RNA 발현 순위 기반 표현형 예측 방법
본 논문은 유전자 발현값의 절대 크기가 아니라 유전자 간 순위 관계만을 이용해 이진 표현형을 구분하는 ‘랭크 디스크리미넌트’ 모델을 제안한다. 가장 단순한 TSP(Top‑Scoring Pair)부터 다수의 쌍을 투표하는 KTSP, 두 유전자 집합의 중앙값을 비교하는 TSM까지 다양한 변형을 제시하고, 컨텍스트(사용 유전자 집합)를 데이터‑드리븐하게 선택하는 절차를 설계한다. 21개의 실제 마이크로어레이 데이터셋에 대해 10‑fold 교차검증을 …
저자: Bahman Afsari, Ulisses M. Braga-Neto, Donald Geman
1. 서론
본 논문은 고차원 유전자 발현 데이터에서 표현형(예: 암 vs 정상, 암 아형) 예측을 위해 복잡한 모델 대신 순위 기반 단순 분류기를 제안한다. 기존의 SVM·신경망·부스팅 등은 수백·수천 개의 파라미터를 학습해 과적합 위험이 크고, 결과 해석이 어려워 임상 적용에 한계가 있다. 저자들은 “두 유전자 간 순위 비교”라는 가장 기본적인 형태를 확장해, 여러 쌍을 결합하거나 유전자 집합의 중앙값을 비교하는 방법을 고안한다.
2. 관련 연구
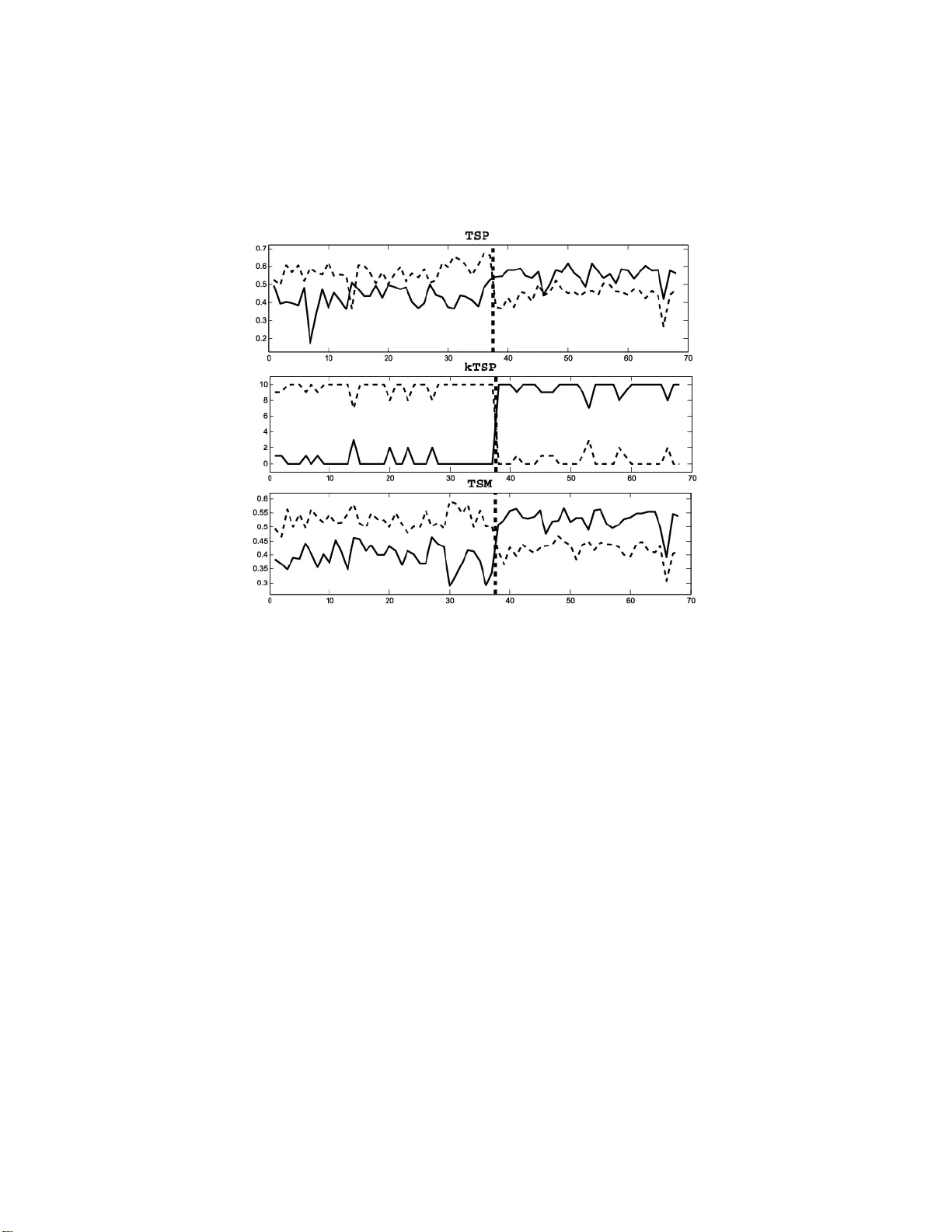
TSP(Top‑Scoring Pair)는 2004년 Geman 등에 의해 제안된 최초의 순위 기반 이진 분류기로, 두 유전자의 발현 순서가 클래스마다 반대인 경우를 찾아낸다. 이후 KTSP, 다중 쌍 투표, 비율 기반 방법 등이 제안됐지만, 대부분 파라미터(K) 선택에 교차검증을 사용해 과적합 위험이 있었다. 또한, 순위 통계 자체를 활용한 연구는 제한적이었다.
3. 일반 프레임워크(RIC)
저자들은 g(X;Θ)라는 순위 판별함수를 정의하고, Θ⊂{1,…,d}를 컨텍스트라 부른다. g는 Θ에 포함된 유전자들의 순위 관계를 이용해 실수값을 반환한다. f(X)=I(g>0)로 이진 결정을 내린다. 컨텍스트 선택은 다음 두 단계로 이루어진다. (1) 고정된 Θ에 대해 클래스별 평균 g값 차이 δ̂(Θ)=E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기