딥러닝 기반 음성 스푸핑 탐지 시스템
본 논문은 ASVSpoof2015 데이터베이스를 활용해 심층 신경망(MLP)을 특징 추출기와 분류기로 동시에 이용한 스푸핑 탐지 방법을 제안한다. 128개의 DCT 계수를 입력으로 사용하고, 32차원의 병목 특성을 추출한 뒤 SVM‑RBF, GMM, MLP 세 가지 분류기로 평가했으며, 알려진 공격에 대해 0.5% 이하의 EER을 달성하였다.
저자: Alan Godoy, Flavio Sim~oes, Jose Augusto Stuchi
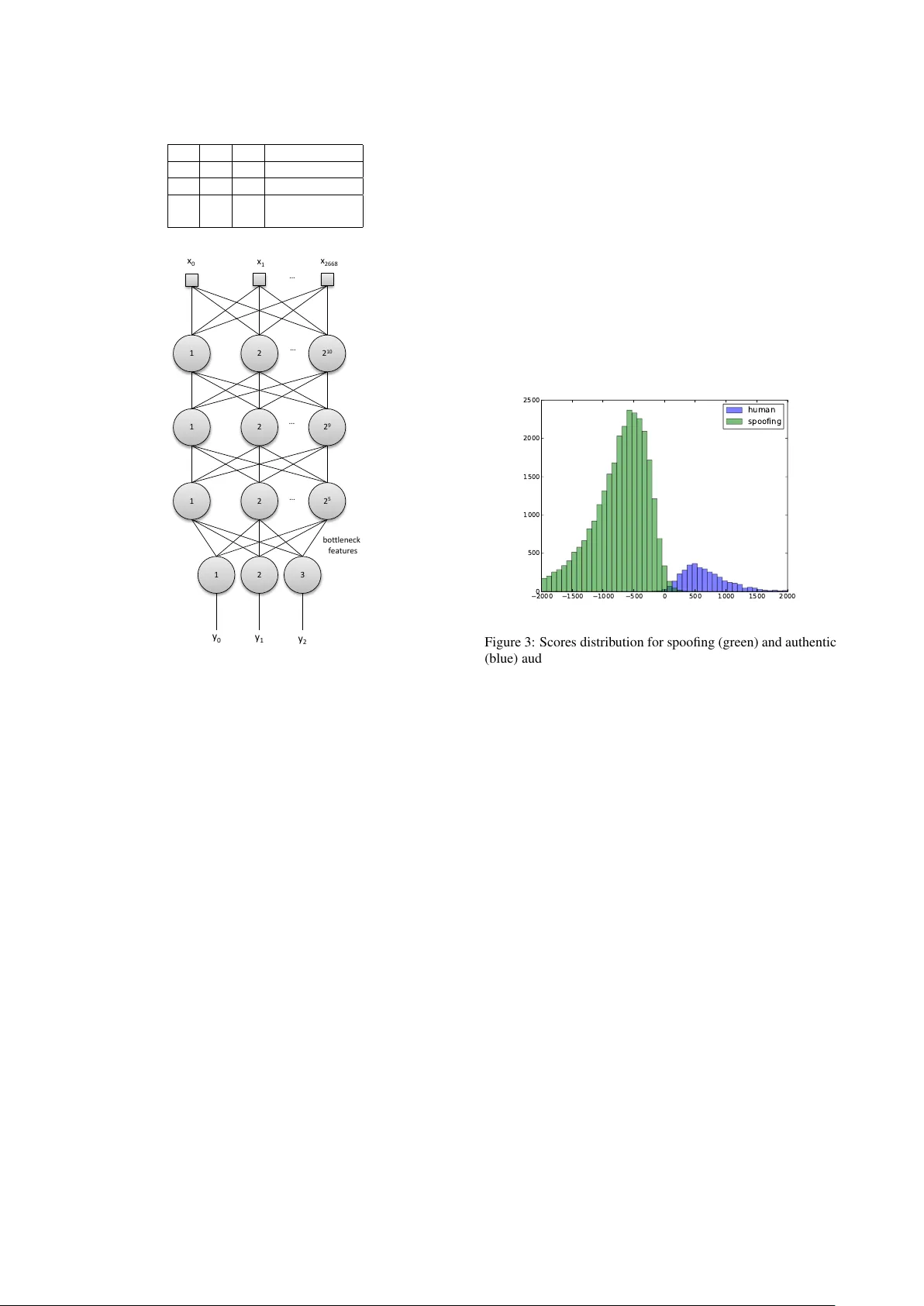
본 논문은 2015년 개최된 Automatic Speaker Verification Spoofing and Countermeasures Challenge(ASVSpoof2015)에서 제공된 표준 스푸핑 데이터베이스를 활용해, 딥러닝 기반 스푸핑 탐지 시스템을 설계하고 평가한다. 연구팀은 멀티레이어 퍼셉트론(MLP) 구조를 중심으로 두 가지 활용 방안을 제시한다. 첫 번째는 MLP를 특징 추출기로 사용해 고차원 입력을 저차원 병목 특성으로 압축하고, 이를 별도의 분류기(SVM‑RBF, GMM)와 결합하는 방식이다. 두 번째는 MLP 자체를 최종 분류기로 활용해 출력층을 유지한 채 스푸핑 여부를 직접 판단한다.
데이터 전처리 단계에서는 20 ms 길이의 비중첩 프레임을 사용하고, ITU G.729B 기반 음성 활동 검출(VAD)으로 비음성 구간을 제거한다. 각 프레임은 주변 10개의 이전·이후 프레임과 함께 2688 차원의 벡터로 구성된다. 입력 특성으로는 MFCC, MGDCC, DFT 등 여러 후보를 실험했지만, 에너지 집중 특성 때문에 DCT 128계수가 가장 우수한 성능을 보였다.
MLP는 1024‑512‑32 구조의 은닉층을 갖고, 각 은닉층은 로지스틱 시그모이드 활성화를 사용한다. 출력층은 3개의 소프트맥스 뉴런으로 구성해 ‘인간 음성’, ‘S1 스푸핑’, ‘그 외 스푸핑’이라는 세 클래스로 라벨링한다. 이는 S1 공격이 단위 선택 기반으로 다른 공격과 구별되는 특성을 반영하기 위함이다. 학습은 확률적 경사 하강법(SGD)과 역전파를 통해 진행되며, 교차 검증을 통해 최적의 하이퍼파라미터를 탐색한다.
특징 추출이 완료된 후, 각 오디오 파일은 프레임별 병목 특성을 평균해 32 차원의 고정 길이 벡터로 변환된다. 이 벡터를 이용해 세 가지 분류기를 실험한다.
1) SVM‑RBF: RBF 커널을 사용하고, C=0.1, γ=10이 최적 파라미터로 선정되었다.
2) GMM: 진짜와 스푸핑 각각에 대해 8개의 가우시안 컴포넌트를 가진 모델을 학습했으며, 로그우도비를 점수로 사용한다.
3) MLP 자체: 출력층을 유지한 채 프레임별 소프트맥스 점수를 계산하고, 상위·하위 15 %와 25 %를 제외한 60 % 평균값을 최종 점수로 채택한다.
평가 결과는 다음과 같다. 알려진 5가지 공격에 대해 SVM‑RBF는 0.41 %의 EER을 기록해 가장 우수했으며, GMM은 0.44 %, MLP는 0.46 %의 성능을 보였다. 미지의 공격에 대해서는 MLP가 6.53 %의 EER로 약간 더 나은 결과를 보였지만, 전체 평균 EER은 6.5 % 수준에 머물렀다. 특히 S8(텐서 기반 변환)과 S10(MaryTTS) 공격에서는 각각 26.8 %와 31.7 %라는 높은 오류율을 보이며, 모델이 학습 데이터에 존재하던 저주파 노이즈 불연속성(0‑100 Hz)을 주요 특징으로 학습했기 때문이라는 가설을 제시한다. 이러한 편향은 새로운 공격에 대한 일반화 능력을 저해한다는 점을 강조한다.
결론적으로, 딥러닝 기반 병목 특성 추출은 스푸핑 탐지에 효과적이며, SVM‑RBF와 결합했을 때 알려진 공격에 대해 0.5 % 이하의 EER을 달성한다. 그러나 데이터 편향과 일반화 문제를 해결하기 위해서는 보다 다양하고 대규모의 스푸핑 샘플을 포함한 학습 데이터 구축이 필요하다. 또한, 위상 스펙트럼을 강조하는 새로운 파라미터화 방식이나, 컨볼루션 신경망(CNN) 등 다른 딥러닝 아키텍처를 도입하면 성능 향상이 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기