중첩 샘플링 통계적 불확실성 분석
중첩 샘플링이 베이즈 증거를 계산하는 데 널리 쓰이지만, 증거값의 통계적 오차 추정이 명확하지 않다. 본 논문은 Skilling(2004, 2006)의 불확실성 추정식을 검토하고, 샘플링 과정의 확률적 특성을 기반으로 새로운 오차 추정기를 제안한다. 두 추정법 모두 시뮬레이션 실험에서 정확성을 보였으며, 추가 계산 비용 없이 오차를 평가할 수 있다.
저자: Charles R. Keeton
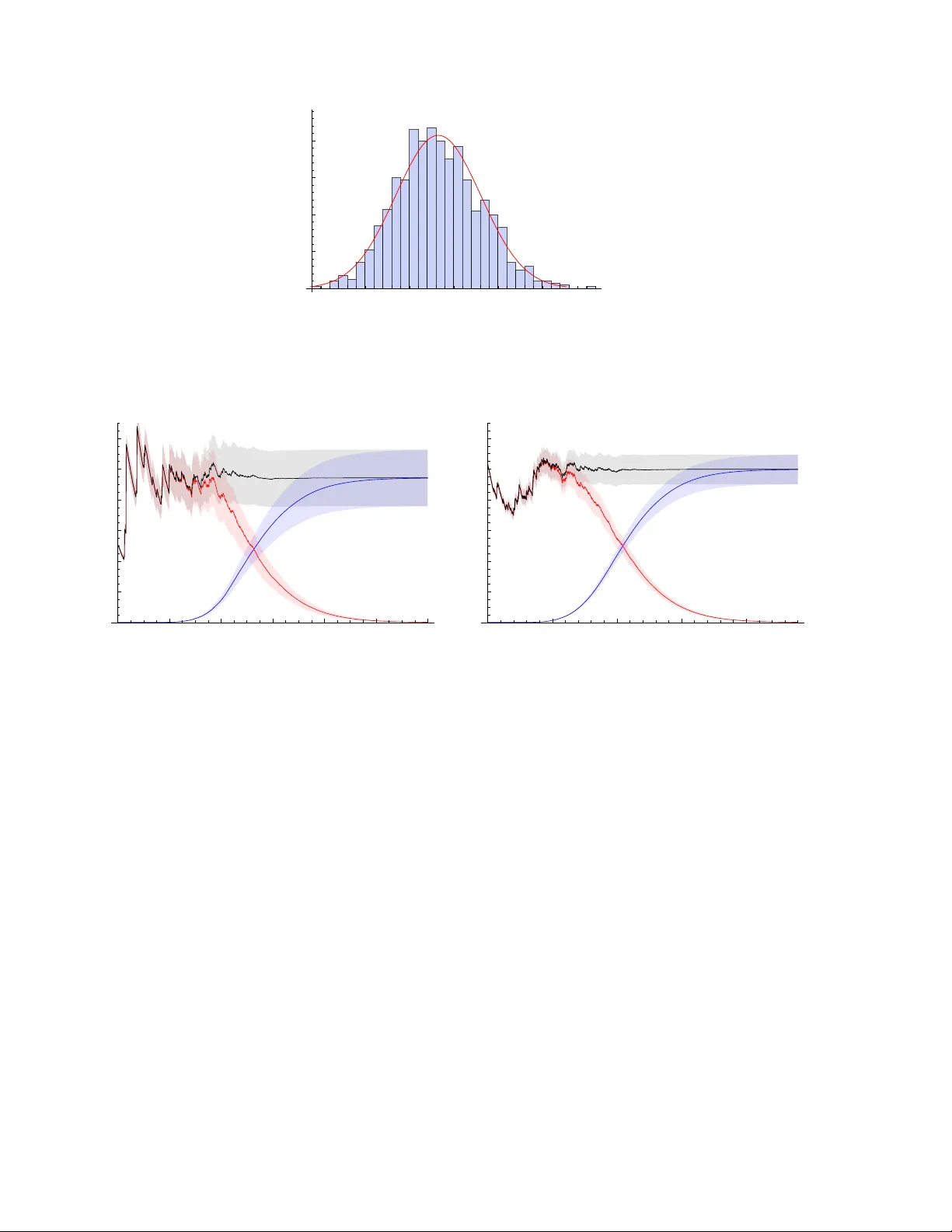
본 논문은 베이즈 모델 선택에서 핵심적인 역할을 하는 베이즈 증거(또는 주변 가능도) 계산을 위한 중첩 샘플링(Nested Sampling, 이하 NS)의 통계적 불확실성을 체계적으로 분석한다. NS는 2004년 Skilling이 제안한 알고리즘으로, 사전 확률 공간을 ‘우도 순서’에 따라 점진적으로 축소하면서, 각 단계에서 살아있는 점(live point)들의 우도 평균을 이용해 증거를 근사한다. 이 과정에서 사전 부피 X는 지수적으로 감소하고, 각 감소 비율 t_i는 Beta(Nlive,1) 분포를 따른다. 따라서 증거 Z는 로그‑우도와 로그‑부피의 곱을 누적한 형태로 표현된다.
하지만 실제 계산에서는 두 가지 주요 원천의 불확실성이 존재한다. 첫 번째는 t_i의 랜덤성으로 인한 부피 추정 오차이며, 두 번째는 같은 부피 구간 내에서 우도값 L_i가 변동하는 통계적 오차이다. 기존 문헌에서는 주로 첫 번째 요소만을 고려해 Skilling이 제시한 Var
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기