도메인 지식을 활용한 엔드투엔드 오디오 처리
본 논문은 원시 파형을 입력으로 하는 심층 CNN의 초기 층을 학습시켜 로그 스케일 멜 스펙트로그램 변환을 스스로 구현하도록 하고, 이를 ESC‑50 환경음 분류에 적용해 기존 멜 스펙트로그램 기반 모델과 동등한 성능을 달성함을 보인다.
저자: Tycho Max Sylvester Tax, Jose Luis Diez Antich, Hendrik Purwins
본 논문은 엔드투엔드 오디오 처리에서 전통적인 멜 스펙트로그램과 같은 고수준 특성을 신경망이 직접 학습하도록 하는 방법을 제안한다. 서론에서는 이미지 분야에서 엔드투엔드 모델이 뛰어난 성능을 보이는 반면, 오디오 분야에서는 여전히 전처리된 스펙트로그램이나 MFCC가 우수한 결과를 만든다고 지적한다. 이러한 격차를 메우기 위해 도메인 지식(멜 필터뱅크와 로그 압축)을 신경망 초기 층에 명시적으로 학습시켜, 원시 파형만으로도 동일한 정보를 추출하도록 한다.
데이터셋으로는 환경음 분류용 ESC‑50을 사용한다. ESC‑50은 50개의 클래스로 구성된 2000개의 5초 길이 오디오 클립을 5개의 폴드로 나누어 교차 검증을 지원한다. 기존 베이스라인인 PiczakCNN은 2‑D CNN 두 층과 풀링, 완전 연결층으로 구성되며, 로그 스케일 멜 스펙트로그램과 그 델타를 입력으로 사용한다. 이 모델은 멜 스펙트로그램만 사용할 경우 평균 53 % 정확도를 보인다.
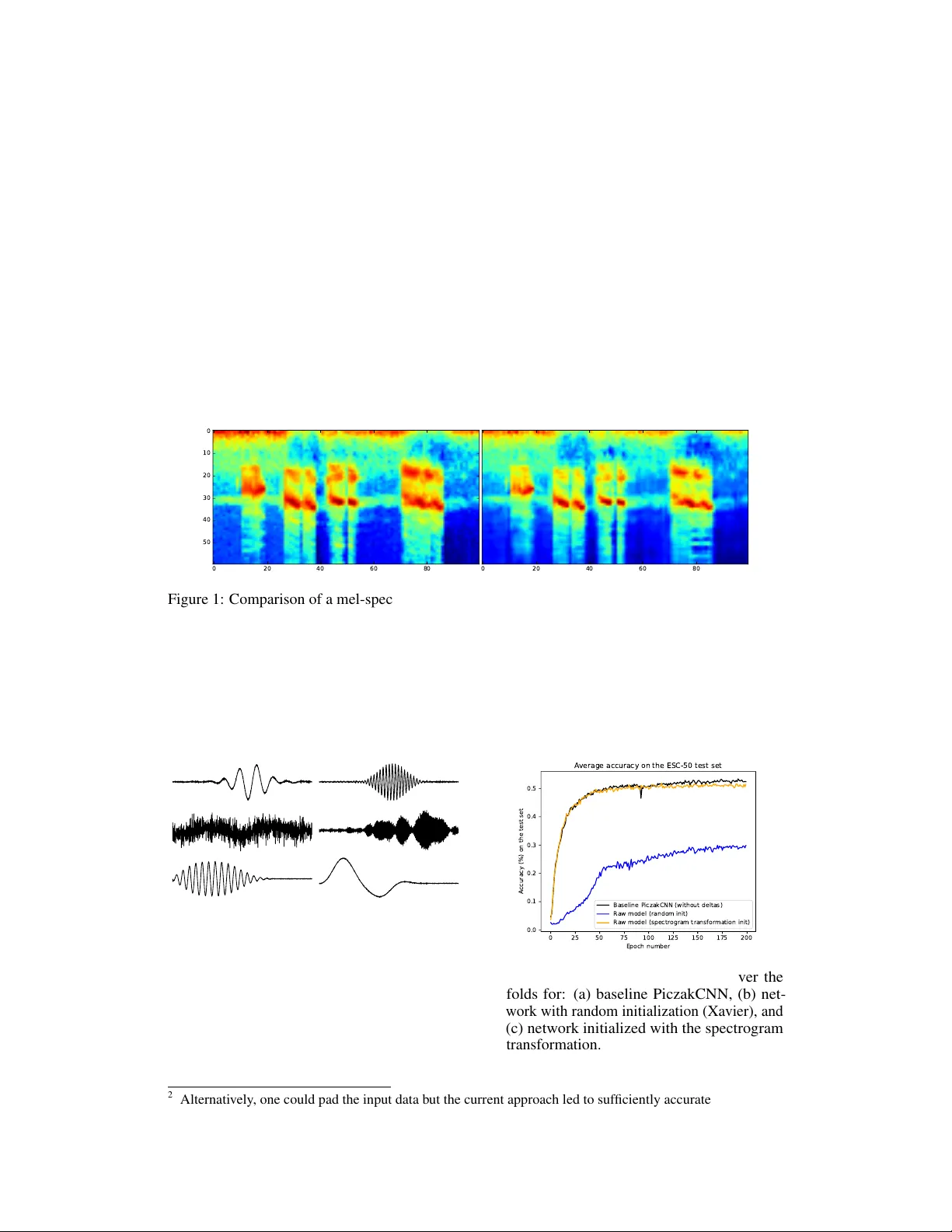
먼저 멜 스펙트로그램 변환 모델(MSTmodel)을 설계한다. 구조는 1‑D 컨볼루션 3층으로, 각각 512‑1024, 256‑3, 60‑3 필터를 갖고 stride는 512, 1, 1이다. 첫 층은 STFT의 윈도우와 홉 크기에 대응하도록 설계돼 원시 파형을 바로 멜 스펙트로그램으로 매핑한다. 입력 파형은 22 050 Hz로 리샘플링하고 -1~1로 정규화한다. 목표 멜 스펙트로그램은 Librosa를 이용해 60개의 멜 밴드, 윈도우 1024, 홉 512, 로그 변환 후 -1~1로 정규화한다. 학습은 MSE 손실, Adam 옵티마이저(3e‑4), 배치 100, 조기 종료 방식으로 진행한다. 각 폴드마다 별도 모델을 학습해 테스트 데이터와 겹치지 않도록 한다. 결과적으로 학습된 필터는 파형렛·밴드패스 형태를 띠며, 시각적으로도 원본 멜 스펙트로그램과 거의 일치한다. 순수 톤, 음성, 음악 등 다양한 신호에서도 변환이 일관되게 작동한다는 점을 확인한다.
다음으로 엔드투엔드 환경음 분류 모델을 구성한다. 기존 Pic탄CNN에 앞서 MSTmodel을 삽입하고, 두 가지 초기화 방식을 비교한다. 첫 번째는 Xavier 초기화로 무작위 가중치를 부여한 경우, 두 번째는 사전 학습된 MSTmodel 가중치를 그대로 사용하고 학습 중 고정한다. 상위 2‑D CNN 층은 기존과 동일하게 유지한다. 학습은 교차 엔트로피 손실, SGD with Nesterov momentum(0.9), 배치 500, 학습률 5e‑3, 200 epoch 진행한다. 드롭아웃(keep prob = 0.5)을 MSTmodel 층에 추가해 과적합을 방지한다. 테스트 시에는 101 프레임 세그먼트에 대해 다수결 투표를 적용한다.
실험 결과는 Figure 3에 요약된다. 무작위 초기화 모델은 수렴이 느리고 최종 정확도가 약 48 % 수준에 머문다. 반면, 사전 학습된 MSTmodel을 고정한 모델은 빠르게 수렴하며 평균 53 % 정확도를 달성, 멜 스펙트로그램 기반 베이스라인과 거의 동등한 성능을 보인다. 이는 초기 층이 멜 변환을 정확히 수행함으로써, 이후 2‑D CNN이 기존과 동일한 고수준 특성을 학습할 수 있게 함을 의미한다. 또한, 전통적인 아키텍처 설계에서 종종 사용되는 max‑pooling이나 로그 레이어와 같은 수동적 전처리 단계를 신경망이 자체적으로 구현하도록 함으로써, 설계 복잡성을 감소시킨다.
결론에서는 두 가지 주요 기여를 강조한다. 첫째, 간단한 1‑D CNN이 원시 파형으로부터 로그 스케일 멜 스펙트로그램을 정확히 학습할 수 있음을 실증하였다. 둘째, 이렇게 학습된 변환을 엔드투엔드 분류기에 초기화하고 고정함으로써, 전처리된 멜 스펙트로그램을 직접 사용했을 때와 비슷한 성능을 얻었다는 점이다. 향후 연구 방향으로는 초기 층을 고정하지 않고 미세 조정(fine‑tuning)하여 보다 풍부한 표현을 학습하거나, 대규모 비라벨 오디오 데이터를 활용해 사전 학습을 확장하는 것이 제시된다. 이러한 접근은 Jaitly와 Hinton의 비지도 RBM 기반 방법과 유사하게, 비라벨 데이터로부터 강건한 오디오 특징을 추출하는 데 기여할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기