합성 오디오 사운드 이벤트 검출 성능 종합 분석
본 논문은 DCASE 2016 과제 2에서 제공된 사무실 환경 합성 음향 데이터를 이용해 10개의 사운드 이벤트 검출 시스템을 평가한다. 이벤트‑배경 비율(EBR), 폴리포니(단일·다중 이벤트) 및 이벤트 수(n_ec) 등 세 가지 실험 요인을 변형하여 시스템별 F‑measure(F_cweb)를 통계적으로 분석하였다. 결과는 배경 잡음 수준이 성능에 가장 큰 영향을 미치며, 일부 시스템은 폴리포니와 이벤트 수 변화에 강인함을 보인다.
저자: Gregoire Lafay (1), Emmanouil Benetos (2), Mathieu Lagrange (3) ((1) IRCCyN
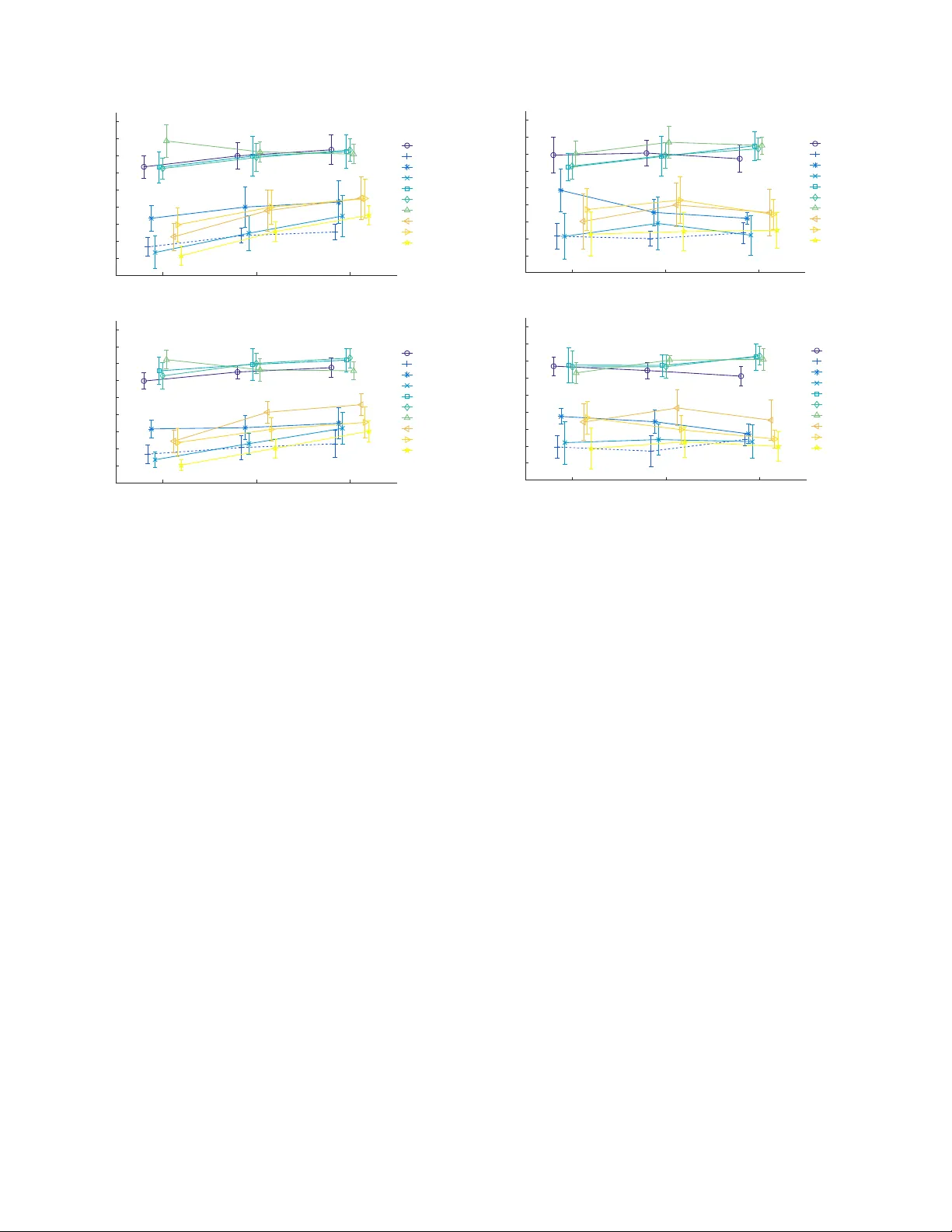
본 논문은 2016년 DCASE 공개 평가 챌린지의 두 번째 과제, 즉 ‘Synthetic Audio에서의 Sound Event Detection’에 대한 전반적인 연구 결과를 제시한다. 과제의 목표는 사무실 환경에서 수집된 11가지 소리 클래스를 기반으로 인위적으로 합성한 오디오 시퀀스에서 다중 사운드 이벤트를 정확히 탐지·분류하는 시스템의 성능을 평가하는 것이다. 이를 위해 연구팀은 LS2N(프랑스)에서 녹음된 단일 이벤트 샘플 220개(클래스당 20개)를 훈련 데이터로 사용하고, 동일한 샘플을 변형·조합해 개발·시험 데이터셋을 구축하였다. 각 씬은 이벤트‑배경 비율(EBR)과 이벤트 수(n_ec)를 조절해 18가지 실험 조건을 만들고, 각 조건을 3번씩 복제해 총 54개의 2분 길이 씬(시험 데이터)과 18개의 씬(개발 데이터)을 확보하였다.
평가 지표는 클래스별 이벤트 기반 F‑measure(F_cweb)이며, 이벤트 시작 시점이 실제 시작으로부터 ±200 ms 이내이고 라벨이 일치하면 정답으로 간주한다. 기존 DCASE 2016 웹사이트에서는 모든 씬을 시간적으로 연결해 하나의 지표를 산출했지만, 본 연구는 씬별로 개별 지표를 계산하고 이를 그룹별 평균으로 사용해 통계적 유의성을 검증하였다. 구체적으로는 (1) 전체 시스템 간 차이, (2) 단일·다중 씬 차이, (3) EBR·n_ec가 시스템 성능에 미치는 영향 등을 반복측정 ANOVA와 사후 Tukey‑Kramer 검정을 통해 분석하였다.
제출된 10개의 시스템은 특징 추출, 배경 추정·제거, 분류기의 조합으로 구성된다. 특징으로는 Mel/Bark 스펙트로그램, Variable‑Q Transform(VQT), Constant‑Q Transform(CQT), MFCC, GTCC 등이 사용되었으며, 분류기로는 NMF 기반 모델, DNN(MLP, CNN, RNN·BLSTM), Random Forest, K‑Nearest Neighbor 등 다양한 기법이 적용되었다. 각 시스템은 논문에 제시된 표 2에 요약되어 있다.
전체 성능 분석 결과, 시스템 종류가 유의한 차이를 보였으며(F = 466, p < 0.01) 사전 정의된 네 그룹으로 군집화되었다. 1그룹(Komatsu, Hayashi 1·2, Choi)은 평균 F_cweb가 0.67‑0.71로 가장 우수했으며, 특히 배경 잡음이 높은 상황에서도 강인한 성능을 유지했다. 2그룹(Phan, Giannoulis, Pikrakis)은 0.34‑0.36 수준, 3그룹(Baseline, Vu, Gutierrez)은 0.21‑0.23, 4그룹(Kong)은 0.02에 불과했다. 7개의 시스템이 베이스라인보다 통계적으로 유의하게 향상되었으며, 특히 배경 잡음 추정·제거를 수행한 시스템이 높은 점수를 기록했다.
폴리포니(단일 vs. 다중) 분석에서는 전체적으로 시스템 성능에 큰 차이가 없었지만(F = 3.5, p = 0.07), 특정 시스템(Choi, Giannoulis, Komatsu, Pikrakis)은 다중 씬에서 성능 저하를 보였다. 이는 다중 이벤트가 겹칠 때 정확한 온셋 구분이 어려워 발생한 현상으로 해석된다.
EBR(배경 수준) 변화에 대한 분석에서는 모든 시스템이 EBR이 높을수록(F = 164~127, p < 0.01) 성능이 향상되는 경향을 보였으며, 이는 신호 대 잡음비가 높을수록 이벤트를 더 명확히 감지할 수 있기 때문이다. 다만 Komatsu 시스템만은 EBR이 낮을수록 성능이 감소했으며, 이는 테스트 단계에서 학습된 잡음 사전(dictionary) 기반 배경 추정이 부정확하게 작동했기 때문으로 추정된다.
이벤트 수(n_ec) 변화에 대해서는 전반적인 주효과가 없었지만(F = 0.5~0.1, p > 0.05), 시스템별 상호작용이 존재하였다. Hayashi 1·2는 이벤트 수가 증가할수록 성능이 상승했으며, Giannoulis와 Pikrakis는 반대로 감소하였다. 이는 각 시스템이 채택한 특징 및 분류 모델이 이벤트 밀도에 대한 민감도가 다름을 보여준다.
특징 추출 측면에서 4개의 상위 그룹 시스템 중 3개가 Mel 스펙트로그램을 사용했으며, 배경 추정·제거를 명시적으로 수행한 시스템이 가장 높은 성능을 기록했다. 반면, 배경 처리를 생략한 Kong 시스템은 전반적으로 최저 성능을 보였으며, 이는 데이터 양이 제한된 상황에서 DNN 기반 분류기가 충분히 학습되지 못한 것이 원인으로 보인다.
결론적으로, 본 연구는 합성 데이터의 정확한 라벨링과 제어된 복잡도 변수를 활용해 SED 시스템의 강점과 약점을 정량적으로 규명하였다. 특히 배경 잡음에 대한 견고한 처리와 다중 이벤트 구분 능력이 시스템 성능에 결정적인 영향을 미치며, 향후 연구에서는 실제 환경에서의 잡음 다양성 및 이벤트 겹침을 보다 정교히 모델링하는 것이 필요함을 시사한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기