데이터 기반 라벨 공간 분할이 무작위 선택보다 우수한 이유
본 논문은 다중 라벨 분류에서 라벨 공간을 무작위로 나누는 RAkELd 방식 대신, 학습 데이터로부터 라벨 동시 발생 그래프를 구축하고 사회·복합 네트워크의 커뮤니티 탐지 알고리즘(FASTGREEDY, LEADING EIGENVECTOR, INFOMAP, WALKTRAP, LABEL PROPAGATION)을 적용해 라벨을 의미 있는 집합으로 분할한다. 12개 데이터셋과 5가지 평가 지표(F1, 서브셋 정확도, Jaccard, Hamming Lo…
저자: Piotr Szymanski, Tomasz Kajdanowicz, Kristian Kersting
본 논문은 다중 라벨 분류에서 라벨 공간을 어떻게 나누는가가 최종 성능에 큰 영향을 미친다는 점에 주목한다. 기존의 RAkELd(Random k‑Labelsets – disjoint) 방법은 라벨을 무작위로 동일 크기의 서브셋으로 나누어 각 서브셋에 라벨 파워셋(Label Powerset) 방식을 적용한다. 그러나 라벨 간 상관관계를 고려하지 않기 때문에 비효율적인 파티션이 생성될 위험이 있다. 이를 개선하기 위해 저자들은 라벨 동시 발생 그래프를 구축한다. 그래프의 정점은 라벨이며, 두 라벨이 같은 샘플에 동시에 나타난 횟수를 가중치로 하여 간선을 만든다(가중 그래프) 혹은 단순히 동시 발생 여부만을 이용해 비가중 그래프를 만든다. 이렇게 만든 그래프에 사회·복합 네트워크 분야에서 검증된 다섯 가지 커뮤니티 탐지 알고리즘을 적용한다.
1. **FASTGREEDY** – 모듈러티를 최대화하는 탐욕적 병합 알고리즘.
2. **LEADING EIGENVECTOR** – 그래프 라플라시안의 가장 큰 고유벡터를 이용한 스펙트럼 분할.
3. **INFOMAP** – 무작위 워크를 통한 정보 흐름 최소화 원리 기반.
4. **WALKTRAP** – 랜덤 워크가 오래 머무는 영역을 커뮤니티로 간주.
5. **LABEL PROPAGATION** – 라벨을 이웃에게 전파시켜 수렴된 라벨을 커뮤니티로 정의.
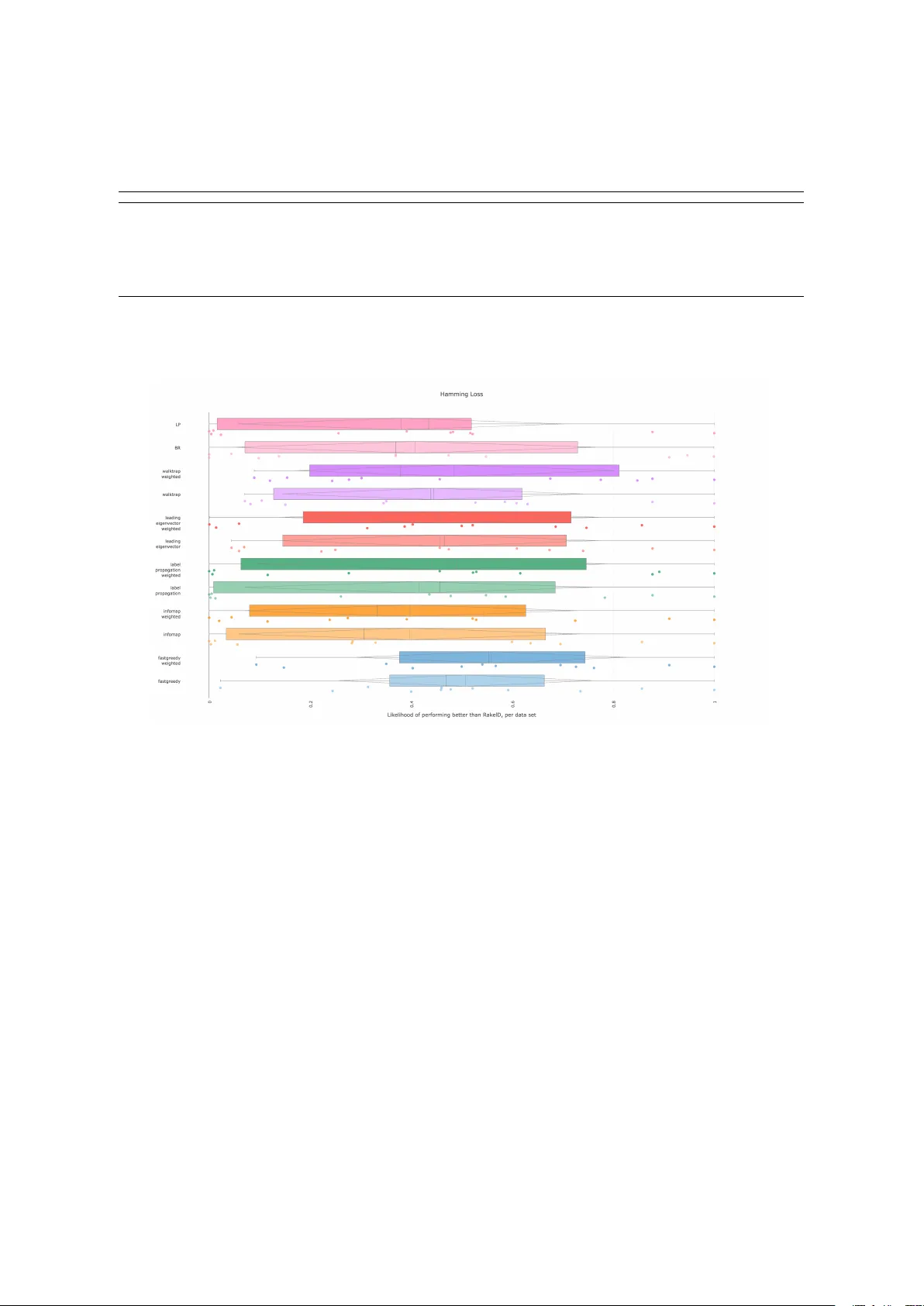
각 방법은 가중 그래프와 비가중 그래프 두 경우에 적용되며, 결과적으로 라벨 집합을 의미 있는 그룹으로 나눈다. 이후 각 그룹에 대해 라벨 파워셋을 적용하고, 베이스 분류기로는 Gini 지수를 사용한 CART 결정 트리를 사용한다. 실험은 12개의 다중 라벨 벤치마크 데이터셋(예: bibtex, yeast, emotions 등)과 5가지 평가 지표(마이크로·매크로 F1, 서브셋 정확도, Jaccard 유사도, Hamming Loss)를 사용해 수행되었다. RAkELd의 무작위 파티션을 250번 반복해 평균 및 최악 경우 성능을 수집하고, 데이터 기반 파티션과 비교하였다.
통계적 분석 결과, **FASTGREEDY와 WALKTRAP**이 가중 그래프에서 F1 점수 향상 확률을 85~92%로 가장 높게 나타냈으며, **INFOMAP**은 비가중 그래프에서 서브셋 정확도와 Jaccard 유사도에서 각각 90%와 89%의 확률로 무작위보다 우수했다. Hamming Loss에서는 가중 FASTGREEDY가 평균적으로 RAkELd보다 낮은 손실을 기록하였다. 또한, 데이터 기반 파티션은 최악 상황에서도 무작위 파티션보다 높은 확률로 우수한 성능을 보였으며, 이는 라벨 간 구조적 정보를 활용함으로써 모델의 안정성과 일반화 능력이 향상된다는 것을 의미한다.
논문은 또한 기존 연구와의 차별점을 강조한다. HOMER와 같은 계층적 라벨 클러스터링 방법은 강력한 베이스 분류기를 사용해 라벨 서브스페이스를 선택하는 반면, 본 연구는 라벨 자체의 관계를 그래프 형태로 모델링하고, 비교적 약한 CART 트리를 사용해도 데이터 기반 파티션이 무작위보다 일관되게 좋은 결과를 낸다. 이는 라벨 공간 분할 단계에서 복잡한 네트워크 분석 기법을 도입하는 것이 다중 라벨 학습 파이프라인 전체에 긍정적인 영향을 미칠 수 있음을 시사한다.
결론적으로, 라벨 동시 발생 그래프를 기반으로 한 커뮤니티 탐지는 라벨 공간을 의미 있게 나누어 라벨 파워셋 기반 다중 라벨 분류기의 성능을 크게 향상시킨다. 향후 연구에서는 더 다양한 그래프 구축 방식(예: TF‑IDF 가중치, 정규화된 공분산)과 다른 베이스 학습기(예: SVM, 신경망)를 결합해 성능을 추가로 검증할 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기