영화 줄거리에서 특징 추출 LDA와 신경망 비교 연구
본 논문은 CMU 영화 요약 코퍼스를 대상으로 두 가지 텍스트 특징 추출 방법을 비교한다. 하나는 확률적 토픽 모델인 Latent Dirichlet Allocation(LDA)이고, 다른 하나는 자동 인코더 기반의 문단 벡터(doc2vec)이다. 추출된 특징을 K‑Nearest Neighbors와 t‑SNE로 시각화·평가하고, IMDB 협업 필터링 추천과 비교하여 콘텐츠 기반 추천의 가능성을 검증한다.
저자: Despoina Christou
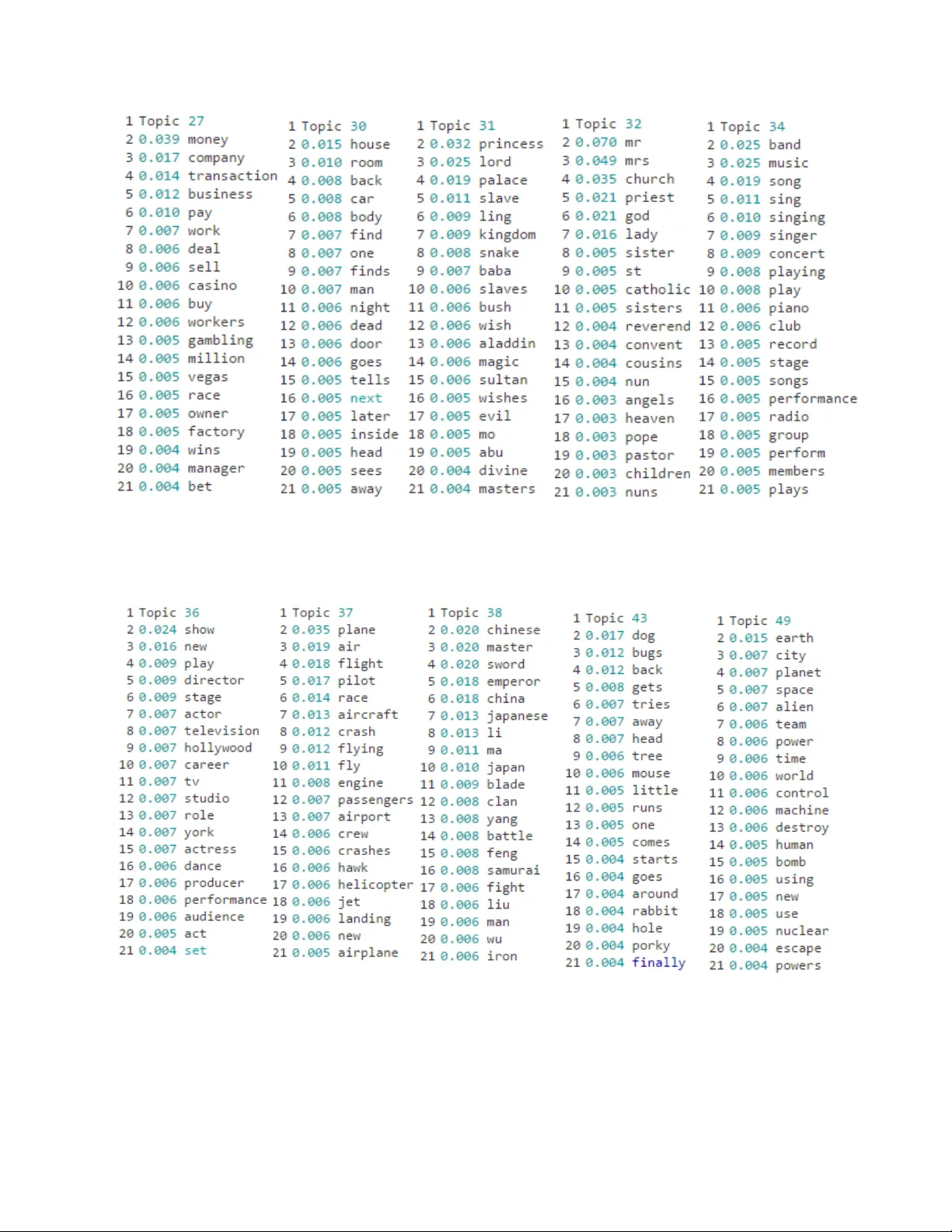
본 논문은 텍스트 기반 영화 추천 시스템을 구현하기 위해 두 가지 주요 특징 추출 기법을 비교·분석한다. 연구 배경으로는 디지털화된 방대한 텍스트 데이터와 이에 대한 자동화된 분석 필요성이 증가함에 따라, 고차원 희소 텍스트를 저차원 의미 공간으로 변환하는 기술이 핵심 과제로 부각된다. 이를 위해 저자는 CMU Movie Summary Corpus(25,203개 영화 요약)를 데이터셋으로 선정하고, 전처리 단계에서 토큰화, 불용어 제거, 어간 추출 등을 수행하였다.
첫 번째 방법은 Latent Dirichlet Allocation(LDA)이다. LDA는 베이즈적 토픽 모델로, 각 문서를 토픽 분포, 각 토픽을 단어 분포로 표현한다. 논문에서는 Gibbs 샘플링을 이용해 50개의 토픽을 학습했으며, 토픽‑문서 행렬을 각 영화의 특징 벡터로 사용한다. LDA의 장점은 학습 속도가 빠르고, 토픽 해석이 직관적이며, 사전 라벨링이 필요 없다는 점이다. 그러나 bag‑of‑words 가정으로 인해 단어 순서와 구문 정보를 놓치고, 토픽 수 선택에 민감하다는 한계가 있다.
두 번째 방법은 신경망 기반 자동 인코더를 활용한 문단 벡터(doc2vec)이다. 여기서는 Paragraph Vector 모델의 두 변형(PV‑DM, PV‑DBOW)을 결합해 300차원 고정 길이 벡터를 학습한다. 자동 인코더는 입력 문장을 재구성하도록 훈련되며, 은닉층이 압축 역할을 수행해 의미적 유사성을 보존한다. 이 접근은 단어 순서와 문맥 정보를 어느 정도 유지하면서 비선형 변환을 통해 복잡한 의미 구조를 포착한다. 다만, 대규모 신경망 학습에 높은 계산 비용과 하이퍼파라미터 튜닝이 필요하고, 과적합 위험이 존재한다.
두 특징 집합을 동일한 K‑Nearest Neighbors(KNN) 프레임워크에 적용해 코사인 유사도로 가장 유사한 영화 10편을 추천한다. 추천 결과를 t‑SNE로 2차원에 투영해 시각화했으며, 군집 형성 정도와 군집 내 거리 분포를 정량적으로 비교하였다. LDA 기반 군집은 토픽 중심이 명확히 구분되어 시각적으로 뚜렷한 영역을 형성했지만, 장르가 혼재되는 경우도 있었다. 자동 인코더 기반 군집은 보다 부드러운 경계와 고차원 의미 공간을 반영해 장르 간 미세 차이까지 포착하는 모습을 보였다.
추천 정확도 평가는 IMDB의 협업 필터링 결과와 교차 검증하였다. LDA와 자동 인코더 모두 상위 5위 내에 IMDB와 동일하거나 유사한 영화를 포함했으며, 특히 자동 인코더는 신규 영화나 평점 데이터가 부족한 경우에도 콘텐츠 기반으로 의미 있는 추천을 제공했다. 이는 협업 필터링이 사용자 행동 데이터에 의존하는 반면, 본 연구의 방법들은 텍스트 자체만으로도 충분한 신호를 제공한다는 점을 시사한다.
논문은 모델 확장 가능성도 논의한다. LDA는 토픽 수를 늘리거나 Dirichlet prior을 조정해 특정 장르에 초점을 맞출 수 있고, 자동 인코더는 사전 훈련된 워드 임베딩을 초기화하거나 Transformer 기반 인코더로 교체해 성능을 향상시킬 여지가 있다. 최종적으로 두 방법은 상호 보완적이며, 하이브리드 시스템을 구축해 토픽 레벨의 전역 구조와 문단 벡터의 미세 의미를 동시에 활용하는 것이 향후 연구 방향으로 제시된다.
요약하면, LDA는 빠르고 해석 가능한 토픽 기반 특징을 제공하고, 자동 인코더는 더 풍부한 의미 정보를 담은 문단 벡터를 제공한다. 두 방법 모두 KNN과 t‑SNE를 통해 효과적인 영화 유사도 측정 및 시각화를 가능하게 하며, IMDB 협업 필터링과 비교했을 때 충분히 경쟁력 있는 콘텐츠 기반 추천을 구현한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기