트위터로 우울증 탐지
본 논문은 트위터에 공개된 글을 이용해 사용자가 우울증을 겪고 있는지를 자동으로 판별하는 모델을 제안한다. Coppersmith 등(2015)의 CLPsych 공유 데이터셋을 활용해, 최대 1년간의 트윗 3,000개를 Bag‑of‑Words 방식으로 벡터화하고, 여러 전통적 분류기(SVM, 로지스틱 회귀, 랜덤 포레스트 등)를 학습시켰다. 최종 모델은 약 82% 정확도와 0.86의 정밀도를 달성했으며, 텍스트 수준에서 우울증 신호를 포착한다는 …
저자: Moin Nadeem
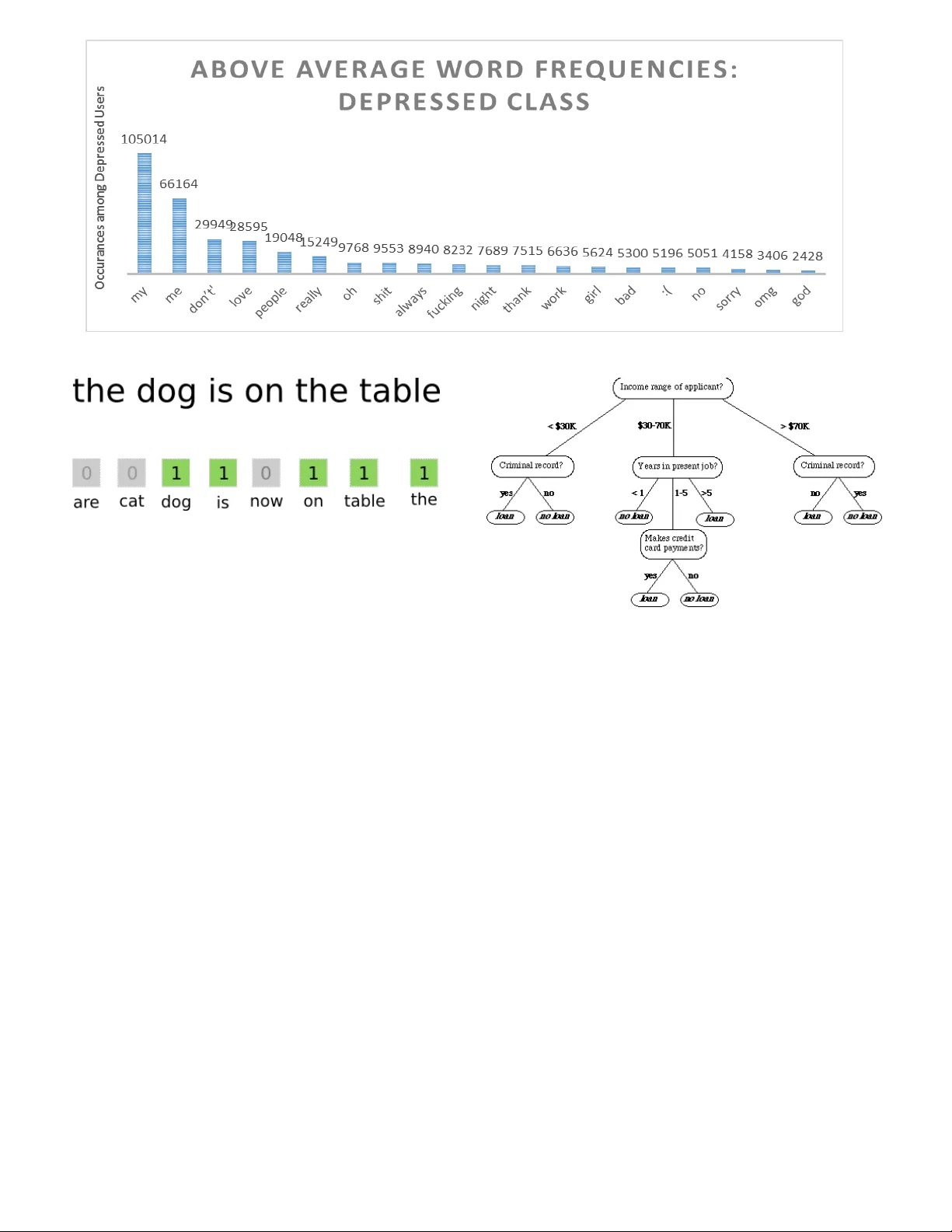
본 논문은 소셜 미디어, 특히 트위터가 개인의 정신건강 상태를 반영할 수 있다는 가설 하에, 우울증 진단을 공개한 사용자를 대상으로 자동 판별 모델을 개발하고 평가한다. 연구 배경에서는 우울증이 미국 성인 1인당 4명 중 1명에게 영향을 미치며, 경제적·사회적 비용이 막대함을 강조한다. 기존 진단 방법이 주관적 설문에 의존하고, 실제 환자들의 진단률이 낮다는 문제점을 지적한 뒤, 디지털 발자국을 활용한 객관적 진단 가능성을 제시한다.
데이터는 2015년 CLPsych 공유 작업에서 제공된 Coppersmith 등(2015) 데이터셋을 사용한다. 이 데이터셋은 우울증을 자가보고한 트위터 사용자와 대조군을 포함하며, 각 사용자는 최대 3,000개의 트윗(약 1년치)으로 구성된다. 연구팀은 크라우드소싱을 통해 추가 라벨링을 수행했으며, 모든 사용자 정보를 익명화하였다.
전처리 단계에서는 트윗에서 URL, 멘션, 해시태그 등을 제거하고, 토큰화를 수행한 뒤, Bag‑of‑Words 방식을 적용해 단어 빈도 피처를 생성한다. 피처는 전체 코퍼스에서 5천~1만개의 고유 단어를 포함하며, tf와 tf‑idf 두 가지 가중치를 실험하였다. 차원 축소 없이 원본 피처를 그대로 사용했으며, 이는 모델이 고차원 희소 데이터를 직접 학습하도록 설계된 것이다.
분류 모델로는 선형 SVM, 로지스틱 회귀, 랜덤 포레스트, 나이브 베이즈, 그리고 다층 퍼셉트론(MLP) 등 다섯 종류를 적용하였다. 각 모델은 5‑fold 교차 검증을 통해 하이퍼파라미터를 최적화했으며, 성능 평가는 정확도, 정밀도, 재현율, F1 점수, ROC‑AUC 등 다각도로 수행되었다. 결과적으로 선형 SVM이 82% 정확도와 0.86 정밀도를 기록하며 최고 성능을 보였고, 재현율은 0.73, F1 점수는 0.79 수준이었다. 다른 모델들은 정확도 75~80% 사이, 정밀도 0.70~0.84 정도를 보이며 전반적으로 높은 판별력을 나타냈다.
논문은 기존 연구와의 차별점을 강조한다. De Choudhury 등은 사용자 행동(소셜 네트워크 구조, 활동량)과 감정 사전 기반 피처를 결합해 72% 정도의 정확도를 달성했지만, 본 연구는 순수 텍스트 빈도만으로도 82% 수준의 정확도를 얻었다는 점에서 텍스트 기반 접근의 가능성을 입증한다. 또한, 기존 연구가 사용자 전체 트윗을 하나의 문서로 처리하거나 주간 단위로 묶는 반면, 본 논문은 개별 트윗을 독립적인 샘플로 간주해 문서‑레벨이 아닌 트윗‑레벨 분류를 수행한다는 점에서도 차별화된다.
하지만 연구에는 몇 가지 한계가 존재한다. 첫째, 라벨이 자가보고식 진단에 의존하기 때문에 라벨 노이즈가 존재한다. 둘째, 데이터는 공개적으로 우울증을 언급한 사용자에 국한되어 있어 일반 인구에 대한 외삽이 어려울 수 있다. 셋째, Bag‑of‑Words는 단어 순서와 문맥을 무시하므로, 부정어(‘안’, ‘못’)를 포함한 문장을 제대로 구분하지 못한다. 넷째, 모델이 높은 정밀도를 보였지만 재현율이 0.73에 머물러, 실제 우울증 환자를 놓칠 위험이 있다.
윤리적 측면에서도 저자들은 사용자 프라이버시 보호와 오탐에 따른 부정적 영향을 경고한다. 자동 진단 시스템이 의료 현장에 도입될 경우, 잘못된 경고가 환자에게 불필요한 스트레스를 유발하거나, 반대로 놓친 경우 치료 기회를 잃을 수 있다. 따라서 실제 적용 전에는 임상 전문가와의 협업, 사후 검증 절차, 그리고 사용자 동의 기반의 투명한 데이터 활용이 필수적이다.
향후 연구 방향으로는 문맥을 고려한 임베딩 모델(Word2Vec, GloVe, BERT 등)을 도입해 의미적 차이를 포착하고, 감정 사전 기반 피처와 결합해 하이브리드 모델을 구축하는 것이 제안된다. 또한, 이미지, 위치 정보, 팔로워·팔로잉 네트워크와 같은 멀티모달 데이터를 통합해 모델의 일반화 능력을 강화할 수 있다. 마지막으로, 라벨링 품질을 높이기 위해 임상 진단 결과와 연계된 데이터셋을 구축하고, 다양한 문화·언어권에서의 검증을 수행하는 것이 필요하다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기