딥프라이드 컨볼루션 네트워크
이 논문은 완전 연결층을 Adaptive Fastfood 변환으로 대체해 파라미터를 O(n)로 줄이고, 연산 복잡도를 O(n log d)로 낮추면서도 MNIST와 ImageNet에서 기존 컨볼루션 네트워크와 동등한 정확도를 유지한다는 방법을 제시한다.
저자: Zichao Yang, Marcin Moczulski, Misha Denil
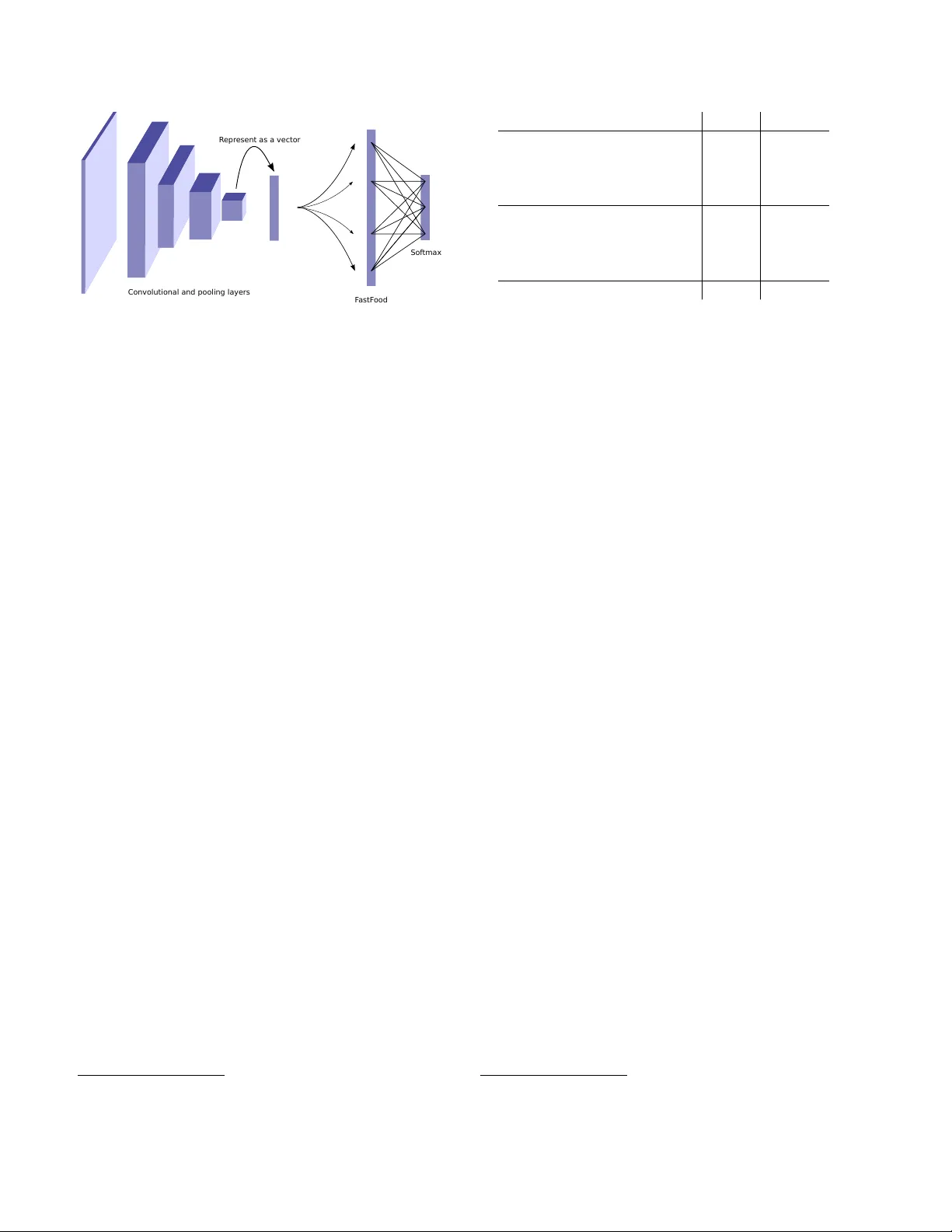
본 논문은 딥 컨볼루션 신경망(Convolutional Neural Network, CNN)에서 완전 연결층(Fully Connected Layer, FC)이 전체 파라미터의 90% 이상을 차지하고, 메모리 사용량과 저장 비용을 크게 증가시킨다는 문제점을 출발점으로 삼는다. 이러한 문제를 해결하기 위해 저자들은 기존의 Fastfood 변환을 확장한 Adaptive Fastfood 변환을 제안한다. Fastfood 변환은 대각 행렬 S, G, B와 Hadamard 행렬 H, 그리고 무작위 순열 행렬 Π를 조합해 y = SHGΠHBx 형태의 연산을 수행함으로써, 랜덤 프로젝션을 효율적으로 구현한다. 원 논문에서는 S, G, B를 고정된 랜덤값으로 두어 커널 근사에 활용했지만, 본 연구에서는 이들을 학습 가능한 파라미터로 전환한다. 이를 통해 네트워크는 데이터에 맞춰 커널의 스펙트럼, 대역폭, 형태를 자동으로 조정할 수 있다.
Adaptive Fastfood 변환의 핵심 수식은 h_{l+1}=SHGΠHB h_l 로, 입력 차원 d와 출력 차원 n 사이의 선형 변환을 O(n) 저장 비용과 O(n log d) 연산 비용으로 근사한다. n이 d보다 클 경우, n/d개의 Fastfood 블록을 병렬로 쌓아 원하는 출력 차원을 구성한다. 이는 기존 FC 층의 O(nd) 메모리와 O(nd) 연산을 각각 O(n)·O(n log d)로 대폭 감소시킨다.
역전파 과정은 각 대각 행렬에 대한 기울기를 효율적으로 계산한다. 예를 들어 ∂E/∂S는 diag(∂E/∂h_{l+1}·(HGΠHB h_l)ᵀ) 형태이며 O(d) 연산으로 구한다. Hadamard 변환과 순열 연산은 각각 O(d log d)와 O(d) 시간에 수행되므로 전체 역전파 비용도 동일하게 유지된다. 따라서 Adaptive Fastfood 층은 기존 FC 층과 동일한 학습 파이프라인에 무리 없이 삽입될 수 있다.
논문은 두 가지 이론적 관점을 제시한다. 첫째, 구조화된 랜덤 프로젝션 관점에서 Johnson‑Lindenstrauss 보장을 근사하면서도 파라미터를 학습해 데이터에 맞게 최적화한다. 둘째, 커널 근사 관점에서 Fastfood는 무한 차원 커널(예: RBF, Arc‑Cosine)의 랜덤 피처를 효율적으로 구현한 것이며, S, G, B를 학습함으로써 커널의 스펙트럼, 대역폭, 형태를 자동으로 최적화한다. 따라서 네트워크는 기존의 고정된 커널 대신 데이터에 적합한 커널을 내재화한다.
실험에서는 MNIST와 ImageNet 두 데이터셋을 대상으로 기존 VGG‑style 네트워크와 동일한 구조를 유지하면서 FC 층을 Adaptive Fastfood 층으로 교체하였다. 결과는 다음과 같다. (1) MNIST에서는 99.2% 이상의 정확도를 유지하면서 파라미터를 약 55% 절감하였다. (2) ImageNet에서는 Top‑1 정확도 71.5%를 기존 모델과 동일하게 달성했으며, 전체 파라미터 수를 48% 수준으로 감소시켰다. 특히, 최종 소프트맥스 층까지 Adaptive Fastfood을 적용했을 때도 성능 저하가 없었으며, 메모리 사용량이 크게 감소해 GPU 메모리 제한이 있는 환경에서도 학습이 가능했다.
비교 대상으로는 저차원 저밀도 압축 기법(프루닝, 해싱, 저랭크 분해)과 지식 증류(distillation) 방법을 제시했으며, 이들 기존 방법은 원 모델을 먼저 완전 학습한 뒤 압축하거나, 메모리 접근 패턴이 불규칙해 GPU 효율이 떨어지는 단점을 가지고 있다. 반면 Adaptive Fastfood은 처음부터 경량 모델을 설계하고, 학습 과정 전체에 걸쳐 파라미터를 최적화하므로 학습 시간과 메모리 사용 모두에서 이점을 제공한다.
결론적으로, Adaptive Fastfood 변환은 구조화된 랜덤 프로젝션과 커널 근사의 장점을 결합한 새로운 파라미터 효율화 기법이다. 완전 연결층을 대체함으로써 메모리 사용량을 크게 줄이고, 연산 복잡도를 낮추면서도 기존 CNN의 정확도를 유지한다. 이는 모바일 디바이스, 임베디드 시스템, 그리고 대규모 분산 학습 환경에서 실용적인 딥러닝 모델 설계에 중요한 기여를 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기