딥러닝 기반 채널 디코더 성능 비교: MLP·CNN·RNN의 한계와 가능성
본 논문은 동일한 파라미터 규모를 갖는 다층 퍼셉트론(MLP), 합성곱 신경망(CNN), 순환 신경망(RNN) 세 종류의 딥 뉴럴 네트워크 디코더(NND)를 설계하고, BPSK‑AWGN 채널에서 폴라 코드(율 1/2, 길이 8·16·32)의 비트 오류율(BER)을 통해 성능을 평가한다. 실험 결과 RNN이 가장 낮은 BER을 달성하지만 연산량이 가장 크며, 각 모델마다 ‘포화 길이’가 존재해 일정 길이 이상에서는 학습 능력이 제한된다. 또한 학…
저자: Wei Lyu, Zhaoyang Zhang, Chunxu Jiao
본 논문은 5G 시대의 고속·저지연 통신 요구에 부응하기 위해, 딥 뉴럴 네트워크를 이용한 채널 디코더(NND)의 설계와 성능을 체계적으로 평가한다. 연구자는 동일한 파라미터 규모(≈1 000개)를 갖는 세 가지 네트워크 구조—다층 퍼셉트론(MLP), 1‑차원 합성곱 신경망(CNN), 장기 기억(LSTM) 기반 순환 신경망(RNN)—를 설계하고, 각각을 BPSK 변조와 AWGN 채널을 거친 폴라 코드(율 1/2, 코드워드 길이 N=8, 16, 32) 복호에 적용한다.
시스템 프레임워크는 송신 측에서 정보 비트 x(K)를 채널 인코더를 통해 코드워드 u(N)로 변환하고, BPSK 매핑 후 AWGN 노이즈 n을 더해 수신 벡터 y를 만든다. 수신 측에서는 사전 학습된 NND가 y를 한 번만 통과시켜 추정 비트 ˆx를 출력한다(‘one‑shot decoding’). 목표는 MAP 디코딩에 근접하는 f*:Y→X를 학습하는 것이다.
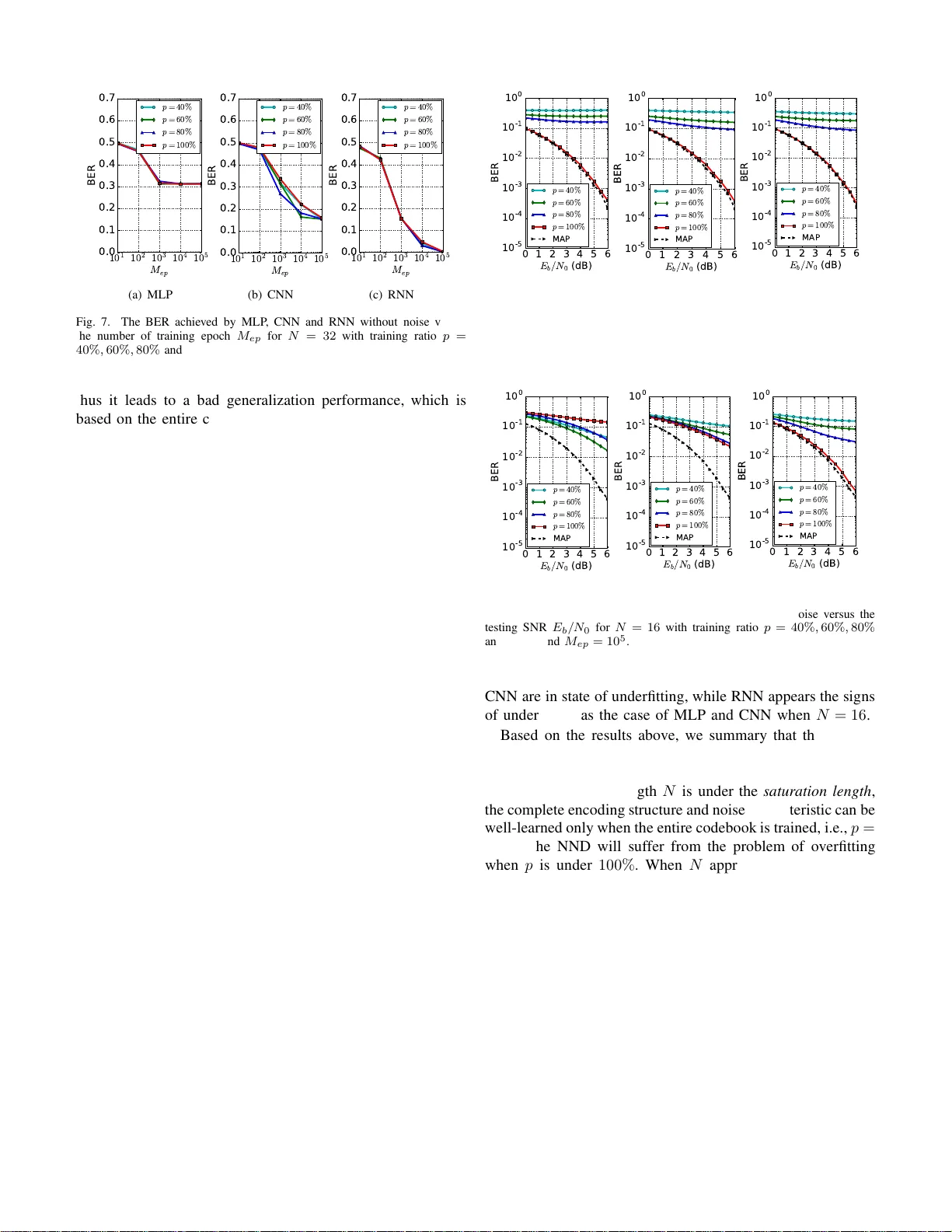
학습 단계에서는 두 가지 핵심 설계 요소를 다룬다. 첫째, 전체 코드북 X 중 일부 비율(p)를 무작위 추출해 훈련 데이터셋을 구성한다. p를 40 %, 60 %, 80 %, 100 %로 변화시켜 일반화 능력을 평가한다. p가 낮을수록 훈련 샘플이 제한돼 과적합이 발생하고, 테스트 시 미보인 코드워드에 대한 BER이 크게 상승한다. 둘째, 학습 SNR(ρ_t)을 다양한 값(−2 dB~20 dB)으로 설정해 최적의 노이즈 레벨을 탐색한다. 정규화 검증 오류(NVE)라는 지표를 도입해, ρ_t가 너무 높으면 노이즈에 대한 견고성이 부족하고, 너무 낮으면 인코딩 구조 자체를 학습하지 못한다는 두 극단을 피하고 중간값(≈0 dB~2 dB)이 최적임을 확인한다.
각 네트워크의 구조는 다음과 같다. MLP는 입력층(N), 은닉층 3개(64‑32‑16), 출력층(K)로 구성되며, 시그모이드 활성화와 MSE 손실 함수를 사용한다. CNN은 1‑차원 컨볼루션(커널 3×1, 스트라이드 1)과 풀링(2×1, 스트라이드 2)을 여러 단계 쌓아 입력 차원을 점진적으로 축소하고, 마지막에 1×K 시그모이드 레이어를 두어 확률값을 출력한다. RNN은 LSTM 셀 하나를 각 타임스텝에 적용, 셀 차원을 256으로 설정해 은닉 상태와 셀 상태를 유지한다. 세 모델 모두 파라미터 수를 1 000 ~ 5 000 수준으로 맞추어, 구조적 차이가 성능에 미치는 영향을 순수하게 비교한다.
성능 평가는 두 파트로 나뉜다. 첫 번째 파트는 노이즈 없는 학습(ρ_t→∞) 상황에서, 학습 에포크 수(M_ep)와 훈련 비율(p)에 따른 BER 변화를 관찰한다. 결과는 모든 모델이 에포크가 증가함에 따라 BER이 감소하고, p=100 %일 때만 BER이 0에 수렴함을 보여준다. 이는 충분한 코드북 커버리지가 없으면 네트워크가 ‘기억’에 의존하게 됨을 의미한다. 두 번째 파트는 실제 채널 노이즈를 포함한 학습(ρ_t 최적값)에서, 테스트 SNR 범위(−2 dB~20 dB)에 대한 BER을 측정한다. 여기서 RNN은 전체 SNR 구간에서 가장 낮은 BER을 기록했으며, 특히 N=32일 때 MAP 디코딩에 근접하는 성능을 보였다. CNN은 중간 수준의 성능을, MLP는 가장 높은 BER을 나타냈다.
흥미로운 현상으로 ‘포화 길이(saturation length)’가 보고되었다. 동일 파라미터 수 하에서 입력 차원이 일정 수준을 초과하면 모델의 학습 능력이 포화되어 BER 개선이 멈춘다. 구체적으로 MLP는 N≈16에서, CNN은 N≈24~32에서, RNN은 N≈48에서 포화가 관찰되었다. 이는 파라미터 수를 늘리거나, 더 깊은 레이어, 더 큰 은닉 차원 등을 도입하면 극복 가능함을 시사한다.
연산 복잡도 측면에서 RNN은 LSTM 셀의 내부 연산(게이트 계산, 상태 업데이트)으로 가장 높은 FLOPs와 메모리 사용량을 요구한다. 반면 MLP와 CNN은 비교적 간단한 행렬·컨볼루션 연산으로 구현이 용이하고, 저전력 디바이스에 적합하다. 따라서 실시간 저지연이 절대적인 요구인 5G 기지국에서는 RNN 기반 가속기 설계가 필요하고, 모바일 단말에서는 CNN 혹은 경량 MLP가 현실적인 선택이 될 수 있다.
결론적으로, 딥러닝 기반 NND는 전통적인 BP·MAP 디코딩에 비해 학습 비용이 크지만, 파라미터 효율과 병렬 처리 능력을 활용해 고속·저지연 복호를 구현할 수 있다. 모델 선택은 코드워드 길이, 목표 BER, 하드웨어 제약에 따라 달라지며, 향후 연구는 파라미터 규모 확대, 하이퍼파라미터 자동 최적화, 그리고 실제 하드웨어 구현을 통한 실시간 성능 검증에 초점을 맞춰야 할 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기