한 번의 기회 세션을 위한 조합형 아이템 추천 최적화
본 논문은 신규 사용자에게 처음 제시하는 아이템 묶음이 세션 종료 여부를 좌우하는 ‘One‑Shot Session’ 상황을 모델링한다. 사용자 유형을 사전 정의된 M개의 클러스터로 가정하고, 각 라운드에서 k개의 아이템을 동시에 추천하는 조합형 행동을 취한다. 이를 마르코프 의사결정 과정(MDP)으로 정의하고, 즉시 보상이 단조·준-서브모듈러임을 이용해 Q‑함수에도 유사한 성질이 전이된다는 것을 증명한다. 그 결과, 전체 행동 공간이 |L|^k…
저자: Yahel David, Dotan Di Castro, Zohar Karnin
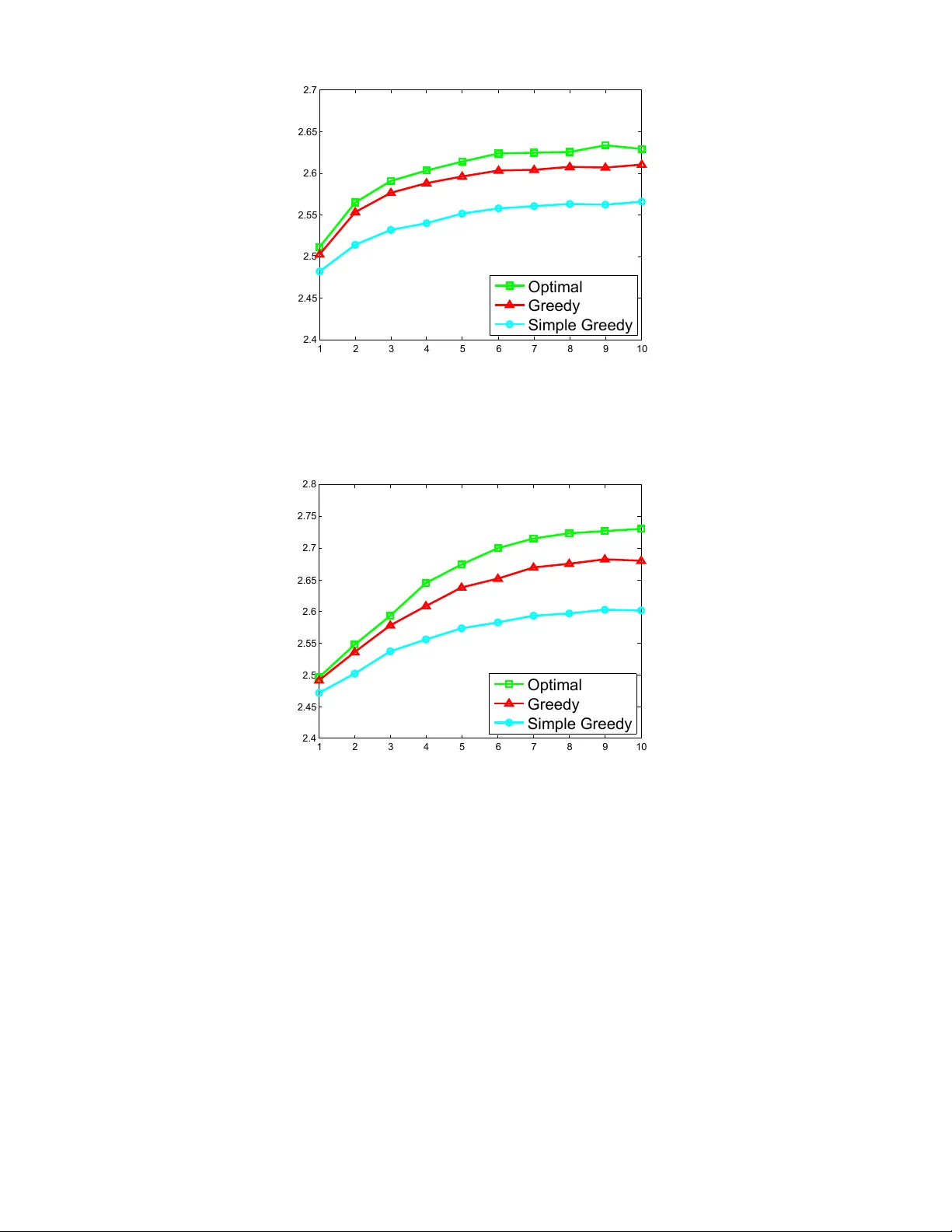
본 연구는 대형 콘텐츠 제공 사이트에서 신규 사용자를 맞이할 때, 초기 라운드에서 제시하는 아이템 묶음이 세션 종료에 직접적인 영향을 미치는 ‘One‑Shot Session’ 현상을 모델링하고 최적화한다. 기존 추천 시스템은 주로 장기적인 보상을 최적화하는데 초점을 맞추어 왔으며, 초기 라운드에서의 실수가 전체 성능에 미치는 영향이 제한적이라고 가정한다. 그러나 실제 서비스에서는 사용자가 첫 번째 혹은 두 번째 라운드에서 이탈할 가능성이 크며, 이러한 상황을 고려하지 않으면 콜드스타트 사용자를 효과적으로 끌어들이기 어렵다.
논문은 먼저 사용자 유형을 M개의 사전 정의된 클러스터(예: 성별, 소득 수준, 잠재적 선호도)로 가정하고, 각 유형에 대한 아이템 선택 확률 p(ℓ|m,w)를 사전에 학습한다. 여기서 ℓ는 아이템, w는 한 라운드에서 제시되는 최대 k개의 아이템 집합이다. 사용자의 현재 상태는 각 유형에 대한 베이즈 사후분포 c∈Δ^M 로 표현되며, 세션이 종료되면 별도의 종료 상태 c∅ 로 전이한다.
MDP의 구성 요소는 다음과 같다.
- 상태 공간 X = Δ^M ∪ {c∅}.
- 행동 공간 U = {w ⊆ L : |w| ≤ k}.
- 보상 함수 R(c,w,c′)는 사용자가 아이템을 선택하면 1, 세션이 종료되면 0이며, 즉시 보상은 선택 확률에 의해 결정된다.
- 전이 확률 P(c′|c,w)는 베이즈 규칙에 따라 사용자가 ℓ를 선택했을 때의 사후분포와, 선택되지 않을 확률(즉, 세션 종료 확률)로 정의된다.
목표는 할인계수 γ<1을 적용해 기대 누적 보상 E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기