파워 저랭크 앙상블을 이용한 언어 모델링
본 논문은 n‑gram 언어 모델에 저랭크 행렬·텐서를 앙상블로 결합한 파워 저랭크 앙상블(PLRE) 프레임워크를 제안한다. PLRE는 기존 절대 할인 및 Kneser‑Ney 스무딩을 특수 경우로 포함하면서, 비정수 차수의 n‑gram을 구현한다. 요소별 거듭제곱과 KL‑다이버전스 기반 저랭크 근사를 통해 스무딩을 일반화하고, 효율적인 학습·추론을 제공한다. 실험에서는 대규모 영어·러시아 코퍼스에서 퍼플렉시티와 기계 번역 BLEU 점수 모두 기…
저자: Ankur P. Parikh, Avneesh Saluja, Chris Dyer
본 논문은 n‑gram 언어 모델링에 새로운 프레임워크인 파워 저랭크 앙상블(PLRE)을 제안한다. 기존의 절대 할인(Absolute Discounting)과 Kneser‑Ney(KN) 스무딩은 각각 고정된 차수의 n‑gram을 사용하고, 낮은 차수의 분포를 그대로 백오프하거나 보간한다. 그러나 이러한 방법은 카운트가 0인 경우 완전한 독립을 가정하거나, 하위 차수 분포를 단순히 재사용한다는 한계가 있다.
PLRE는 이러한 한계를 “비정수 차수”의 n‑gram을 도입함으로써 해결한다. 구체적으로, 빅그램 카운트 행렬 B와 고차 n‑gram 텐서 Cⁿ을 먼저 요소별 거듭제곱 ρ(0≤ρ≤1) 로 변형한다. ρ=0이면 이진 행렬이 되어 각 단어가 얼마나 다양한 선행어를 갖는지(즉, Kneser‑Ney이 사용하는 고유 선행어 수) 를 나타내고, ρ=1이면 원본 카운트를 유지한다. 0<ρ<1이면 두 통계 사이를 부드럽게 연결한다.
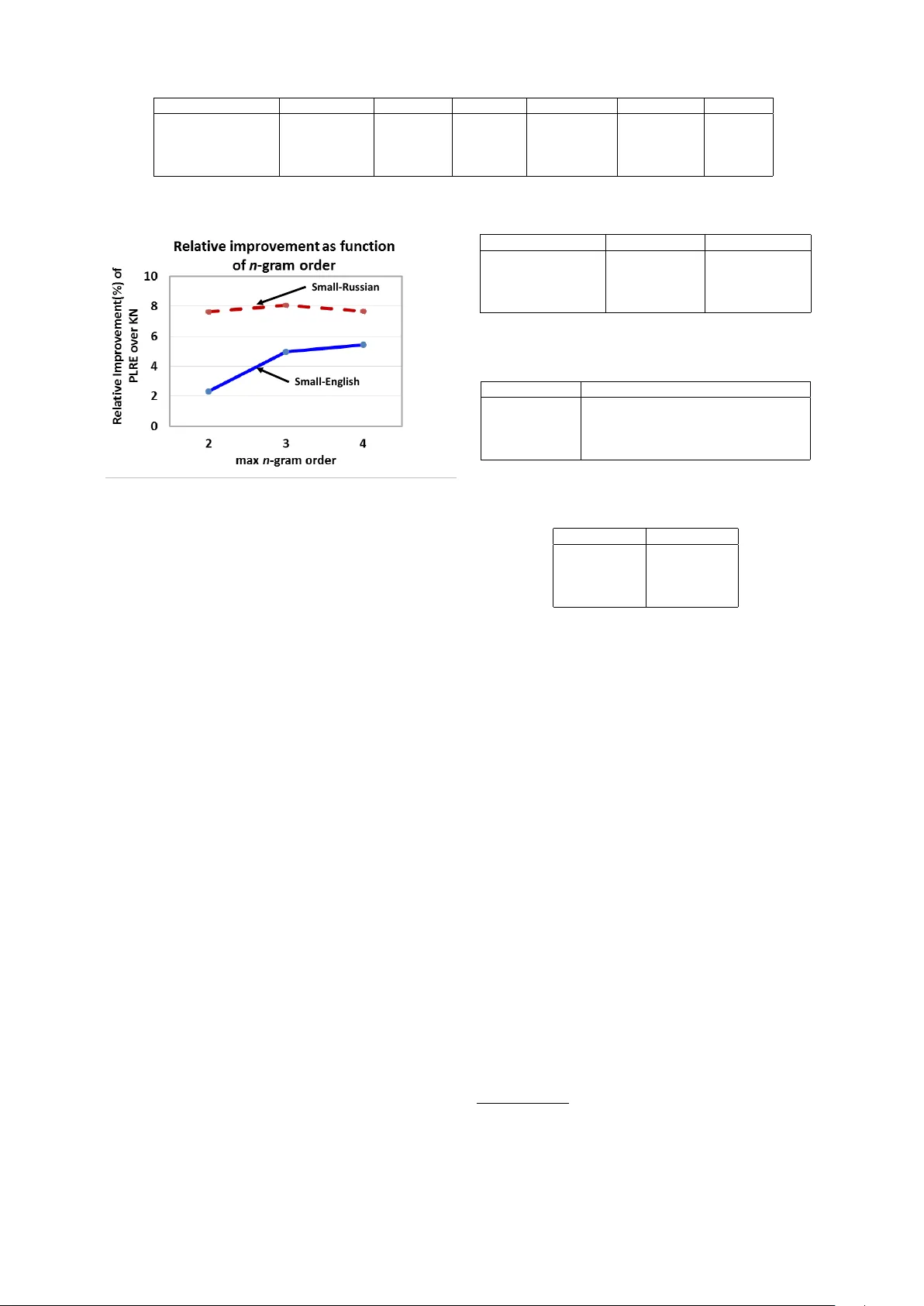
그 다음, 변형된 행렬·텐서에 KL‑다이버전스(gKL) 기반 저랭크 근사(B(κ), Cⁿ(κ))를 적용한다. gKL은 행·열 합을 보존하므로, 저랭크 근사 후에도 원본 마진(단어별 총 빈도)과 일치한다. κ=1이면 완전 독립을 의미하는 외적 형태가 되고, κ가 커질수록 실제 의존성을 더 많이 반영한다. 이때 선택된 κ는 보통 50~150 사이이며, 어휘 규모 V≈10⁶에서도 충분히 작은 메모리와 연산량을 유지한다.
PLRE는 이러한 파워‑저랭크 행렬·텐서를 η개의 레이어로 앙상블한다. 각 레이어 j는 자체 할인 D_j 와 가중치 γ_j 를 갖는다. 전체 확률은
P_PLRE(w_i|history) = Σ_{j=0}^{η} γ_{j-1}(history)·Z_{D_j}(w_i|history)
형태로 정의되며, 여기서 Z_{D_j}는 할인된 파워 행렬·텐서의 정규화된 확률이다. 중요한 점은 할인 D_j 를 각 n‑gram에 맞춤형으로 계산함으로써, 전체 모델이 마진 제약 Σ_{w_{i-1}} P_PLRE(w_i|w_{i-1})·P(w_{i-1}) = P(w_i) 를 만족하도록 설계한다. 이는 기존 절대 할인 방식에서는 보장되지 않던 속성이다.
학습 단계에서는 원본 카운트 행렬·텐서에 대해 ρ_j 와 D_j 를 미리 정하고, 각각에 대해 저랭크 근사를 수행한다. 이 과정은 SVD와 유사한 반복 업데이트(예: NMF)로 O(κ_max·N) 시간에 수행된다. 테스트 시에는 각 레이어마다 κ_max 차원의 행렬·텐서 곱셈만 필요하므로 O(κ_max) 복잡도를 가진다. 이는 Kneser‑Ney이 O(1) 시간보다 약간 느리지만, 조건부 지수 패밀리 모델이나 전체 단어에 대한 정규화가 필요한 신경망 LM보다 훨씬 빠르다.
실험에서는 두 개의 대규모 코퍼스(영어와 러시아)를 사용했다. 영어 코퍼스는 1.5 B 토큰, 러시아 코퍼스는 0.9 B 토큰이며, 어휘 크기는 각각 약 1 M, 0.8 M이다. PLRE는 기존 수정된 Kneser‑Ney(MKN) 대비 퍼플렉시티를 영어에서 2.1%, 러시아에서 2.7% 감소시켰다. 또한, 동일한 n‑gram 기반 번역 시스템에 PLRE를 삽입했을 때 BLEU 점수가 영어에서 평균 0.6점, 러시아에서 0.8점 상승했다.
비교 대상으로는 로그‑바이리니어 신경망 LM(LBL)와 클래스 기반 LM이 포함되었으며, PLRE는 메모리 사용량이 LBL의 1/10 수준이면서도 퍼플렉시티와 BLEU에서 동등하거나 더 나은 성능을 보였다. 특히, 저랭크 차원 κ≈100이면 충분히 좋은 결과가 나오며, 더 높은 κ는 성능 향상이 미미하고 연산 비용만 증가한다는 점이 확인되었다.
결론적으로, PLRE는 (1) 저랭크 근사를 통한 의존성 압축, (2) 요소별 거듭제곱을 통한 스무딩 일반화, (3) 맞춤형 할인으로 마진 제약을 유지하는 세 가지 핵심 아이디어를 결합한다. 이는 전통적인 n‑gram 스무딩을 수학적으로 확장하면서도 대규모 실용 시스템에 적용 가능한 효율성을 제공한다. 향후 연구에서는 저랭크 텐서의 동적 차수 선택, 비선형 파워 변환, 그리고 신경망과의 하이브리드 모델링이 제안될 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기