수백 개 캠페인 동시 최적화: 개인 정보 없이 광고 응답 예측
본 논문은 사용자 개인 정보를 수집하지 않고도 수백 개의 광고 캠페인에 대해 개별 클릭 확률을 예측하는 방법을 제시한다. 일반화 선형 모델(GLM) 기반의 로지스틱 회귀를 각 캠페인별 이진 모델로 구축하고, 긍정·부정 샘플링, ex‑post와 ex‑ante 보정, ROC 기반 캘리브레이션 절차를 통해 모델 정확도를 확보한다. 또한 Intel Phi와 같은 전용 하드웨어를 활용해 실시간 입찰 환경에서 초당 수십만 건 이상의 스코어링 처리량을 달성…
저자: Paolo DAlberto
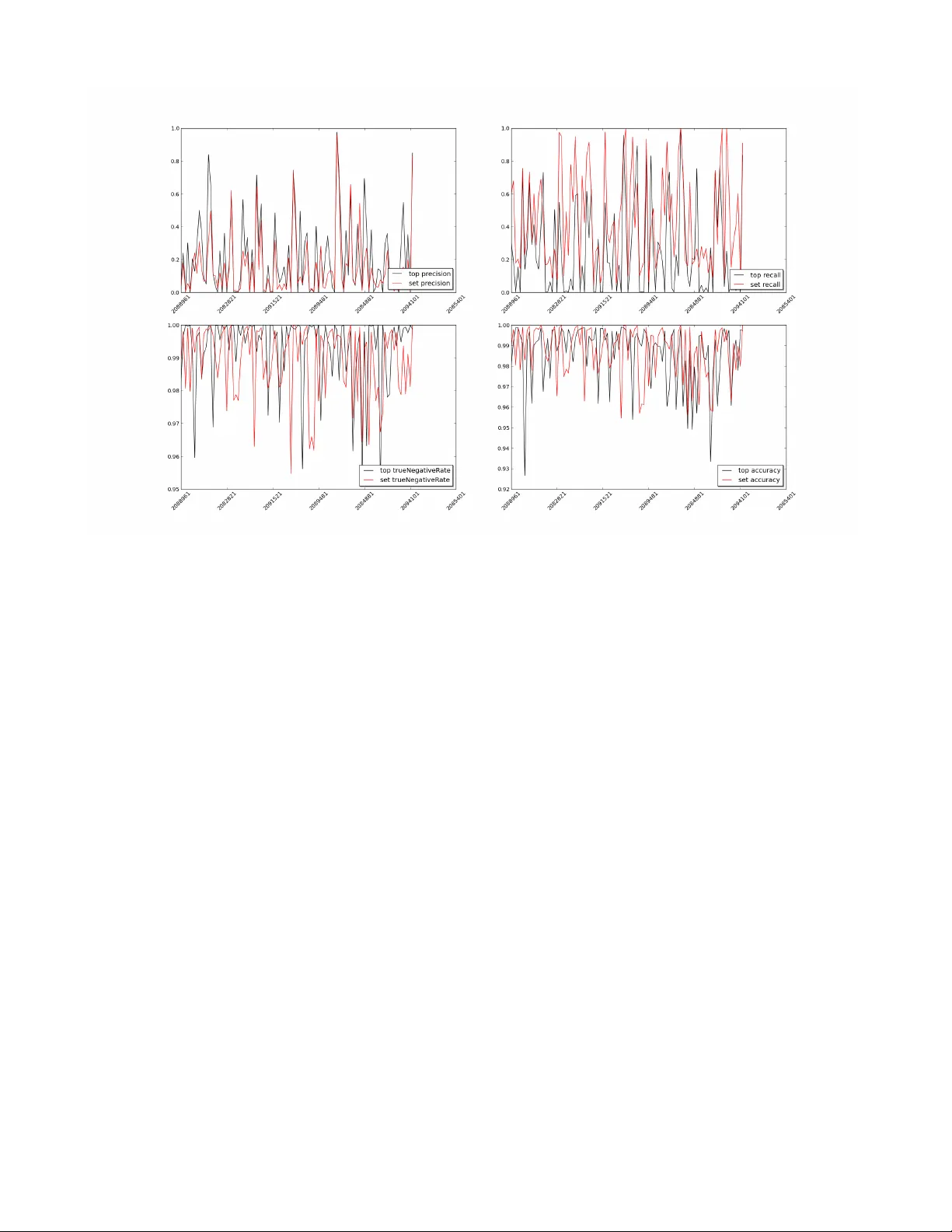
본 논문은 디지털 광고 생태계에서 사용자 개인 정보를 활용하지 않고도 수백 개의 광고 캠페인에 대해 개별 클릭 확률을 예측하고, 실시간 입찰 시스템에 적용할 수 있는 방법론을 제시한다. 서론에서는 현재 온라인 광고가 사용자 프로파일링에 크게 의존하고 있으며, 쿠키 차단·프라이버시 규제로 인해 이러한 접근이 제한되고 있음을 지적한다. 이에 저자는 “집합적·익명적 응답”을 기반으로 한 캠페인 최적화 모델을 설계한다.
문제 정의에서는 각 인상 x에 대해 캠페인 Cₖ의 클릭 확률 Pₖ(x)를 추정하고, 이를 바탕으로 입찰가를 결정하는 과정을 수식화한다. 클릭은 희소 이벤트이므로, 베르누이/이항 분포를 가정하고, 확률 pₖ를 피처 x와 연결하는 함수 g(x) = πₖ를 찾는 것이 핵심이다.
방법론 파트에서는 일반화 선형 모델(GLM) 중 로지스틱 회귀를 선택한다. 로짓 변환(log π/(1‑π))을 통해 확률을 선형 결합 형태 η = β₀ + ∑ⱼ xⱼβⱼ 로 표현하고, 최대우도 추정(MLE)으로 파라미터 β를 학습한다. 대규모 데이터에서 반복적인 QR 분해가 비용이 크므로, 가중치 변화에 따라 Q 행렬을 재사용하는 최적화 기법을 도입한다.
데이터 샘플링 전략은 긍정 사례(클릭)를 그대로 사용하고, 부정 사례는 동일 기간 내 다른 캠페인의 클릭을 활용한다. 이는 부정 샘플이 실제 광고 환경을 반영하도록 하면서도, 부정 샘플 수를 클릭 수와 동일하게 맞춰 모델 학습의 불균형을 완화한다. 또한, 학습‑캘리브레이션 데이터를 3:1 비율로 무작위 혹은 시간 구간에 따라 분리하고, 캘리브레이션 단계에서 ROC 곡선과 AUC를 이용해 모델 성능을 정량화한다.
ex‑post와 ex‑ante 보정에 대한 논의에서는, 로짓 모델의 절편 β₀만이 두 데이터 분포 차이를 반영한다는 수학적 특성을 활용한다. 이를 통해 훈련 시점(과거 클릭)과 전체 잠재 인상(미래 입찰) 사이의 스케일 차이를 보정하고, 다중 캠페인 간 확률 비교가 가능하도록 만든다.
피처 탐색 섹션에서는 광고 교환, 시간대, 요일, 광고 포맷·크기, 도메인 등 6가지 카테고리를 정의하고, 각 카테고리별로 모델을 구축·비교한다. 이를 통해 어떤 피처가 클릭 예측에 가장 큰 설명력을 갖는지 정량적으로 평가한다.
실시간 스코어링 성능 평가에서는 Intel Phi와 같은 벡터 연산 가속기를 사용해 모델 파라미터와 피처를 메모리‑레지스터에 사전 로드하고, SIMD 명령으로 로짓 계산을 병렬화한다. 실험 결과, 초당 300 K ~ 500 K 건의 스코어링을 달성했으며, 이는 대형 광고 교환에서 요구되는 수십만 건/초 수준을 충분히 충족한다.
결과 섹션에서는 전체 200개 캠페인에 대해 평균 precision = 0.12, recall = 0.08, AUC ≈ 0.71을 기록했으며, 단일 캠페인 모델 대비 다중 모델 접근법이 데이터 희소성 문제를 완화하고 전체 시스템 효율성을 높임을 확인한다.
마지막으로 결론에서는 개인 정보를 수집하지 못하는 환경에서도 높은 예측 정확도와 실시간 처리량을 제공할 수 있음을 강조하고, 향후 연구 방향으로 피처 자동 선택, 딥러닝 기반 비선형 모델, 그리고 클라우드‑네이티브 배포 전략을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기