트위터 팔로워를 끌어들이는 능동 학습
본 논문은 트위터에서 팔로워를 자연스럽게 확보하기 위한 행동을 온라인 컨텍스추얼 밴딧 모델로 학습한다. 60개의 에이전트를 1개월간 운영해 리트윗을 행동으로 삼고, 팔로워 수 변화와 좋아요·리트윗 수 등을 보상으로 설계하였다. 실험 결과, 단순 무작위 전략보다 경사 기반 학습(Gradient Estimator)이 평균 10% 정도 더 많은 팔로워를 얻었으며, 데이터 집합을 에이전트 간에 합치는 것이 오히려 예측 정확도를 떨어뜨림을 확인했다. 또…
저자: Nir Levine, Timothy A. Mann, Shie Mannor
본 논문은 트위터에서 팔로워를 자연스럽게 확보하기 위한 행동을 온라인 컨텍스추얼 밴딧 모델로 학습하는 방법을 제안하고, 실제 60개의 에이전트를 1개월 동안 운영한 실험 결과를 보고한다. 연구 배경으로는 기존 소셜 네트워크 연구가 주로 수동적으로 수집된 데이터에 대한 분석에 머물렀으며, 실제 행동을 제어하고 그 결과를 학습에 반영하는 능동 학습 연구가 부족하다는 점을 들었다. 특히, 대량 팔로우와 같은 봇 행위는 커뮤니티에서 비정상적으로 인식되므로, 에이전트가 “정상적인” 행동(리트윗)만을 수행하도록 설계하였다.
문제 정의는 컨텍스추얼 밴딧으로, 매 라운드마다 에이전트는 트위터 API를 통해 “baseball” 키워드가 포함된 최신 트윗 집합 Aₜ를 받아온다. 각 트윗은 87개의 특징(텍스트 메타데이터, 사용자 프로필, 시간 정보 등)으로 표현된 벡터 xₜ,ₐ가 할당된다. 행동은 이 집합에서 하나를 선택해 리트윗하는 것이며, 보상은 다음 식으로 정의된다: rₜ,ₐ = α₀·Δa,t + α₁·Δu,t + α₂·fₜ + α₃·wₜ, 여기서 Δa,t는 에이전트 자신의 팔로워 수 변화, Δu,t는 원 게시자의 팔로워 변화, fₜ는 좋아요 수, wₜ는 해당 트윗의 리트윗 수이다. α₀=100, α₁=α₂=10, α₃=1 로 설정해 에이전트 자신의 팔로워 증가에 가장 큰 가중치를 부여하였다.
에이전트는 ε‑greedy 탐색 전략을 사용했으며, ε=0.05 로 설정해 5% 확률로 무작위 행동을 선택하고 나머지는 현재 모델이 예측한 보상이 가장 높은 트윗을 선택한다. 실험에 투입된 60개의 에이전트는 세 그룹으로 나뉘었다.
1) Uniform Random(UR) 그룹은 보상 학습 없이 무작위로 리트윗을 선택한다. 이는 베이스라인 역할을 한다.
2) Gradient Estimator(GE) 그룹은 선형 모델을 온라인 경사 하강법(학습률 η=0.1)으로 지속 업데이트한다. 추가로 어드바이저가 제공하는 보조 보상(β 가중치)와 8시간마다 평균화된 가설을 결합해 노이즈를 감소시켰다.
3) Batch Estimator(BE) 그룹은 매 라운드마다 OLS를 사용해 전체 데이터를 재학습한다. 어드바이저는 사용하지 않는다.
실험은 2014년 5월 9일부터 6월 11일까지 진행됐으며, 각 에이전트는 평균 600번 이상의 리트윗을 수행했다. 최종 평균 팔로워 수는 UR 41.1명, BE 41.6명, GE 44.95명으로, GE가 UR보다 약 10% 더 많은 팔로워를 확보했고 통계적으로 유의미한 차이를 보였다(p=0.0291). BE는 UR과 차이가 없었다. 실험 중반(약 2주 전)에는 세 그룹 모두 평균 23.6~23.8명의 팔로워를 보였으나, 마지막 2주 동안 GE의 성장률이 급격히 상승해 차이가 11배까지 확대되었다.
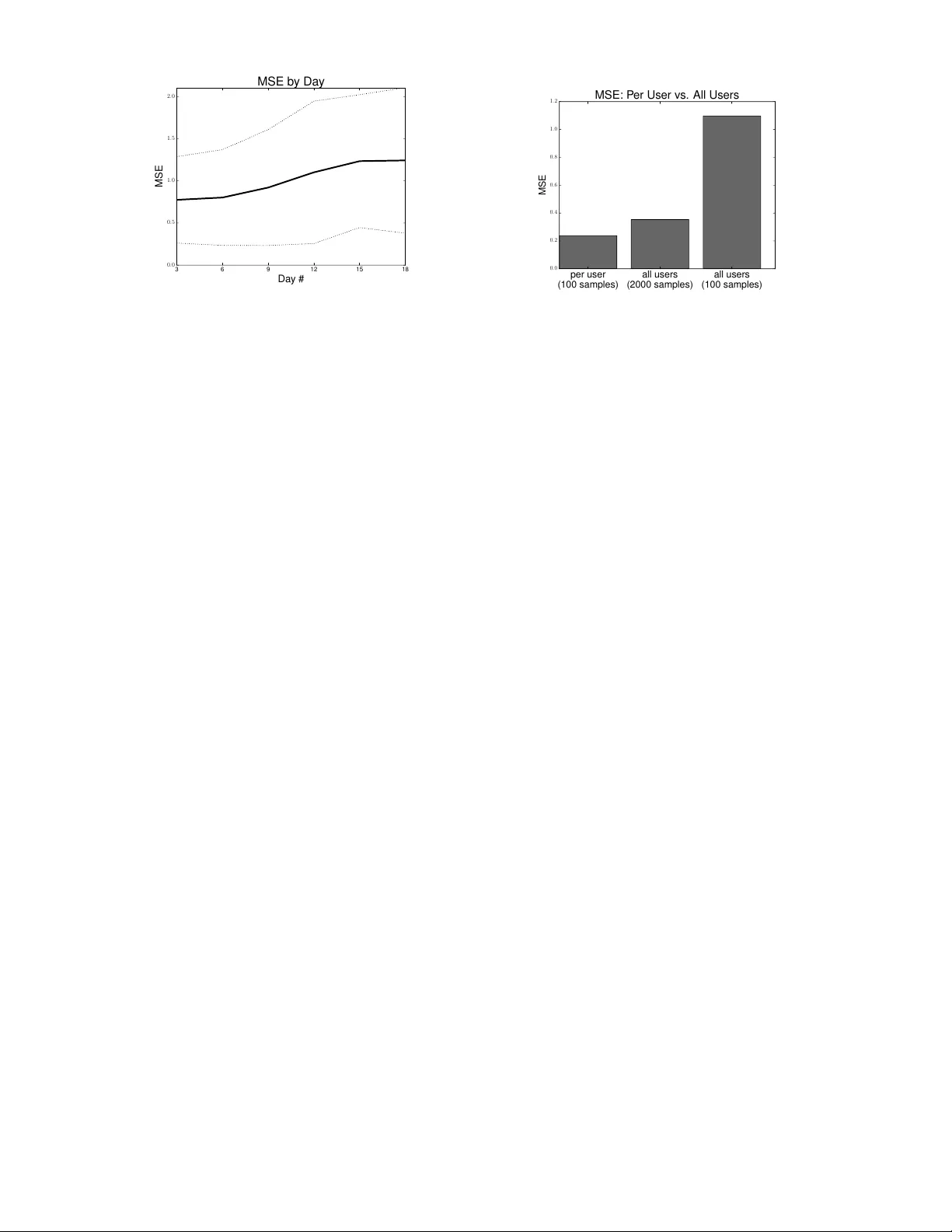
논문은 두 가지 주요 인사이트를 제시한다. 첫째, 보상 신호가 비정상적(non‑stationary)이라는 점이다. 데이터 분석 결과, 시간에 따라 동일한 특징-보상 관계가 변하며, 초기 100개의 샘플로 학습한 SVR 모델을 이후 데이터에 적용하면 MSE가 지속적으로 증가한다. 이는 온라인에서 최신 데이터를 지속적으로 반영하는 학습이 필요함을 의미한다. 둘째, 여러 에이전트의 데이터를 합쳐 학습하면 오히려 예측 정확도가 떨어진다. 개별 에이전트별로 학습된 가중치의 평균값은 수렴하지 않았으며, 표준편차는 시간이 지날수록 증가했다. SVR을 이용해 100개 샘플만 사용한 경우와 2000개 샘플(전체 60명 합산)로 학습한 경우를 비교했을 때, 후자는 MSE가 4배 정도 높았다. 이는 각 사용자의 팔로워 확보 메커니즘이 다르고, 개인 히스토리를 기반으로 학습해야 함을 보여준다.
결론적으로, 트위터와 같은 동적 소셜 플랫폼에서 팔로워를 늘리기 위한 자동화된 전략은 (1) 온라인, 능동적인 학습 프레임워크를 채택하고, (2) 개별 사용자(에이전트)의 데이터를 독립적으로 활용해야 최적의 성과를 얻는다. 또한, 비정상적인 보상 구조를 고려해 탐색‑활용 균형을 적절히 조절하고, 과도한 데이터 집합 통합을 피하는 것이 중요하다. 향후 연구에서는 더 정교한 컨텍스트 특징(예: 트윗 감성, 네트워크 구조)과 강화학습 기법(예: 정책 그라디언트, 딥 밴딧) 등을 도입해 비정상성에 대한 적응성을 높이고, 다른 소셜 미디어에서도 일반화 가능한 모델을 개발하는 방향을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기