컨텍스트 인식 RNN을 활용한 고성능 음성 역잔향 모델
본 논문은 짧은 시간의 로컬 컨텍스트는 2‑D 합성곱 인코더로, 긴 시간 의존성은 3‑층 GRU 디코더와 잔차 연결로 학습하는 새로운 음성 역잔향 시스템을 제안한다. 시뮬레이션 및 실제 방 반향 응답(RIR) 데이터에서 기존 T60‑aware 모델을 능가하며, PESQ +0.4, STOI +0.3, POLQA +1.0의 객관적 향상을 보이고 주관 청취 실험에서도 인지된 잔향 감소가 확인되었다.
저자: Joao Felipe Santos, Tiago H. Falk
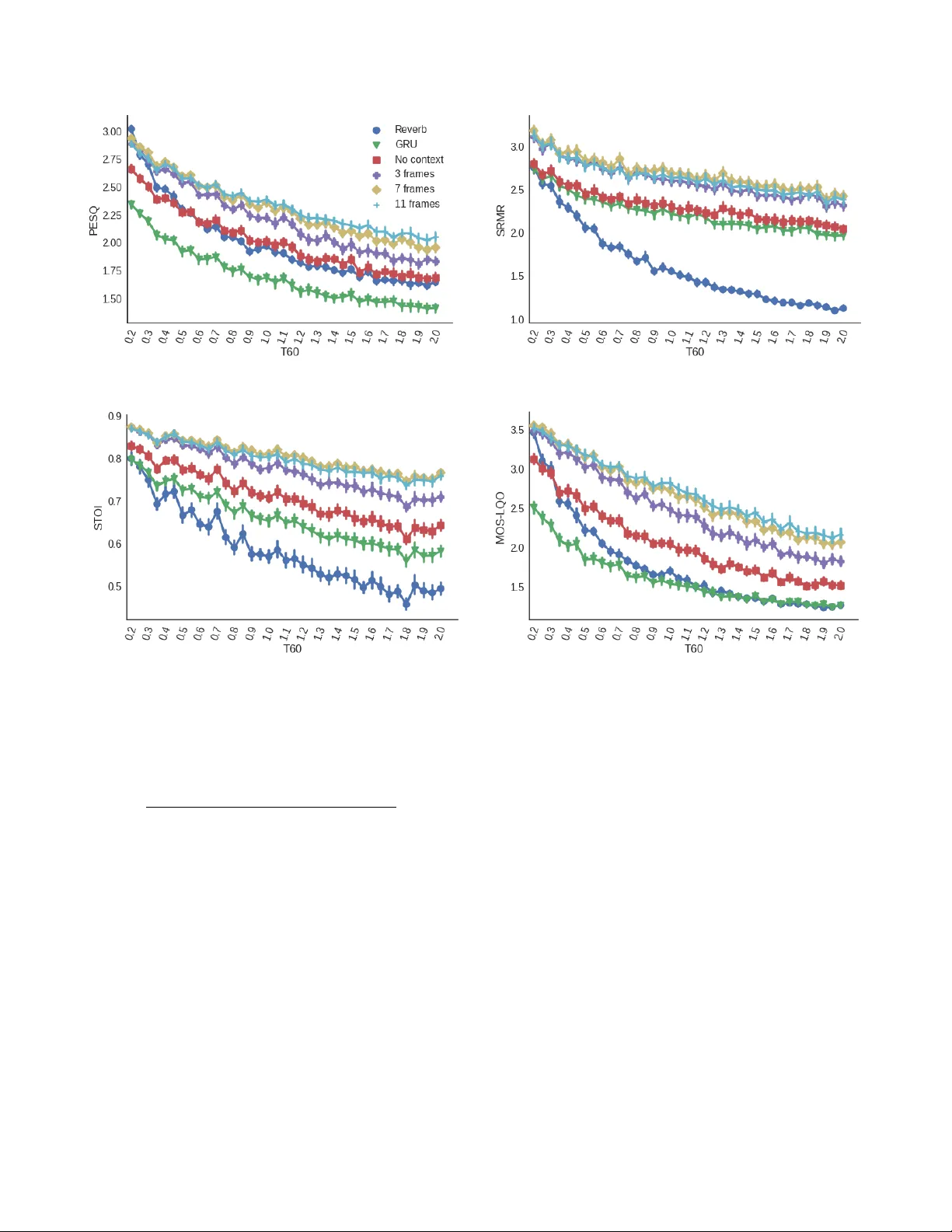
본 논문은 음성 신호의 역잔향(dereverberation) 문제를 해결하기 위해, 짧은 시간의 로컬 컨텍스트와 긴 시간의 전역 컨텍스트를 동시에 활용하는 새로운 딥러닝 구조를 제안한다. 기존 연구들은 주로 고정된 프레임 윈도우를 입력으로 하는 피드포워드 신경망을 사용하거나, T₆₀(전역 잔향 시간) 정보를 별도로 제공하는 방식에 의존해 왔다. 이러한 접근법은 로컬 패턴을 충분히 포착하지 못하거나, 실제 환경에서 T₆₀를 정확히 추정하기 어려운 단점이 있다.
제안된 모델은 크게 두 부분으로 나뉜다. 첫 번째는 컨텍스트 인코더(context encoder)로, 2‑D 합성곱 레이어 하나를 사용한다. 커널 크기는 (21 × C)이며, 여기서 C는 시간축에서 고려하는 프레임 수이다. 예를 들어 C = 11이면 현재 프레임을 중심으로 과거 5프레임과 미래 5프레임을 포함한다. 이 합성곱은 주파수 축에 stride = 2를 적용해 차원을 절반으로 축소하면서도, 시간 축은 그대로 유지해 연속적인 프레임 정보를 보존한다. 결과적으로 (F, T) 형태의 특성 맵이 생성되며, F는 64 × ⌊B/2⌋ + 1 (B = 257) 로 계산된다.
두 번째는 디코더(decoder)로, 256 유닛을 갖는 3개의 GRU 레이어가 순차적으로 쌓여 있다. 각 레이어는 입력으로 인코더 출력과 이전 레이어의 은닉 상태를 선형 변환한 뒤 합산한다. 구체적으로 i₁(t)=x_enc(t), i₂(t)=f₂(x(t))+g₁,₂(h₁(t)), i₃(t)=f₃(x(t))+g₁,₃(h₁(t))+g₂,₃(h₂(t))와 같은 형태이며, f와 g는 학습 가능한 affine projection이다. 이러한 잔차 연결은 각 GRU가 현재 프레임의 로컬 정보와 장기 의존성을 동시에 활용하도록 돕는다. 최종 출력 레이어는 세 은닉 상태를 각각 변환한 뒤 합산한 값을 입력으로 받아, 스펙트럼 크기 추정값을 직접 출력한다.
학습은 MSE 손실을 최소화하도록 Adam 옵티마이저(learning rate = 0.001, β₁ = 0.9, β₂ = 0.999)로 100 epoch 진행했으며, 가장 낮은 검증 손실을 보인 epoch의 모델을 최종 모델로 선택한다. 시퀀스 길이가 가변적인 점을 고려해 배치 내 패딩 마스크를 적용해 손실 계산 시 유효한 타임스텝만 반영하였다.
실험은 두 가지 데이터셋을 사용한다. 첫 번째는 IEEE 단일 화자 데이터(남성 화자)이며, 72개의 리스트 중 67를 훈련, 5를 테스트에 사용했다. 두 번째는 TIMIT 다중 화자 데이터로, 462명의 화자를 훈련·검증에, 168명을 테스트에 활용했다. 두 경우 모두 이미지 소스 메서드 기반 fast implementation을 이용해 740개의 RIR을 생성했으며, T₆₀는 0.2 s부터 2.0 s까지 0.05 s 간격으로 변한다. 각 RIR에 대해 50개의 무작위 발화를 합성해 약 37,000개의 훈련 샘플을 만들고, 5 %를 검증용으로 분리하였다. 테스트 셋은 별도의 RIR과 발화 조합으로 구성했다. 또한 ACE Challenge에서 제공한 실제 RIR 28개(7개의 방, 2개의 마이크 위치)로 실험을 확장해 일반화 성능을 검증하였다.
비교 대상은 (1) T₆₀‑aware 모델
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기