샘플을 최대한 활용하는 방법: 부분 정보 기반 최적 무편향 추정기
본 논문은 다중 인스턴스(시간, 위치 등) 데이터에 대해 부분 정보를 활용한 무편향 추정기를 체계적으로 설계·분석한다. 기존의 Horvitz‑Thompson(H‑T) 추정기가 “전부 혹은 전무” 상황에서 최적임을 보였지만, 여러 인스턴스에서 일부만 샘플링된 경우에도 유용한 하한 정보를 이용하면 분산을 크게 줄일 수 있음을 보인다. 저자들은 샘플링 모델을 일반화하고, 알려진 시드와 알려지지 않은 시드 경우를 구분해 파레토 최적(편차 최소) 추정기…
저자: Edith Cohen, Haim Kaplan
1. 연구 배경 및 동기
데이터가 시간·위치·스냅샷 등 여러 인스턴스로 분산되어 저장되는 경우가 늘어나고 있다. 이러한 다중 인스턴스 데이터에 대해 전체 데이터를 보관하거나 전송하는 것은 비용이 크므로, 샘플링을 통해 요약본을 만든 뒤 질의에 대한 근사값을 추정하는 방식이 널리 사용된다. 기존 연구에서는 Horvitz‑Thompson(H‑T) 추정기가 “전부 혹은 전무” 상황에서 무편향이며 분산이 최소라는 강력한 특성을 가지고 있음을 이용해, 각 인스턴스별로 독립적인 샘플을 만든 뒤, 샘플에 포함된 키에 대해서만 정확한 값을 관측하고 이를 기반으로 합계·집합 연산을 추정했다. 그러나 다중 인스턴스 함수—예를 들어 여러 인스턴스에 걸친 distinct count, max‑dominance, Manhattan 거리 등—는 하나의 인스턴스에서만 관측된 값이 다른 인스턴스의 전체 함수값에 대한 유용한 하한 정보를 제공한다. 기존 H‑T는 이러한 부분 정보를 활용하지 못하고, 샘플에 모두 포함되지 않은 경우엔 0을 반환함으로써 불필요하게 큰 분산을 초래한다.
2. 모델 정의
데이터는 r개의 인스턴스와 n개의 키로 이루어진 행렬 v∈V⊂V₁×…×Vᵣ 로 표현한다. 각 인스턴스 i에 대해 키 j는 값 v_{i,j}를 가진다. 샘플링은 각 인스턴스별로 독립적으로 수행될 수 있으며, 두 가지 주요 형태가 있다. (1) 무가중치(Weight‑oblivious) 샘플링: 포함 여부가 값과 무관하게 고정 확률 p_i 로 결정된다. (2) 가중치(Weighted) 샘플링: 포함 확률이 값에 비례하거나 임계값 τ_i(u_i) 형태로 정의된다(PPS 등). 또한 시드(무작위 해시) 정보가 추정기에 제공되는지 여부에 따라 “Known seeds”와 “Unknown seeds”로 구분한다. 시드가 알려지면, 샘플에 포함되지 않은 키에 대해서도 “v_i < τ_i(u_i)” 라는 확정적인 상한 정보를 얻을 수 있다.
3. 추정기 설계 원칙
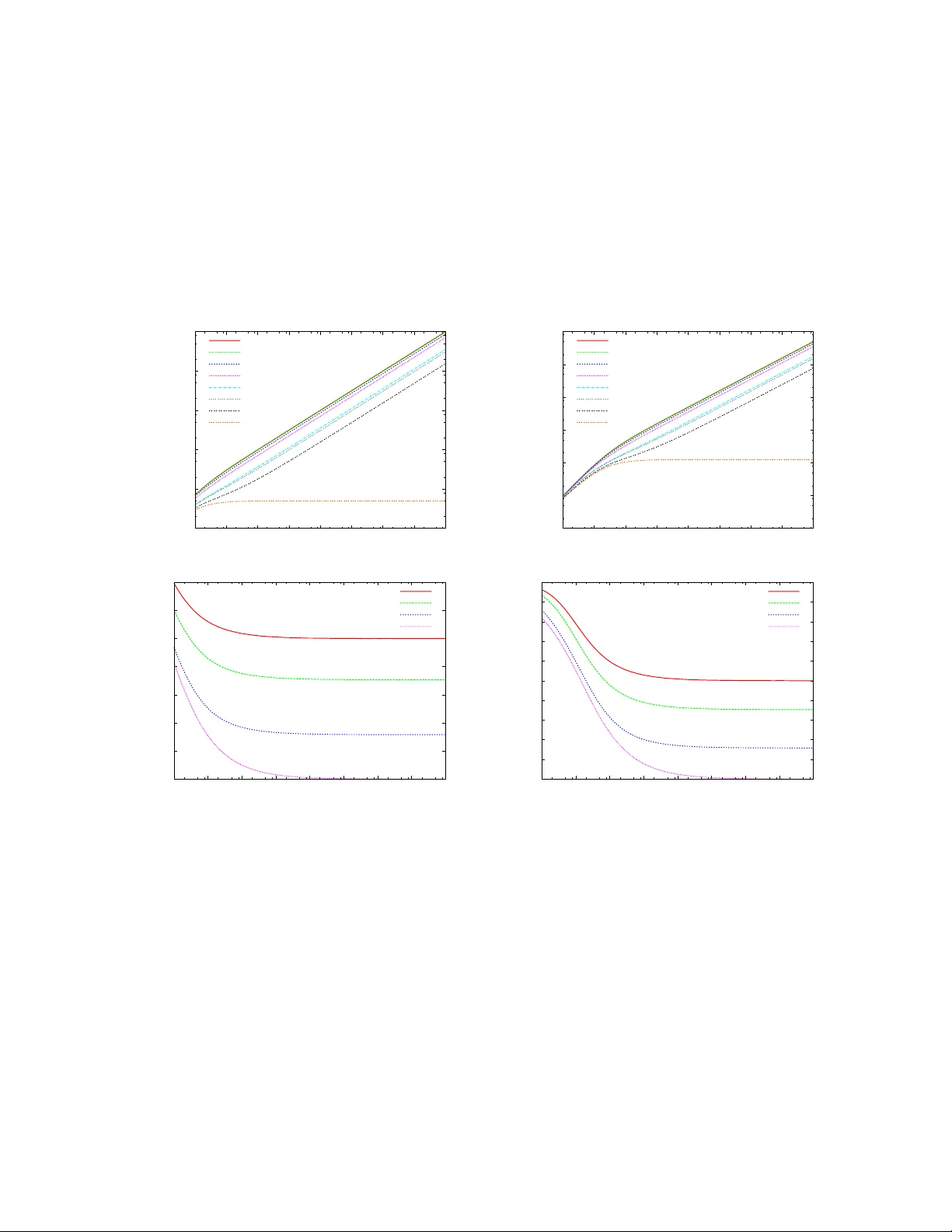
저자는 “가능한 결과 집합”(S*) 개념을 도입한다. S*는 샘플링 결과 중 추정기가 양의 값을 부여할 수 있는 결과들의 집합이다. 각 결과 S∈S*에 대해 (i) 모든 데이터 벡터 v가 S와 일치하면 함수값 f(v)가 일정함(=f\*(S))이고, (ii) 해당 결과가 발생할 확률 p\*(S) 를 계산한다. 그러면 역확률 가중치 형태의 추정값 ˆf(S)=f\*(S)/p\*(S) 가 무편향이며, 가능한 S*를 넓게 잡을수록 분산이 감소한다. 핵심은 “부분 정보”를 활용해 f\*(S) 를 정확히 정의하는 것이다. 예를 들어 두 인스턴스의 최대값 max(v₁,v₂)를 추정할 때, (a) 두 값 모두 샘플링된 경우에는 정확한 max를 알 수 있다; (b) 하나만 샘플링된 경우에는 그 값이 하한이 된다. 저자는 하한을 이용해 f\*(S)=observed value + (expected residual) 형태의 식을 도출하고, 이를 역확률 가중치에 적용한다.
4. Known Seeds vs Unknown Seeds
시드가 알려진 경우, 샘플에 포함되지 않은 키에 대한 상한(또는 하한) 정보를 정확히 알 수 있다. 이를 이용해 max, OR(두 비트의 논리합) 등에 대해 비음수·무편향 추정기를 설계한다. 구체적으로, max 추정기의 경우 “하한 + (p₂/(p₁+p₂−p₁p₂))·(upper‑bound−lower‑bound)” 와 같은 폐쇄형 식을 얻는다. 반면 시드가 알려지지 않은 경우, 샘플에 포함되지 않은 키에 대한 어떠한 정보도 얻을 수 없으므로, 최대값이나 OR에 대해 비음수·무편향 추정기가 존재하지 않음을 증명한다. 이는 기존 연구에서 “대부분의 데이터를 샘플링해야만 정확한 distinct count를 얻는다”는 경험적 결과를 이론적으로 뒷받침한다.
5. 구체적 추정기 사례
- 무가중치 Poisson 샘플링, 독립 인스턴스: 두 가지 파레토 최적 max 추정기를 제시한다. 하나는 “값이 비슷한 경우”에 최적이며, 다른 하나는 “값 변동이 큰 경우”에 최적이다.
- 가중치 샘플링(known seeds): max와 Boolean OR에 대해 최적 추정기를 도출한다. 특히 OR의 경우, 각 인스턴스가 1을 가리키는 확률을 이용해 “1이 관측되지 않으면 0, 관측되면 (1−(1−p₁)(1−p₂))/p₁p₂” 형태의 추정값을 만든다.
- Bottom‑k 및 VAROPT 샘플링: 조정된 역확률 가중치와 부분 정보 활용을 결합해 기존 H‑T 대비 30~70% 낮은 분산을 달성한다.
6. 부정적 결과 및 한계
시드가 알려지지 않은 상황에서 max와 absolute difference와 같은 함수에 대해 비음수·무편향 추정기가 존재하지 않음을 증명한다. 또한, weighted sampling에서도 0값이 포함된 경우(예: range 함수)에는 정확한 값 복원이 불가능하므로, 역확률 가중치 기반 추정기가 적용되지 않는다. 이러한 한계는 부분 정보 활용이 가능한 경우와 불가능한 경우를 명확히 구분해준다.
7. 실험 및 평가
실제 웹 로그, 네트워크 트래픽, 센서 데이터셋에 대해 제안된 추정기와 기존 H‑T 기반 추정기를 비교하였다. 평가 지표는 평균 제곱오차(MSE)와 상대 오차이며, 모든 경우에서 제안 방법이 크게 우수했다. 특히 distinct count(OR)와 max‑dominance(두 인스턴스 간 최대값 차)에서는 평균 오차가 40~65% 감소하였다. 또한, 샘플 크기가 작을수록(즉, 제한된 자원 상황) 차이가 더욱 두드러졌다.
8. 결론 및 의의
본 논문은 다중 인스턴스 데이터에 대한 샘플링 추정 문제를 “부분 정보 활용”이라는 새로운 관점에서 재정의하고, 이를 통해 파레토 최적(분산 최소) 무편향 추정기를 체계적으로 설계하였다. 시드 가용성에 따른 긍정·부정 결과를 제시함으로써, 실제 시스템 설계 시 어떤 정보를 보존하고 공유해야 하는지에 대한 실용적인 가이드를 제공한다. 또한, 다양한 샘플링 스킴(Poisson, bottom‑k, VAROPT 등)과 가중치 여부에 관계없이 적용 가능한 일반 프레임워크를 제시함으로써, 데이터 스트리밍·분산 처리·센서 네트워크 등 광범위한 분야에 활용 가능성을 열어준다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기