하이악 사망 모니터링: 저비용·고정밀 샘플링 혁신
본 논문은 남아프리카 Agincourt HDSS를 기반으로 ‘Hyak’이라는 새로운 사망 모니터링 시스템을 제안한다. Hyak은 HDSS와 인접 지역의 표본조사를 연계한 ‘정보 기반 샘플링(informed sampling)’과 공간적 스무딩을 결합해 전통적 군집표본에 비해 사망 사건을 더 많이 포착하고, 추정치의 분산을 감소시키며 편향을 최소화한다는 시뮬레이션 결과를 제시한다.
저자: Samuel J. Clark, Jon Wakefield, Tyler McCormick
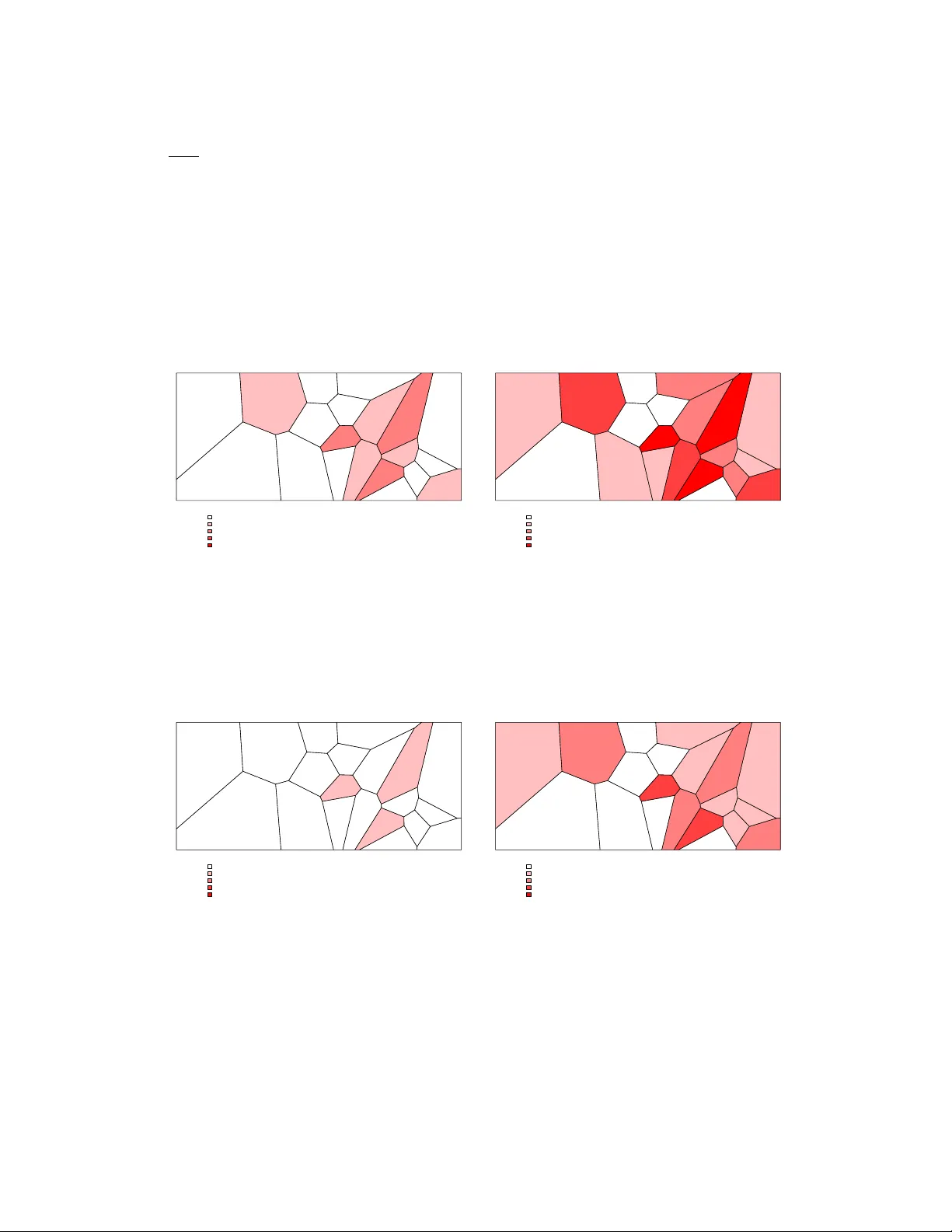
논문은 저소득·중소득 국가에서 전통적인 시민등록·사망통계가 미비하거나 전혀 존재하지 않는 현실을 지적하며, 이러한 상황에서 공공보건 정보를 얻기 위한 대안으로 ‘데이터 융합(data amalgamation)’과 ‘데이터 풀링(data pooling)’ 개념을 구분한다. 데이터 풀링은 기존에 수집된 이질적 데이터를 사후에 통계적으로 보정하는 접근법인 반면, 데이터 융합은 데이터 수집 단계부터 여러 출처를 의도적으로 설계에 포함시켜 편향·분산을 최소화하고 비용 효율성을 높이는 전략이다. 이러한 배경에서 저자들은 Hyak(Hybrid Adaptive Knowledge)라는 새로운 통계 플랫폼을 제안한다. Hyak은 세 가지 핵심 구성요소로 이루어진다. 첫째, 데이터 융합을 위한 ‘샘플링·감시’ 모듈로, HDSS와 인접 지역의 표본조사를 연계한다. HDSS는 고밀도·장기 추적 데이터를 제공하고, 인접 지역은 ‘정보 기반 샘플링(informed sampling)’을 통해 사망 사건이 많이 발생할 가능성이 높은 가구·마을에 표본을 집중한다. 둘째, 원인별 사망을 파악하기 위한 ‘구두 사망진단(Verbal Autopsy)’을 적용한다. 셋째, 사회경제적 지표(SES)를 측정해 빈곤·부유 수준을 함께 추정한다.
연구는 Agincourt HDSS(남아프리카공화국)를 모델 지역으로 삼아 시뮬레이션을 수행한다. 시뮬레이션 설계는 다음과 같다. (1) 각 마을의 인구·연령·성별·SES 등 사전 정보를 이용해 사망률을 베이즈 공간 회귀 모델로 예측한다. (2) 예측된 사망률을 기반으로 ‘최적 할당(optimum allocation)’ 방식으로 표본 크기를 마을별로 배분한다. (3) 두 가지 표본 설계—전통적 군집 무작위 표본과 Hyak의 정보 기반 샘플링—를 동일 비용(표본 수·조사 인력) 조건에서 비교한다. (4) 추정 단계에서는 공간 스무딩을 포함한 베이즈 계층 모델을 사용해 전체 인구의 사망률과 사망 수를 추정한다.
결과는 크게 세 가지 측면에서 차이를 보였다. 첫째, Hyak은 동일 표본 규모에서 평균 25 %~35 % 더 많은 사망 사건을 포착했다. 이는 사망이 집중된 지역을 사전에 식별해 표본을 집중함으로써 가능했다. 둘째, 추정된 사망률의 평균 제곱오차(MSE)는 전통적 군집 표본 대비 30 %~45 % 감소했으며, 특히 희귀 원인 사망(예: 신생아 사망)에서 편차가 크게 줄었다. 셋째, 편향은 거의 없었으며, 공간 스무딩을 적용함으로써 마을 간 변동성을 효과적으로 조정했다.
논의에서는 Hyak의 장점으로 비용 효율성, 높은 사건 포착률, 공간적 정밀도 향상을 강조한다. 또한, 사전 모델의 정확도가 전체 시스템 성능에 큰 영향을 미치므로, 현지 데이터(인구 조사, 보건 기록 등)를 지속적으로 업데이트하는 것이 필요하다고 제언한다. 한계점으로는 HDSS가 없는 지역에서는 초기 베이스라인 구축이 어렵고, 시뮬레이션이 실제 현장 복잡성을 완전히 반영하지 못한다는 점을 들었다. 향후 연구에서는 실제 현장 파일럿 테스트, 다양한 국가·문화적 맥락 적용, 그리고 비용-효과 분석을 통해 Hyak을 글로벌 보건 모니터링 체계에 통합하는 방안을 모색한다. 최종적으로 저자는 Hyak이 저비용·고정밀 사망 모니터링을 위한 실용적인 프레임워크이며, 특히 저소득 국가에서 지속 가능한 보건 데이터 확보에 기여할 수 있다고 결론짓는다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기