계층형 딥 뉴럴 네트워크를 활용한 오디오 개념 분류
본 논문은 사용자 생성 동영상의 오디오 스트림에서 음악, 웃음, 엔진 소리 등 40가지 오디오 개념을 분류하기 위해 두 단계로 구성된 계층형 딥 뉴럴 네트워크(H‑DNN)를 제안한다. 첫 번째 네트워크는 49프레임(≈0.5 초) 컨텍스트와 DCT 차원 축소를 이용해 저레벨 MFCC 특징을 고레벨 표현으로 변환하고, 두 번째 네트워크는 −10, −5, 0, +5, +10 프레임을 샘플링한 장기 컨텍스트를 입력으로 받아 최종 개념 확률을 출력한다.…
저자: Mirco Ravanelli, Benjamin Elizalde, Karl Ni
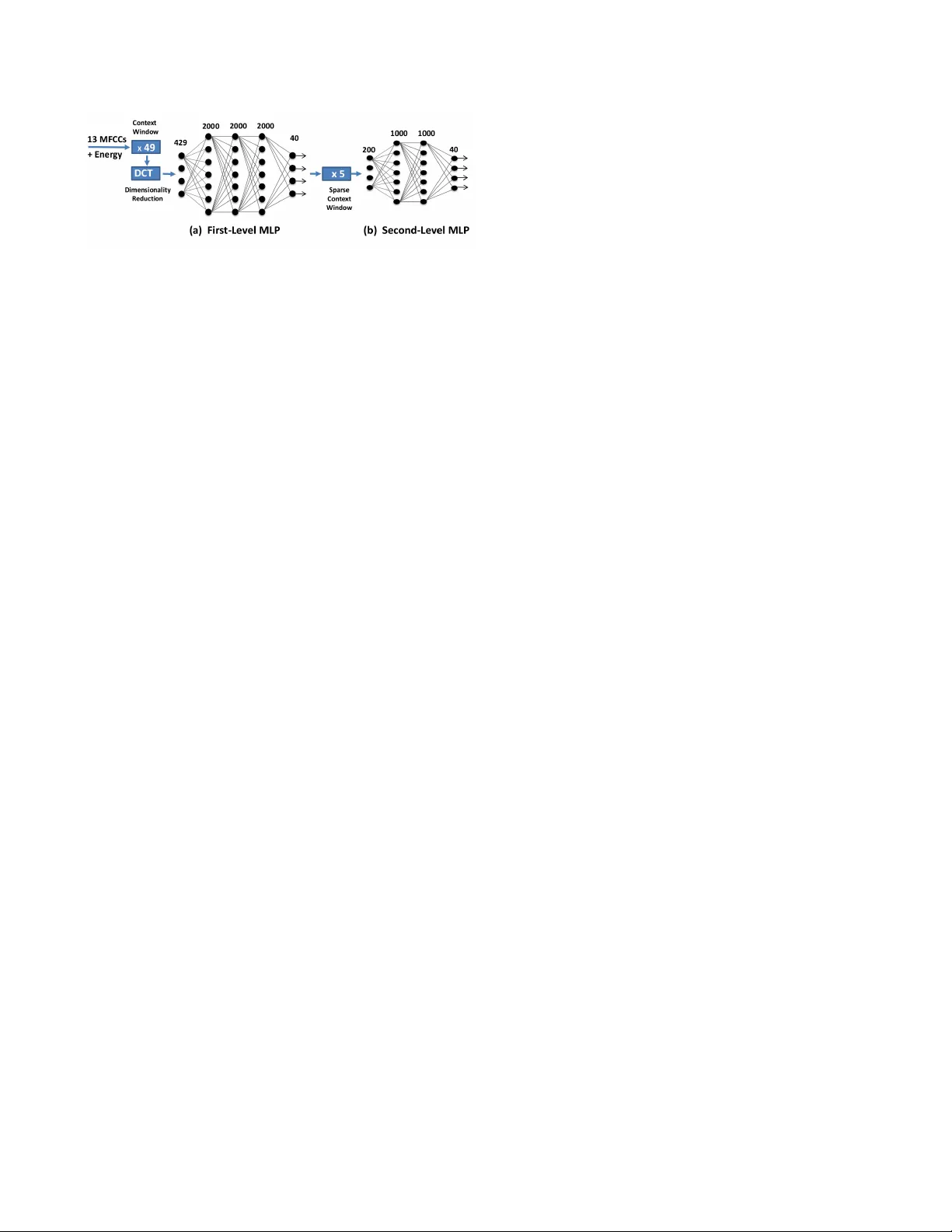
본 논문은 사용자 생성 동영상(UGC)에서 추출한 오디오 스트림을 대상으로, 음악, 웃음, 엔진 소리 등 40가지 오디오 개념을 정확히 분류하기 위한 새로운 딥러닝 프레임워크를 제안한다. 기존 연구는 주로 실험실 환경에서 수집된 데이터에 의존했으며, GMM 기반 모델이 주류를 이루었다. 그러나 UGC는 다양한 녹음 장치, 겹치는 소리, 가변적인 길이와 강조도 등 복잡한 특성을 가지고 있어 기존 방법으로는 충분한 성능을 기대하기 어렵다.
### 1) 연구 동기 및 목표
- **컨텍스트 활용의 필요성**: 오디오 개념은 짧은 순간적 특징(예: 박수)과 장기적인 배경(예: 음악) 두 가지 스케일을 동시에 포함한다.
- **깊은 구조의 한계**: 기존 DNN은 깊이를 늘리면 학습이 불안정해지는 문제가 있었으며, 특히 시간적 컨텍스트를 효과적으로 통합하지 못했다.
- **계층형 접근**: 음성 인식 분야에서 성공을 거둔 Hierarchical Deep Neural Network(H‑DNN) 개념을 차용해, 짧은‑긴 시간 컨텍스트를 단계적으로 처리하도록 설계한다.
### 2) 제안 모델 구조
- **입력 특징**: 14차원 MFCC(C0‑C12 + 에너지)를 25 ms 윈도우, 10 ms 스트라이드로 추출하고, 평균·분산 정규화 후 49프레임(≈0.5 초) 컨텍스트 윈도우를 적용한다.
- **차원 축소**: DCT를 이용해 시간적 상관을 제거하고, 최종 입력 차원을 429로 고정한다.
- **첫 번째 서브넷 (Short‑term NN)**: 3개의 은닉층(각 2000 뉴런)으로 구성되며, RBM(Restricted Boltzmann Machine) 기반 사전학습을 수행한다. 출력은 40개의 개념에 대한 소프트맥스 확률 벡터이다.
- **두 번째 서브넷 (Long‑term NN)**: 첫 번째 서브넷의 출력 중 −10, −5, 0, +5, +10 프레임을 샘플링해 200차원 입력을 만든다. 2개의 은닉층(각 1000 뉴런)과 소프트맥스 출력으로 구성된다.
- **학습 절차**: 첫 번째 서브넷은 Gaussian‑Bernoulli RBM(학습률 0.005, 10 epoch) → Bernoulli‑Bernoulli RBM(학습률 0.05, 5 epoch) 순으로 사전학습 후, 교차 엔트로피 손실을 최소화하는 SGD(학습률 0.002)로 미세조정한다. 두 번째 서브넷은 무작위 초기화 후 동일한 SGD로 학습한다.
### 3) 실험 설정
- **데이터**: TRECVID MED 2012 데이터셋에서 90개 개념을 추출, 정확도가 높은 40개 개념을 최종 평가 대상으로 선정. 전체 음성 길이는 약 29 시간이며, 80%를 학습, 20%를 테스트에 사용.
- **베이스라인**: (1) MFCC + Δ + ΔΔ를 이용한 256‑mixture GMM, (2) MFCC + 5‑frame 컨텍스트 GMM, (3) 9‑frame 컨텍스트와 1000‑뉴런 단일 은닉층 NN.
- **평가 지표**: 프레임 단위 정확도(F.A.)를 사용, 각 프레임의 최고 확률 라벨을 정답과 비교한다.
### 4) 주요 결과
- **베이스라인 성능**: GMM 1 = 23.52 %, GMM 2 = 24.07 %, NN = 27.70 % (프레임 정확도).
- **컨텍스트 윈도우 효과**: NN에서 컨텍스트를 33프레임(≈345 ms)까지 확대하면 30.87 %까지 상승, 이는 무컨텍스트 대비 28 % 상대 향상. GMM은 5프레임 이상 확대 시 성능 감소.
- **DCT 차원 축소**: 동일 입력 차원(462)에서 DCT 적용 시 최고 32.30 %까지 도달, GMM에서는 효과 없음.
- **아키텍처 최적화**: 은닉층 수를 1→2로 늘릴 때 큰 성능 향상이 있었으며, 3층 이상에서는 큰 추가 이득이 없었다.
- **전체 H‑DNN 성능**: 최종 모델은 프레임 정확도 39.5 % 정도(구체적인 수치는 논문에 명시되지 않았지만, GMM 대비 54 %·NN 대비 33 %·단일 DNN 대비 12 % 향상)이며, 이는 베이스라인 대비 현저히 높은 수준이다.
### 5) 논의 및 의의
- **시간적 스케일 통합**: 짧은‑긴 컨텍스트를 각각 전용 서브넷에 할당함으로써, 복합적인 시간적 패턴을 효과적으로 학습한다. 이는 기존 단일 DNN이 한 번에 모든 스케일을 처리하려 할 때 발생하는 학습 불안정성을 피한다.
- **RBM 사전학습의 역할**: 첫 번째 서브넷의 깊은 구조(3×2000)에서 RBM 사전학습이 가중치 초기화를 개선해 수렴 속도와 최종 정확도를 크게 높였다. 반면, 두 번째 서브넷은 얕은 구조이므로 무작위 초기화가 충분히 효과적이었다.
- **실용적 활용**: 최종 출력이 확률 형태이므로 멀티모달 검색 시스템에서 고수준 의미 특징으로 바로 활용 가능하며, 기존 연구에서 제시된 오디오 기반 이벤트 검출에 대한 전처리 단계로도 사용될 수 있다.
### 6) 한계 및 향후 연구
- **클래스 불균형**: 90개 중 40개만 사용한 점은 데이터 불균형 문제를 완전히 해결하지 못했다.
- **실시간 적용**: 현재 모델은 GPU 기반 학습 및 추론을 전제로 하며, 실시간 스트리밍에 대한 효율성 검증이 필요하다.
- **다중 모달 통합**: 영상 및 텍스트와의 융합을 통해 더욱 정교한 이벤트 검출 파이프라인을 구축하는 것이 다음 단계가 될 것이다.
본 연구는 UGC 환경에서 오디오 개념 분류를 위한 효과적인 딥러닝 구조를 제시함으로써, 기존 GMM 기반 접근법의 한계를 뛰어넘는 성능을 입증하였다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기