스케일 정규화로 딥러닝 학습 가속화
본 논문은 신경망 층 사이의 스케일 불균형이 학습을 방해한다는 점에 주목하고, 학습 과정에서 등거리성(isometry)을 유지하기 위한 두 가지 정규화 기법—determinant 정규화와 stochastic scale 정규화—를 제안한다. MNIST에 대한 MLP 실험에서 초기 몇 에폭 동안 학습 속도가 현저히 빨라짐을 보이며, 특히 첫 번째 에폭 이후에는 효과가 감소한다는 결과를 제시한다.
저자: Henry Z. Lo, Kevin Amaral, Wei Ding
본 논문은 ‘Scale Normalization’이라는 제목 아래, 딥러닝 모델의 층 사이 스케일 불균형이 학습 효율에 미치는 영향을 조사한다. 서론에서는 기존 초기화 기법(Glorot, He, Saxe 등)이 전방·후방 스케일을 보존하도록 설계됐지만, 학습 중 가중치 업데이트가 이 조건을 깨게 된다는 점을 지적한다. 특히, 등거리성(isometry)이 유지되지 않으면 그래디언트가 폭발하거나 소실해 학습이 불안정해진다. 저자들은 초기 스케일 보존이 학습을 촉진한다는 기존 연구를 인용하면서, “학습 전 과정에서도 스케일을 유지하는 것이 유익한가?”라는 핵심 질문을 제기한다.
2절에서는 스케일을 수학적으로 정의한다. 전방 스케일은 ‖Wᵀx‖₂/‖x‖₂, 후방 스케일은 ‖Wd‖₂/‖d‖₂ 로 표현되며, 두 스케일 모두 특이값 σ_i에 의해 결정된다. 따라서 모든 특이값이 1이면 완전 등거리성을 달성한다. 기존의 orthonormal 초기화는 이 조건을 초기 단계에서만 만족시키며, 학습이 진행되면 특이값이 변동한다.
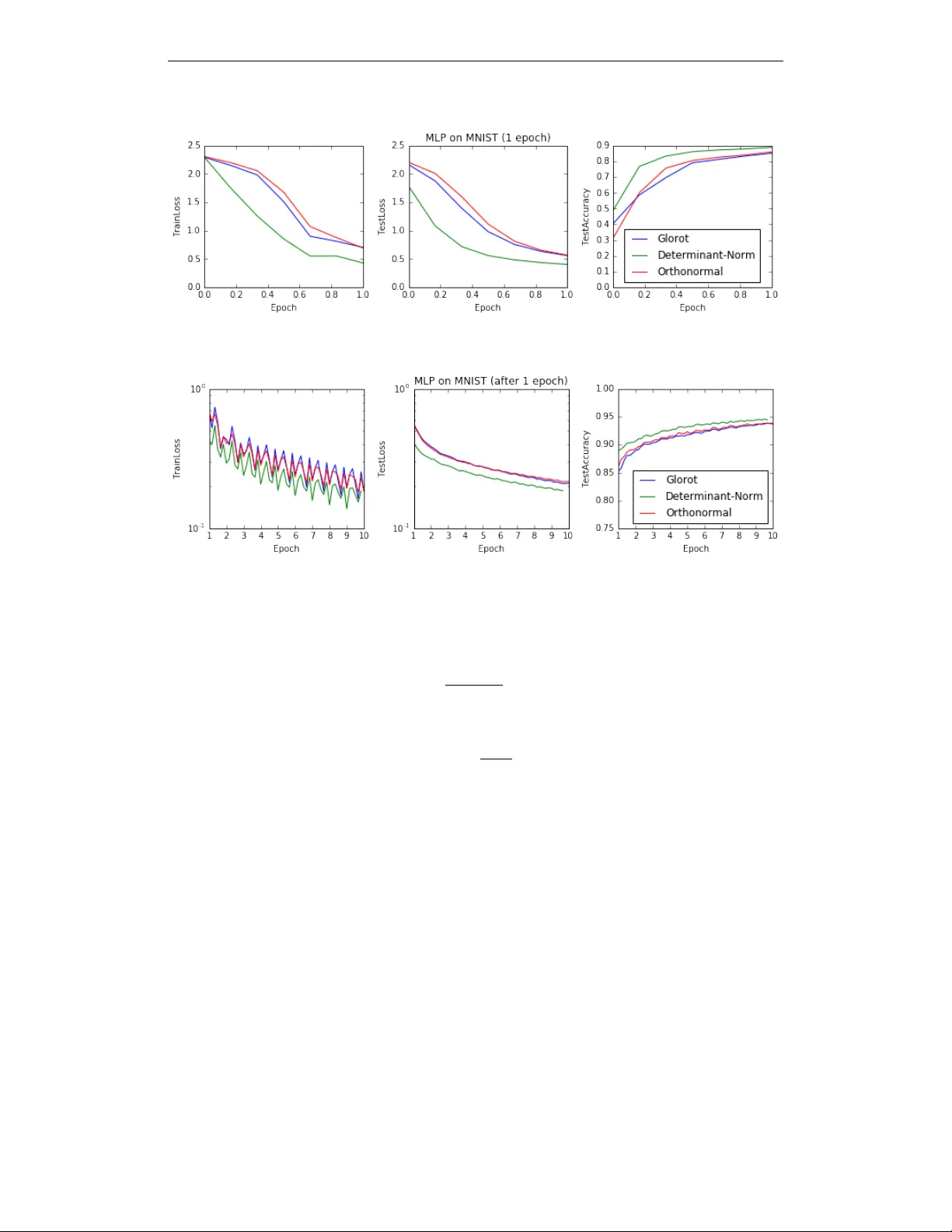
3절에서 두 가지 스케일 정규화 방법을 제안한다. 첫 번째는 ‘determinant normalization’이다. 가중치 행렬 W*에 대해 pseudo‑determinant det(W*) = ∏σ_i 를 구하고, W ← W* / det(W*)^(1/ rank) 로 스케일을 맞춘다(논문에서는 det(W*) 로 나누는 형태로 기술). 이는 특이값들의 기하 평균을 1로 만든다. 실험에서는 100‑100‑100 ReLU MLP를 MNIST에 적용했으며, SGD(배치 100)로 학습한다. 결과는 초기 1 epoch 동안 loss 감소 속도가 Glorot 초기화와 orthonormal 초기화보다 현저히 빠름을 보여준다. 그러나 SVD 연산 비용과 언더플로우 위험이 존재한다.
두 번째는 ‘scale normalization’이다. 배치 내 각 입력 x에 대해 s = ‖Wᵀx‖₂/‖x‖₂ 를 계산하고, 그 평균 E(s) 로 W를 나눈다: W ← W* / E(s). 이는 입력 데이터에 기반한 스케일 보정으로, 계산량이 적고 stochastic하게 동작한다. 실험에서는 이 방법을 첫 번째 epoch에만 적용했을 때(det‑norm과 동일하게) 학습 가속 효과가 나타났으며, 이후 에폭에서는 효과가 사라진다. 이는 스케일 정규화가 초기 그래디언트 흐름을 안정화시키지만, 학습이 진행되면서 모델 자체가 비등거리적인 변환을 필요로 하기 때문이다.
4절에서는 향후 연구 방향을 제시한다. 저자는 현재 실험이 MNIST와 단순 MLP에 국한돼 있어, CIFAR‑10, CNN, RNN 등 복잡한 구조에 대한 검증이 필요하다고 언급한다. 또한, batch‑normalization과의 연관성, 그리고 Adam·RMSProp 같은 최신 옵티마이저와의 상호작용을 탐구할 계획이다. 최종적으로 스케일 정규화가 학습 초기 속도를 높이는 데 유용하다는 실험적 증거를 제시하면서, 등거리성 유지가 딥러닝 최적화 이론에 새로운 통찰을 제공할 수 있음을 주장한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기