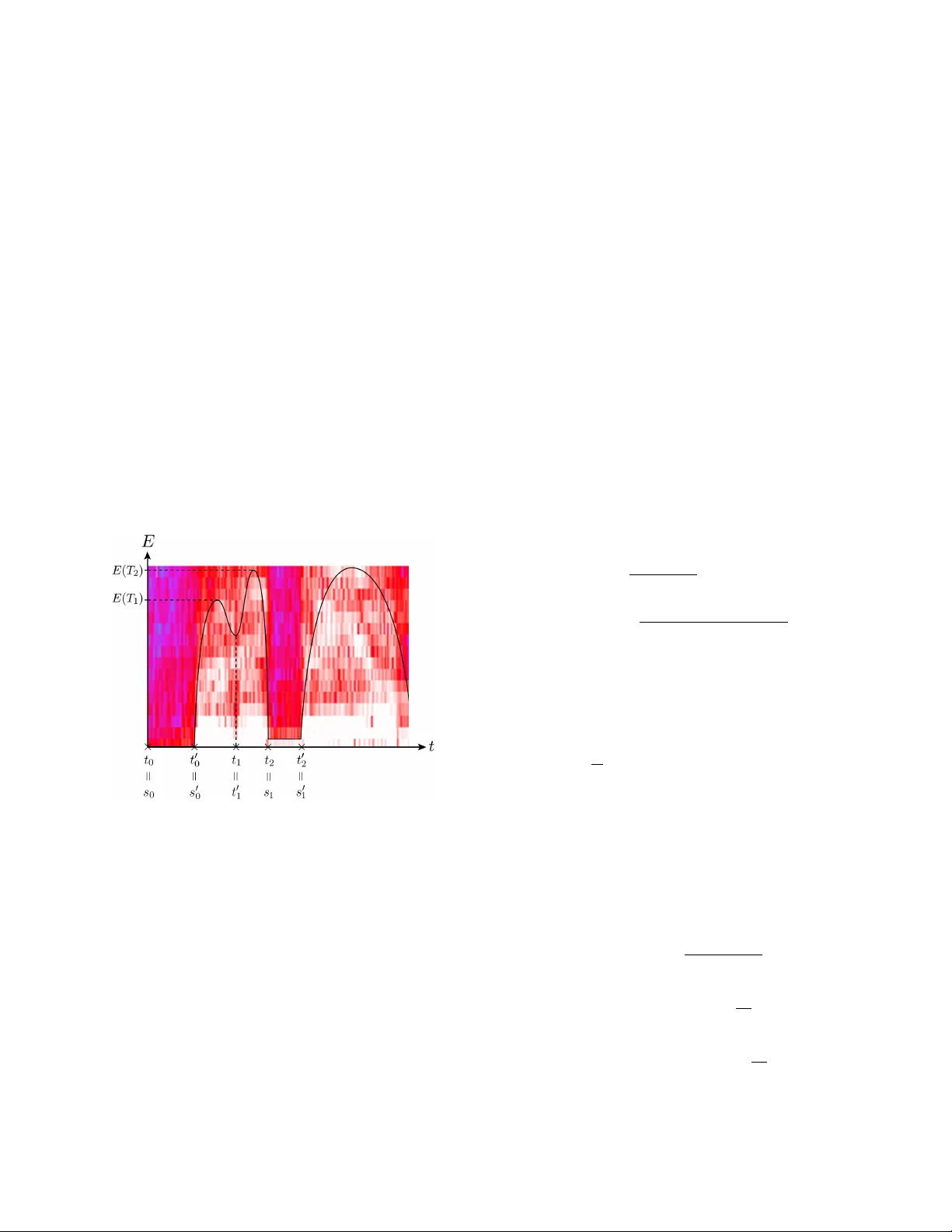
본 논문은 경찰 바디워너드 오디오(BWA)에서 갈등 상황을 자동으로 탐지하고, 대량의 녹음 파일 중 갈등이 포함된 파일을 효율적으로 선별하기 위한 종합 파이프라인을 제시한다. 연구 배경으로는 BWA가 증거 확보와 투명성 제고에 기여하지만, 방대한 데이터량으로 인해 수작업 검토가 비현실적이라는 점을 들었다. 기존 연구들은 정치 토론 등에서 발화 겹침(overlap)이나 턴‑테이킹(turn‑taking)을 갈등 지표로 사용했지만, BWA는 교통 소음, 사이렌, 무전 등 다양한 잡음이 섞여 있어 이러한 지표가 신뢰성이 떨어진다. 특히 갈등 상황에서는 오피서가 끊임없이 명령을 반복하거나 큰 소리로 말하는 경우가 많아, 겹침보다 반복과 강도가 더 유의미한 특징이 된다.
논문은 크게 세 단계로 구성된 처리 흐름을 설계한다. 첫 번째 단계는 적응형 잡음 제거이다. 여기서는 최적화된 로그 스펙트럼 진폭(OM‑LSA) 추정과 최소값 제어 재귀 평균(MCRA) 기법을 결합해 지속적인 배경 잡음과 순간적인 급성 잡음을 모두 억제한다. 신호 y(n)=x(n)+d(n) 를 STFT로 변환하고, 각 주파수‑시간 셀(k,l) 에 대해 사후 음성 존재 확률 p(k,l)와 사전 SNR ξ(k,l)를 이용해 스펙트럼 이득 G(k,l)를 계산한다. 이 과정을 세 번 연속 적용해 잡음 억제 효과를 극대화한다.
두 번째 단계는 비음성(음성 외 소리) 필터링이다. 0.06 s 프레임을 0.02 s 간격으로 겹치게 나누고, 각 프레임에서 13개의 MFCC, 제로‑크로싱, 에너지, 스펙트럼 중심·폭·엔트로피·플럭스·롤오프, 기본 주파수, 조화비 등 총 23개의 단기 특징을 추출한다. 이들을 0.3 s 중간 윈도우(0.1 s 스텝)로 평균해 장기 특징을 보강한다. 이렇게 구성된 23‑차원 특징 벡터를 입력으로 RBF‑SVM을 학습시켰으며, 38분(22 733 프레임)의 음성 데이터와 47분(28 239 프레임)의 비음성 데이터를 이용해 10‑fold 교차 검증을 수행했다. 결과는 전체 오류율 2.31 %로, 기존 5‑12 % 수준보다 현저히 낮았다.
세 번째 단계는 갈등을 나타내는 핵심 지표인 ‘반복 탐지’와 ‘강도 점수’ 계산이다. 먼저 에너지 기반 구간 분할을 수행한다. 300‑3000 Hz 대역을 통과시킨 뒤, 0.05 s 윈도우의 제곱 에너지 E₀(t)를 구하고, 0.05 이상의 에너지만을 남긴다. 로컬 최소점과 최대점을 찾아 구간을 정의하고, 에너지 차이가 표준편차 σ보다 큰 경우에만 유의미한 구간으로 채택한다. 이렇게 얻은 기본 구간을 0.02 s 간격으로 병합해 최소 0.05 s 길이의 세그먼트를 만든다.
반복 검증은 두 가지 상보적 방법으로 수행한다. 첫 번째는 ‘지문(fingerprint)’ 방식이다. 각 구간을 0.1 s 길이의 N개의 시간 윈도우와 32개의 주파수 밴드로 나누고, 각 밴드‑윈도우의 에너지 Eₙ,ₘ에 대해 2차 차분 Δ²(n,m)를 계산한다. Δ²가 양수이면 해당 위치를 1, 아니면 0으로 이진화해 2‑차원 이진 배열 F(n,m)를 만든다. 두 구간의 지문 차이율 E는 배열이 다른 위치 비율이며, 차이율이 30 % 이하이면 강한 반복, 45 % 이상이면 비반복으로 판단한다.
두 번째는 푸리에 계수 상관 방식이다. 구간을 겹치는 윈도우로 나누고, 각 윈도우의 300‑3000 Hz 대역 푸리에 계수 ˆwᵢₙ(m)를 추출한다. 각 주파수 밴드 m에 대해 두 구간의 계수 간 피어슨 상관계수 C(m)를 구하고, 이를 평균해 전체 상관 점수 C를 얻는다. 상관 점수는 0.25‑0.55 사이면 중간, 0.55 이상이면 높은 유사도로 해석한다.
두 지표를 정규화 함수 f₁(E), f₂(C)로 변환해 종합 점수 S(E,C)=p·f₁·f₂를 산출한다. 여기서 p는 가중치이며, f₁은 E에 대해 0.3 이하에서는 1, 0.3‑0.45에서는 선형 감소, 0.45 초과에서는 0으로 매핑한다. f₂는 C에 대해 0.55 이상에서 1, 0.25‑0.55에서는 선형 증가, 0.25 이하에서는 0으로 매핑한다. 이렇게 얻은 S는 구간 수준의 반복 점수이며, 파일 전체 점수는 상위 5 %의 비중복 비교 중 비영점 평균으로 정의한다.
강도 점수는 동일 상위 5 % 구간들의 평균 에너지로 계산한다. 최종 갈등 점수는 반복 점수와 강도 점수의 곱으로, 반복이 많고 발화가 강할수록 높은 값을 가진다.
실험은 LAPD에서 제공한 105개의 BWA 파일(길이 3‑30 분)에서 수행되었다. 라벨링은 고(3건), 중(15건), 저(87건) 세 등급으로 구분했으며, 고·중 갈등 파일이 모두 상위 10점수 안에 포함되는 등 순위화 성능이 뛰어났다. 전체 파일을 점수 순으로 정렬했을 때, 상위 23 %(약 24개 파일)만 검토하면 78 %의 갈등 파일을 포착할 수 있었다. 평균 점수 역시 세 등급 간에 명확히 구분되었다.
논문은 또한 화자 다이어리제이션의 필요성을 강조한다. 현재 비오피서 음성은 잡음에 취약해 오탐률을 높이지만, 화자 검증을 위한 사전 녹음 샘플을 확보한다면 오피서 음성만을 대상으로 갈등 지표를 계산해 정확도를 크게 향상시킬 수 있다. 최신 화자 다이어리제이션 기법은 깨끗한 데이터에서 18‑30 % 오류율을 보이지만, BWA와 같은 현장 잡음 환경에서는 성능이 저하된다. 따라서 추가 라벨링과 감독 학습을 통한 화자 검증 모델 구축이 향후 연구 과제로 제시된다.
결론적으로, 본 연구는 잡음이 심한 현장 음성에서 반복과 강도 기반 갈등 지표를 성공적으로 설계하고, 이를 통해 대규모 BWA 데이터에서 갈등 상황을 자동으로 선별할 수 있음을 입증한다. 제안된 파이프라인은 실시간 혹은 배치 처리에 적용 가능하며, 경찰 현장 기록 관리와 정책 수립에 실질적인 도움을 줄 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기