최소 감독으로 사전 구축: CCA 기반 명명 엔터티 인식 사전 자동 생성
본 논문은 대규모 비지도 텍스트와 소수의 시드 예시만을 이용해 질병·바이러스 명명 엔터티 사전을 자동으로 구축하는 방법을 제안한다. 후보 구문을 두 뷰(스펠링·컨텍스트)로 나누어 CCA로 저차원 임베딩을 만든 뒤, 소수의 라벨을 사용해 이진 SVM으로 정제한다. 기존 공동학습(co‑training) 대비 F1 점수가 각각 16.5%·11.3% 향상되었으며, 사전 매치를 CRF 태거에 특징으로 추가했을 때도 단어 임베딩보다 우수한 성능을 보였다.
저자: Arvind Neelakantan, Michael Collins
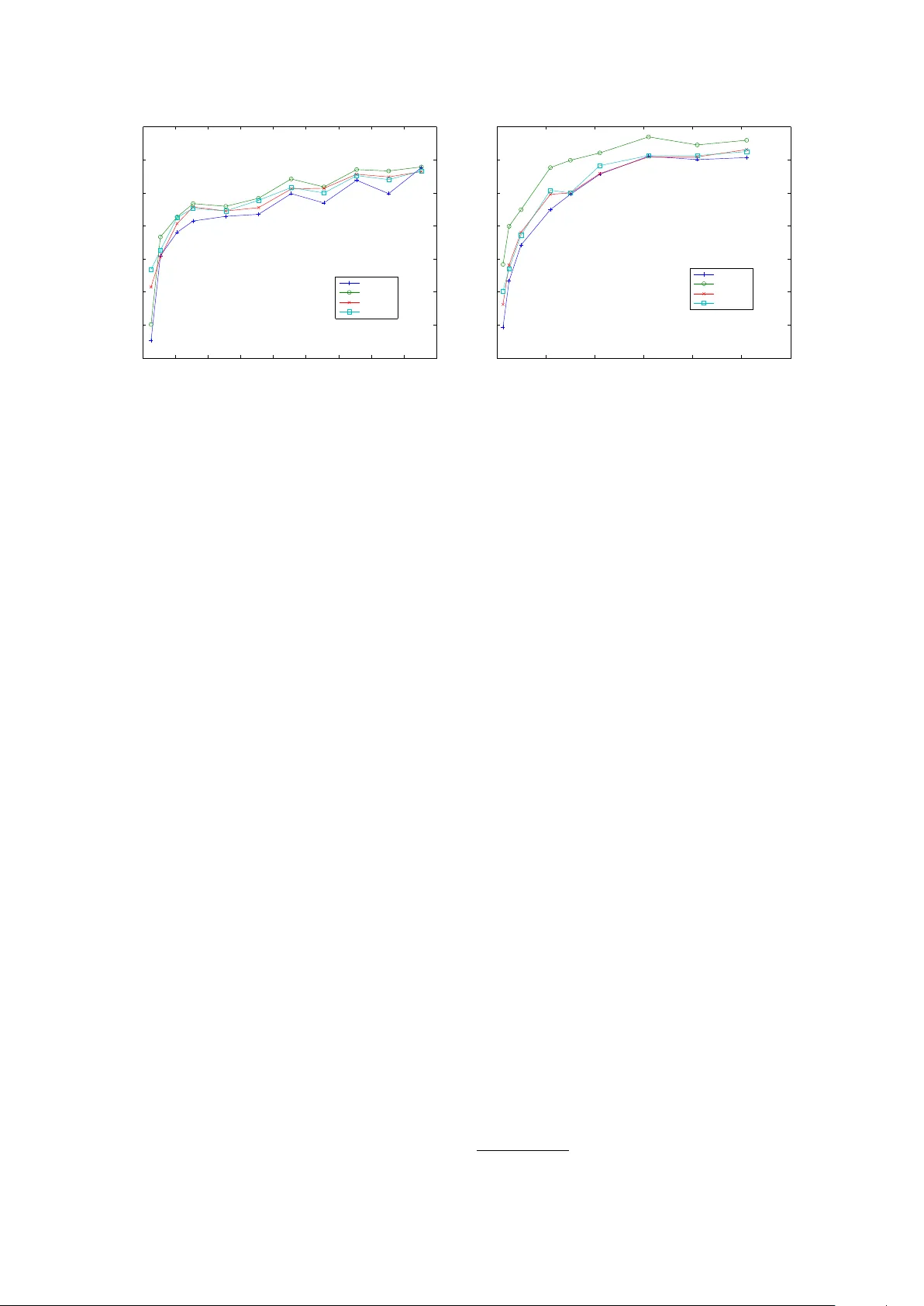
본 논문은 명명 엔터티 인식(NER) 시스템에서 사전(dictionary)의 활용이 성능을 크게 좌우한다는 점에 착안하여, 사전 구축에 필요한 인간 작업량을 최소화하는 자동화 방법을 제안한다. 연구자는 두 단계로 구성된 파이프라인을 설계하였다. 첫 번째 단계에서는 대규모 비지도 텍스트인 BioMed Central 코퍼스(110 369편)를 대상으로 간단한 정규표현식과 명사구 추출 규칙을 적용해 ‘바이러스’와 ‘질병’에 대한 후보 구문 리스트를 만든다. 이때 “the … virus”와 같은 패턴을 이용해 바이러스 후보를, “… disease”와 유사한 여러 패턴(“diseases like …”, “diagnosed with …” 등)을 이용해 질병 후보를 추출하였다. 결과적으로 높은 재현율을 보장하지만 잡음이 많이 포함된 저정밀 리스트가 생성된다.
두 번째 단계에서는 이러한 후보 구문을 정제하기 위해 두 개의 자연스러운 뷰를 정의한다. ‘스펠링(view‑1)’은 후보 구문 자체와 대문자 여부와 같은 이진 특징을 포함하고, ‘컨텍스트(view‑2)’는 후보 구문 좌우 각각 3개의 주변 단어와 그 위치 정보를 결합한 고차원 특징을 만든다. 이 두 뷰에 대해 Canonical Correlation Analysis(CCA)를 적용하면, 각각의 뷰를 k‑차원(보통 수십 차원) 실수 벡터로 투영하는 행렬 Φ₁, Φ₂를 학습할 수 있다. CCA는 두 뷰 사이의 상관을 최대화하므로, 잡음이 많은 원시 특징을 보다 의미 있는 저차원 임베딩으로 압축한다.
학습된 스펠링 뷰 임베딩(Φ₁ᵀ·x)은 후보 구문의 고유 표현으로 사용되며, 소수의 라벨(바이러스 10개, 질병 18개)만을 제공한 이진 SVM에 입력된다. SVM은 선형 커널을 사용해 빠르게 학습되며, 각 후보 구문이 실제 엔터티인지 아닌지를 예측한다. 이 과정에서 라벨이 적음에도 불구하고 CCA가 제공하는 풍부한 특징 덕분에 높은 정확도를 달성한다.
실험에서는 두 가지 평가 방식을 채택하였다. 첫 번째는 사전을 직접 활용한 사전 기반 태거(dictionary‑based tagger)로, CCA‑SVM으로 만든 사전이 기존 공동학습(DL‑CoTrain) 기반 사전보다 각각 바이러스와 질병 NER에서 F1 점수가 16.5%와 11.3% 더 높았다. 두 번째는 사전 매치를 CRF 기반 시퀀스 태거의 특징으로 추가하는 방식이다. 여기서도 CCA 임베딩을 특징으로 사용한 경우가 단어 임베딩(Word2Vec, CW 등)만을 사용한 경우보다 명확히 우수한 성능을 보였으며, 특히 다단어 엔터티를 효과적으로 포착한다는 장점이 강조되었다.
관련 연구와의 차별점은 다음과 같다. 기존 공동학습 기반 방법은 두 뷰가 독립적이라는 강한 가정을 두고, 여러 휴리스틱 파라미터(m, precision threshold)를 튜닝해야 하는 복잡성이 있었다. 반면 CCA는 독립성 가정 없이 선형 상관을 최대화하므로 파라미터 설정이 간단하고, 이론적 보장(Kakade & Foster 2007)도 존재한다. 또한, 기존 연구가 전체 어휘에 대한 단어 임베딩을 학습한 데 비해, 본 논문은 후보 구문(다단어 엔터티) 자체에 초점을 맞춰 임베딩을 학습함으로써, 사전 구축과 시퀀스 태깅 양쪽에서 실질적인 이득을 얻었다.
결론적으로, 이 접근법은 (1) 대규모 비지도 코퍼스를 활용한 고재현율 후보 추출, (2) CCA를 통한 두 뷰 기반 저차원 임베딩 생성, (3) 소수의 시드 라벨만으로 충분히 학습 가능한 이진 SVM 분류기, (4) 사전 매치를 CRF 태거에 특징으로 활용해 성능을 향상시키는 네 단계의 파이프라인을 제시한다. 특히 바이오메디컬 분야처럼 용어가 급변하고 약어·동형어가 빈번한 도메인에서, 전문가가 직접 사전을 구축하는 비용을 크게 절감하면서도 수동 사전과 동등하거나 더 나은 품질의 사전을 자동으로 생성할 수 있다는 실용적 가치를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기