시각 인식을 위한 자기정보 기반 신경망 구조 학습
본 논문은 이미 학습된 대규모 멀티라벨 이미지 분류 모델에, 모델 자체의 예측을 이용해 시각적으로 유사한 라벨들을 군집화하고, 각 군집에 특화된 보조 네트워크를 추가함으로써 성능을 크게 향상시키면서 연산량을 3 % 이하로 제한하는 방법을 제안한다.
저자: David Warde-Farley, Andrew Rabinovich, Dragomir Anguelov
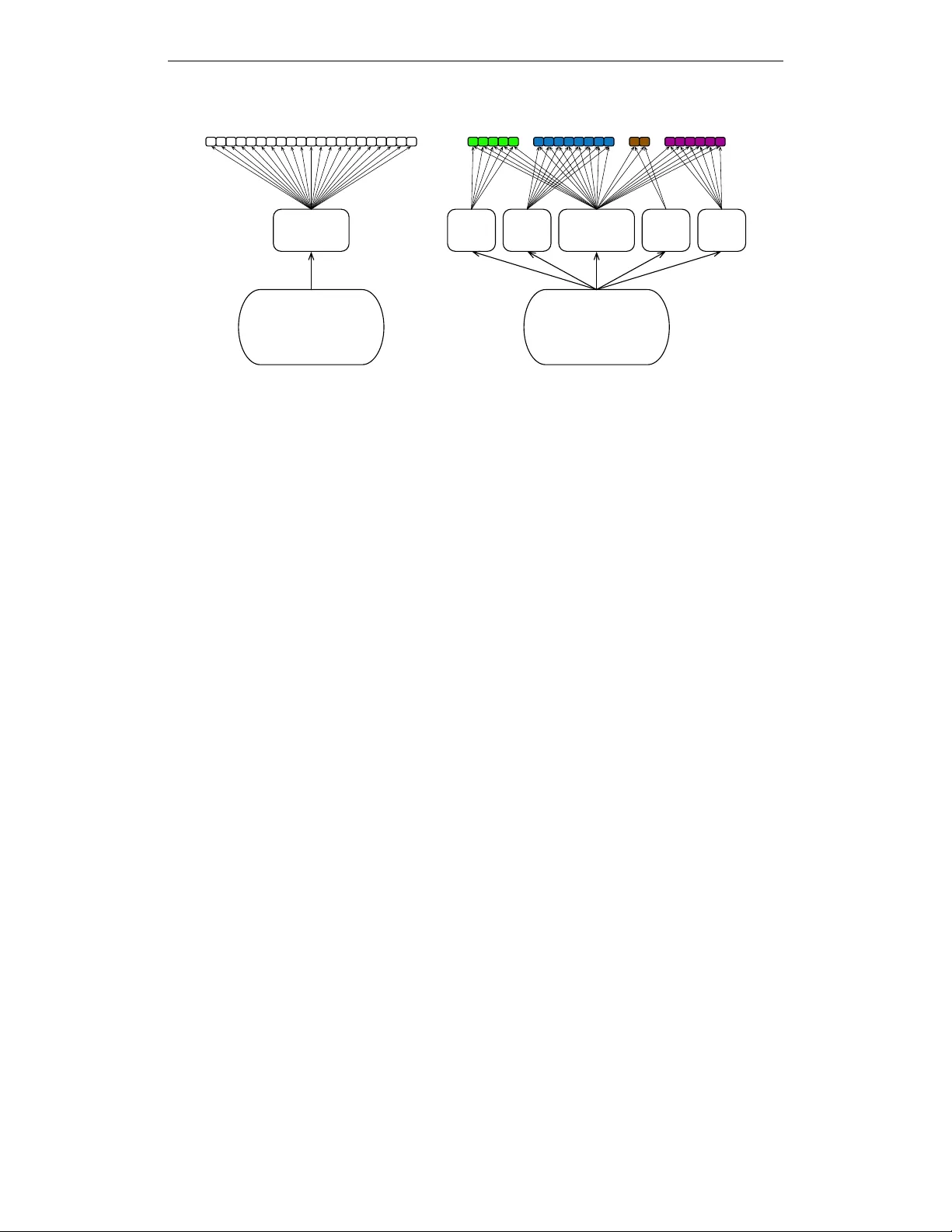
본 논문은 대규모 멀티라벨 이미지 인식 문제에서, 이미 충분히 성능이 검증된 신경망에 추가 용량을 효율적으로 부여하는 방법을 제안한다. 기존의 전통적인 네트워크 확장은 전체 파라미터 수를 급격히 늘리거나, 전체 구조를 재설계해야 하는 경우가 많아 연산 비용이 크게 증가한다. 저자는 이러한 문제를 해결하기 위해, 학습된 모델 자체의 예측 결과를 “시각적 유사성”의 지표로 활용한다.
먼저, 보류 데이터셋에 대해 기본 모델을 실행하고, 각 이미지에 대해 상위 K(=100) 예측 라벨을 추출한다. 이를 바탕으로 라벨 i가 라벨 j와 혼동되는 정도를 나타내는 혼동 행렬 A를 만든다. A를 전치와 곱해 대칭 행렬 B를 얻은 뒤, Ng et al. (2002)의 스펙트럴 클러스터링을 적용해 라벨들을 여러 클러스터로 나눈다. 이때 두 가지 버전을 실험했는데, 하나는 실제 라벨(g_j)과 모델 예측(M_i) 사이의 혼동을 이용하고, 다른 하나는 모델 예측 간의 공동 검출(M_i·M_j)만을 이용한다.
클러스터링 결과는 시각적으로 유사한 라벨들이 같은 그룹에 모이는 것을 확인했으며, 예시로는 항공기 관련 라벨, 음식 관련 라벨, 식물 관련 라벨 등이 각각 하나의 클러스터에 포함되었다. 이렇게 정의된 라벨 그룹마다 “전문가” 서브네트워크를 추가한다. 각 서브네트워크는 두 개의 512‑유닛 ReLU 레이어로 구성되며, 기존 완전연결 스택과 병렬로 연결된다. 서브네트워크의 출력은 해당 클러스터에 속한 라벨 유닛에만 연결되는 가중치 행렬을 통해 최종 로짓을 만든다.
학습 단계에서는 기존 네트워크의 가중치를 고정하고, 새로 삽입된 서브네트워크와 최종 분류기 가중치만을 학습한다. 이는 기존의 풍부한 특징 표현을 그대로 유지하면서, 추가 용량을 라벨별 특화된 학습에 집중하도록 만든다. 필요에 따라 전체 네트워크를 미세조정(fine‑tune)할 수도 있지만, 본 실험에서는 고정 학습만을 사용했다.
실험은 구글 내부 JFT 데이터셋(≈1억 이미지, 17 000 라벨)과 Inception‑style 기본 모델을 기반으로 수행되었다. 기본 모델은 2개의 4096‑유닛 FC 레이어와 로지스틱 출력 유닛을 갖는다. 보조 헤드 수를 6개(혼동 기반)와 13개(공동 검출 기반)로 각각 설정하고, 라벨을 무작위로 재배열한 대조군과 비교했다. 결과는 다음과 같다.
- 기본 모델 mAP@top50: 36.80 % (1.52 B MAC)
- 6개의 혼동 기반 전문가 헤드 추가: 39.41 % (1.56 B MAC, +2.6 % 연산)
- 6개의 무작위 헤드: 32.97 % (동일 연산량)
- 13개의 공동 검출 기반 헤드: 38.07 % (1.60 B MAC)
- 13개의 무작위 헤드: 32.13 %
즉, 라벨 클러스터링을 통해 얻은 전문가 구조가 무작위 구조보다 현저히 높은 성능을 보이며, 특히 실제 라벨 정보를 이용한 혼동 기반 클러스터링이 가장 큰 이득을 제공한다. 또한 연산량 증가는 3 % 미만으로, 실시간 서비스에 적용 가능한 수준이다.
추가 실험으로, JFT 모델을 ImageNet 1 000‑class 테스트셋에 매핑 가능한 660 라벨에 대해 평가했으며, 초기 결과는 긍정적이지만 직접적인 비교는 향후 작업으로 남겨두었다.
결론적으로, 이 방법은 (1) 모델 자체의 소프트 예측을 활용해 라벨 간 시각적 관계를 자동으로 추출, (2) 기존 네트워크 구조를 크게 변경하지 않고도 전문가‑전문가 서브네트워크를 삽입해 성능을 향상, (3) 연산 비용을 최소화하면서 조건부 계산(conditional computation) 개념에 한 걸음 다가가는 장점을 가진다. 향후 연구에서는 클러스터별 용량 할당 최적화, 컨볼루션 레이어 수준의 전문가 삽입, 다중 단계 클러스터링을 통한 반복적인 구조 확장 등을 탐색하여 더욱 높은 효율성과 정확도를 달성하고자 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기