연속 정책을 위한 호환 가치 기울기 학습 GProp
GProp은 연속 행동 공간을 갖는 강화학습에서 정책과 가치 함수를 동시에 학습하도록 설계된 알고리즘이다. 핵심은 TD 기반으로 가치 함수의 기울기를 직접 추정하는 “gradient perturbation trick”와, 가치, 기울기, 정책을 각각 담당하는 세 개의 신경망으로 구성된 Deviator‑Actor‑Critic(DAC) 모델이다. 논문은 비선형 정책에 대한 호환 함수 근사 조건을 만족함을 이론적으로 증명하고, 비파라메트릭 회귀 데이…
저자: David Balduzzi, Muhammad Ghifary
본 논문은 연속 행동 공간을 갖는 강화학습 문제에서 정책과 가치 함수를 동시에 학습하면서도, 정책 그라디언트 추정에 필요한 “호환(compatible) 함수 근사” 조건을 만족하는 새로운 알고리즘 GProp을 제안한다. 기존의 정책‑그라디언트 방법은 가치 함수 Q(s,a)를 근사하지만, 그 기울기 ∇ₐQ(s,a)를 직접 추정하지 못한다. 또한, 비선형 신경망 정책을 사용할 경우, 가치 함수 근사에 사용되는 특징 φ(s,a)=∇θμθ(s)·(a−μθ(s))가 정책 파라미터에 의존해 가중치 업데이트가 역전파로 수행되기 어려운 문제가 있었다. 이를 해결하기 위해 두 가지 핵심 기여를 제시한다.
첫 번째는 “gradient perturbation trick”이다. 함수 f(x)를 Gaussian 잡음 ε∼N(0,σ²I)로 교란한 입력 f(μ+ε)의 기대값을 이용해 ∇f(μ)를 무편향 추정한다(Lemma 3). σ²를 충분히 작게 하면 f는 국소적으로 선형으로 근사되므로, 최소제곱 문제를 풀어 w≈∇f(μ)를 얻는다. 이 아이디어를 TD‑learning과 결합하면, 시간 차 오류 δₜ를 이용해 가치 함수 Q와 그 기울기 G를 동시에 업데이트할 수 있다.
두 번째는 Deviator‑Actor‑Critic(DAC) 모델이다. DAC은 세 개의 신경망으로 구성된다. ① Critic 네트워크 V(s)는 현재 정책에 대한 상태 가치 추정, ② Deviator 네트워크 G(s,a)는 ∇ₐQ(s,a) 즉, 가치 함수의 행동에 대한 기울기를 직접 학습, ③ Actor 네트워크 μθ(s)는 결정적 정책을 출력한다. 각 네트워크는 독립적인 파라미터 집합(Θ, W, V)을 가지고, 서로의 출력에만 의존한다. Algorithm 1(GProp)에서는 (i) TD‑error을 이용해 V와 G를 업데이트하고, (ii) ∇θμθ(s)·G(s,μθ(s))를 사용해 정책 파라미터 θ를 상승시킨다.
이 구조가 호환 함수 근사 조건을 만족함을 Theorem 6이 증명한다. 조건 C1은 Q의 기울기 추정이 정확해야 함을 의미하고, C2는 ∇ₐQ(s,a)와 ∇θμθ(s) 사이의 선형 관계를 요구한다. DAC에서는 G가 직접 ∇ₐQ를 근사하므로 C1을 만족하고, G와 ∇θμθ(s)의 곱이 정책 그라디언트에 바로 사용되므로 C2도 만족한다. 특히, 네트워크가 선형 혹은 ReLU 유닛으로 구성될 경우, 각 유닛을 독립적인 “소액션”으로 해석해 가중치 업데이트를 표준 역전파로 수행할 수 있다.
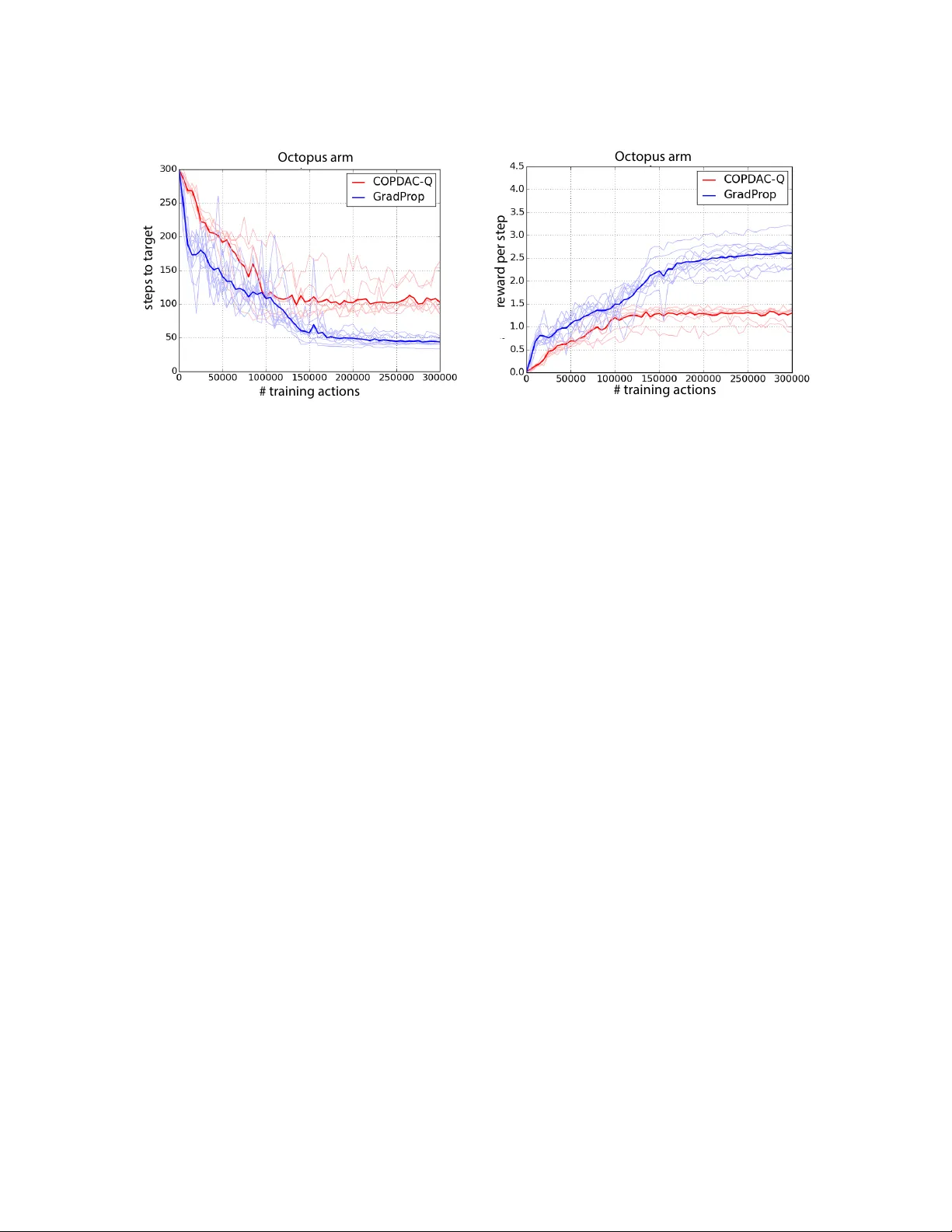
실험에서는 두 가지 도메인을 평가한다. 첫 번째는 SARCOS와 Barrett 로봇 데이터셋을 활용한 연속 컨텍스트 밴드잇 문제이다. 원래 회귀 데이터의 입력을 상태, 출력(관절 토크)을 행동으로 변환하고, 보상은 행동과 정답 라벨 사이의 거리(음수)로 정의한다. 이 설정에서는 정확한 기울기 추정이 성능에 결정적이며, GProp은 완전 감독 학습 모델과 비교해 거의 동일한 평균 제곱 오차를 달성한다. 두 번째는 Octopus Arm 벤치마크이다. 이 과제는 고차원 연속 제어와 장기 의존성을 요구하는 복잡한 환경으로, 기존 방법들은 수렴이 불안정하거나 성능이 제한적이었다. GProp은 최적 정책에 가까운 보상을 지속적으로 얻으며, 현재 보고된 최고 성능을 기록한다.
또한, 기존 연구와의 관계를 상세히 논의한다. REINFORCE와 Deep Q‑Learning은 각각 정책 그라디언트와 Q‑함수 근사에 초점을 맞추었지만, 연속 행동에 대한 직접적인 기울기 추정은 제공하지 않는다. COPDAC‑Q는 결정적 정책 그라디언트를 사용했지만, 가치 기울기와 정책 파라미터가 얽혀 있어 호환성을 보장하지 못한다. GProp은 이러한 한계를 극복하고, 비선형 신경망 정책에서도 이론적 보장을 제공한다.
결론적으로, GProp은 (1) 가치 함수와 그 기울기를 동시에 학습하는 새로운 TD‑기반 방법, (2) 세 개의 독립적인 네트워크로 구성된 DAC 모델, (3) 비선형 정책에 대한 호환 함수 근사 조건을 만족하는 이론적 증명, (4) 실제 복잡한 연속 제어 과제에서의 뛰어난 성능을 제공한다는 점에서 강화학습 분야에 중요한 기여를 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기